Building an Invisible Daemon: Architecture Patterns for Local Developer Tools

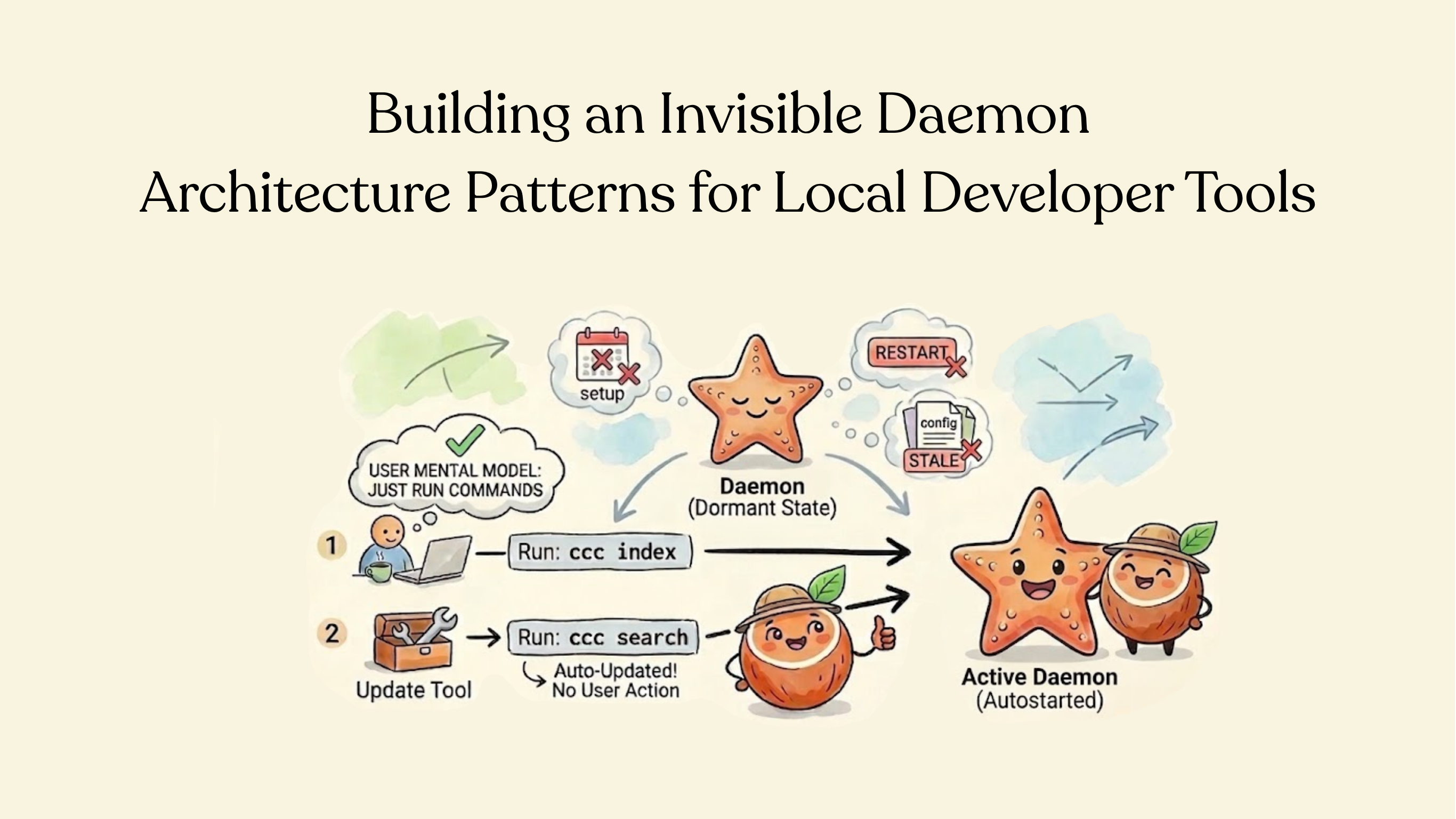
Many developer tools need a long-running local process — an LSP server, a file watcher, an indexing service. The challenge isn't just building the daemon. It's making it invisible: something that starts when needed, upgrades when the tool upgrades, reloads config when settings change, and shuts down cleanly.
We learned this building cocoindex-code, an embedded AST-based semantic code search tool that speeds up and improve the quality for coding agents. It started as a monolithic process that loaded an ML model, indexed a codebase, and served searches — all per session. We moved the heavy lifting to a persistent daemon, with a CLI (ccc) and a lightweight MCP client as thin frontends. This also unlocked a benefit beyond performance: humans can call ccc search "auth logic" directly from the terminal, piped into other tools.
The journey from "obvious daemon" to production-ready was full of design decisions — and the best ones were usually about what to remove. Here's the user journey:
ccc init # one-time setup: creates settings files (no daemon)
ccc index # build the search index (daemon auto-starts here)
ccc search "auth logic" # semantic search (daemon handles it)
ccc search --refresh "auth" # re-index then search (two daemon requests)
ccc init is purely local — it creates configuration files and a .gitignore entry. Every other command talks to the daemon. But the user never starts, stops, or restarts the daemon manually. It just works.
The initial daemon was largely built by Claude Code — persistent connections, async handler loops, multi-step shutdown. It worked, but it was complex in ways we didn't appreciate until we looked closely. The simplifications came from stepping back and questioning the design rather than fixing individual bugs.
This post covers the patterns we landed on, in the hope that they're useful to anyone building a local daemon for developer tools.
The Invisible Daemon
The most important design constraint: users should never think about the daemon. No ccc daemon start in the setup guide. No "please restart the daemon after upgrading." No stale config surprises.
Start on First Use
The first time a user runs ccc index or ccc search, the client tries to connect to the daemon's Unix socket. If it fails, it starts the daemon as a detached background process and waits for the socket to appear.
This logic is built into the lowest-level connection function, not into a separate "ensure daemon" step:
_daemon_ensured = False
def _connect_and_handshake() -> Connection:
global _daemon_ensured
if _daemon_ensured:
return _raw_connect_and_handshake()
# First connection — auto-start/restart as needed.
try:
conn = _raw_connect_and_handshake()
_daemon_ensured = True
return conn
except DaemonVersionError:
stop_daemon()
except (ConnectionRefusedError, OSError):
pass
start_daemon()
_wait_for_daemon()
# ... retry and return
A module-level _daemon_ensured flag means the first call in a CLI session pays the startup cost. Every subsequent call connects directly. No separate "ensure" step, no throwaway probe connection, no wrapper function.
Transparent Upgrades via Version Handshake
When a user runs pipx upgrade cocoindex-code, the next CLI command should just work — using the new version. No manual restart.
Every connection starts with a version handshake. The client sends its version; the daemon responds with its version:
# In the client
conn.send_bytes(encode_request(HandshakeRequest(version=__version__)))
resp = decode_response(conn.recv_bytes())
if not resp.ok or _needs_restart(resp):
raise DaemonVersionError(resp)
On the first call (_daemon_ensured = False), a version mismatch triggers a restart — stop the old daemon, start a new one. On subsequent calls, a mismatch raises an error (the daemon was replaced mid-session, which is unusual and worth surfacing).
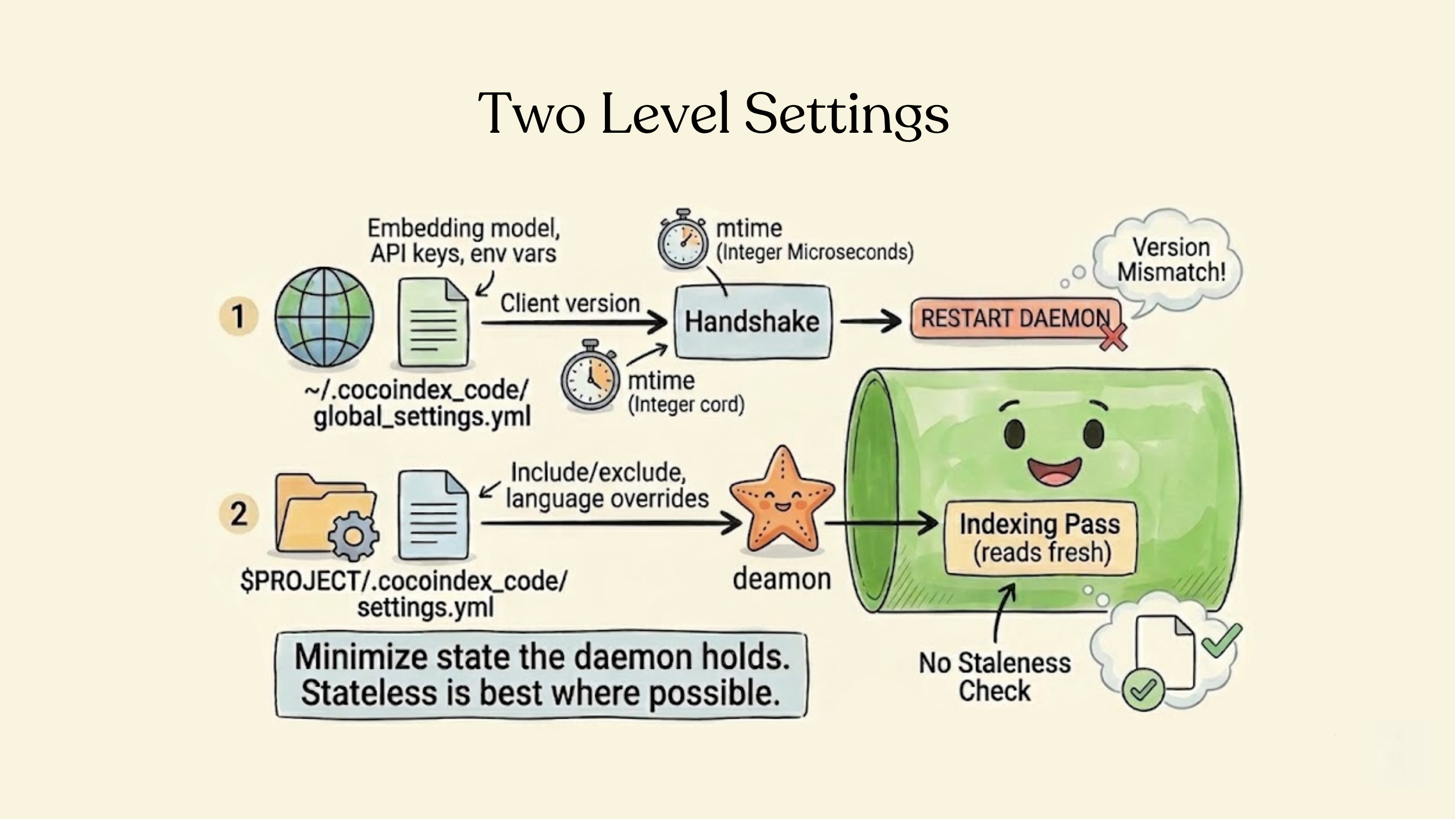
Two-Level Settings, Two Strategies
We have two levels of configuration:
Global settings (~/.cocoindex_code/global_settings.yml) — embedding model, API keys, environment variables. These affect daemon-wide state: the ML model is loaded once at startup, environment variables are set once. When these change, the daemon must restart.
Project settings ($PROJECT/.cocoindex_code/settings.yml) — include/exclude patterns, language overrides. These only affect per-operation behavior: which files to index, how to parse them.
Both files are created automatically by ccc init with sensible defaults — users only edit them if they need to customize.
For global settings, the daemon records the file's mtime (as integer microseconds) at startup and reports it in the handshake response. The client compares it with the current mtime. Different? Restart.
For project settings, we do nothing special. Each indexing pass reads the settings file fresh from disk. No staleness check, no restart, no cache invalidation.
The principle: minimize what the daemon holds as state. Global settings are unavoidable state (the loaded model), so we detect staleness. Project settings can be stateless, so we make them stateless.
Per-Request Connections
This was the single biggest simplification, and it came from a bug.
The Persistent Connection Attempt
Our first design followed the obvious pattern: the client connects, handshakes, then sends multiple requests on the same connection. The daemon handler loops, reading and dispatching requests until the client disconnects:
# The original handler — persistent connection with recv loop
async def handle_connection(conn, registry, ...):
loop = asyncio.get_event_loop()
def _recv():
while not shutdown_event.is_set():
if conn.poll(0.5): # wake every 0.5s to check shutdown
return conn.recv_bytes()
raise EOFError("shutdown")
try:
while not shutdown_event.is_set():
data = await loop.run_in_executor(None, _recv)
req = decode_request(data)
# ... handshake, dispatch, respond ...
except (EOFError, OSError, asyncio.CancelledError):
pass
finally:
conn.close()
This handler had to deal with a lot:
- A
_recvhelper that polls every 0.5 seconds, checking athreading.Eventfor shutdown - An executor thread per connection, blocked in
conn.poll() - A
whileloop waiting for the next request that may never come - Cancellation handling for shutdown
Two problems emerged from this design:
Leaked connections. CLI commands didn't always close their connections. Each leaked connection meant a handler task stuck in _recv, waiting forever. We added __enter__/__exit__, with blocks, .close() calls — but it was whack-a-mole.
Shutdown was broken. Our test suite took 15 seconds per test teardown. The stop_daemon() function had a 5-step escalation — StopRequest, wait 5 seconds, SIGTERM, wait 2 seconds, SIGKILL — and always fell through to SIGKILL. Three bugs were stacked on top of each other:
asyncio.Event.is_set()called from executor threads — butasyncio.Eventis not thread-safe. The_recvthreads never saw the shutdown signal.asyncio.run()cleanup hanging — it callsshutdown_default_executor(wait=True), which waits for the_recvthreads that would never exit (because of bug #1).os.kill(pid, 0)returning True for zombie processes — so the client kept waiting for a process that had already exited.
We fixed each bug individually. But the real insight came when we stepped back: all three bugs existed because of persistent connections. Persistent connections required idle handler tasks. Idle tasks required a shutdown signal. The signal had to cross async-to-thread boundaries. And every layer of that chain had a bug.
The Per-Request Model
Instead of fixing the plumbing, we removed the need for it. What if each request just opens a fresh connection?
connect → handshake → one request → response(s) → close
The handler becomes straight-line code:
# The current handler — per-request, no loop, no polling
async def handle_connection(conn, registry, ...):
loop = asyncio.get_event_loop()
try:
# 1. Handshake
data = await loop.run_in_executor(None, conn.recv_bytes)
req = decode_request(data)
# ... validate handshake, send response ...
# 2. Single request
data = await loop.run_in_executor(None, conn.recv_bytes)
req = decode_request(data)
result = await _dispatch(req, registry, ...)
# 3. Send response(s) and done
if isinstance(result, AsyncIterator):
async for resp in result:
conn.send_bytes(encode_response(resp))
else:
conn.send_bytes(encode_response(result))
except (EOFError, OSError, asyncio.CancelledError):
pass
finally:
conn.close()
Read two messages. Respond. Close. That's it.
What It Eliminated
The diff wasn't just shorter — entire concepts disappeared:
- The
_recvpolling loop (0.5-second wakeups checkingshutdown_event) — gone shutdown_event(threading.Event) — gone entirely- The
DaemonClientclass,__enter__/__exit__,.close()— gone with client:blocks in every CLI command — gone- Connection leak bugs — impossible by construction
- All three shutdown bugs — gone (no idle handler tasks means nothing to signal)
The client module went from a stateful class to module-level functions:
# No class, no state, no close() to forget
def index(project_root, on_progress=None, on_waiting=None):
conn = _connect_and_handshake()
try:
conn.send_bytes(encode_request(IndexRequest(project_root=project_root)))
# ... read streaming responses ...
finally:
conn.close()
Compound Operations
What about operations that need multiple requests? ccc search --refresh needs to index first, then search. Simple — two connections:
def search_cmd(project_root, refresh=False):
if refresh:
client.index(project_root) # connection 1
client.search(project_root, query) # connection 2
MCP background indexing? Just call client.index() from a thread — it opens its own connection. No shared state, no "dedicated connection" comments, no connection isolation bugs.
The overhead is negligible: Unix socket setup is ~0.1ms, the handshake is a tiny msgspec payload, and CLI commands are human-initiated. Streaming responses (like indexing progress) still work — the connection lives for one request's full response stream, it just doesn't linger afterwards.
Shutdown: Close Resources, Don't Signal Threads
Per-request connections solved the hardest shutdown problems (no idle tasks to signal). The remaining lesson: design shutdown around closing resources, not coordinating threads.
The accept loop runs in a background thread, blocking on listener.accept(). To stop it, we don't set a flag and hope the thread notices — we close the listener. accept() raises OSError, the thread exits immediately:
def _accept_loop():
while True:
try:
conn = listener.accept()
loop.call_soon_threadsafe(_spawn_handler, conn)
except OSError:
break # listener was closed — exit
The same principle applies to the full shutdown sequence:
try:
loop.run_forever()
finally:
listener.close() # 1. stop accepting
for task in tasks: task.cancel() # 2. cancel handlers
if tasks:
loop.run_until_complete(asyncio.gather(*tasks, return_exceptions=True))
registry.close_all() # 3. release resources
loop.close()
# 4. remove socket and PID file ...
os._exit(0) # 5. skip slow Python teardown
A few details worth noting:
PID file as the exit signal. The client needs to know when the daemon has finished cleaning up. We tried os.kill(pid, 0), but it returns True for zombie processes (they're still in the process table). Instead, the daemon removes its PID file as the last cleanup step, and the client polls for its absence.
os._exit(0) for fast teardown. Python's normal exit runs atexit handlers, GC finalizers, and module teardown — which takes seconds when torch is loaded. Since we've already cleaned up explicitly, os._exit(0) is safe and fast. (One caveat: it terminates the entire process, so we guard it with threading.current_thread() is threading.main_thread() for tests that run the daemon in a thread.)
Event loop on the main thread. The accept loop runs in a background thread, but the asyncio event loop stays on the main thread. This is required for loop.add_signal_handler() to work — SIGTERM and SIGINT call loop.stop(), which causes run_forever() to return into the finally block above.
The Result
per-request connections
CLI / MCP ──────────────────────────────► Daemon
(thin) connect → handshake → (persistent)
request → response → - event loop (main thread)
close - accept loop (background thread)
- project registry
- ML model (loaded once)
Before and after:
| Before | After | |
|---|---|---|
| Connection handler | ~70 lines, recv loop, polling, shutdown event | ~40 lines, straight-line read-respond-close |
| Client | DaemonClient class, __enter__/__exit__, .close() | Module-level functions, no state |
| Shutdown concepts | threading.Event, executor polling, 5-step escalation | listener.close(), loop.stop(), os._exit(0) |
| Daemon stop time | ~15 seconds (fell through to SIGKILL) | <1 second |
Patterns for Local Daemon Architecture
If you're building a local daemon for developer tools, here's what we'd suggest:
Make the daemon invisible. Auto-start on first use. Auto-restart on version mismatch. Auto-reload config where possible. The user's mental model should be "I run CLI commands" — the daemon is an implementation detail.
Prefer stateless IPC. Per-request connections can't leak by construction. The overhead of Unix socket setup (~0.1ms) is negligible for developer tools. The handshake on every connection catches staleness faster.
Categorize your state. What must live in the daemon (loaded ML model, open databases) vs what can be read fresh (config files, file lists)? Only restart for the former. The less state the daemon holds, the fewer staleness bugs you'll have.
Design shutdown around resource closure, not signaling. Close the listener to interrupt accept(). Remove the PID file to signal completion. Don't poll threads to check if they've noticed an event — close the thing they're waiting on.
When debugging gets complex, question the design. We fixed three stacked shutdown bugs with careful threading, event types, and process liveness checks. Then we removed persistent connections and all three bugs disappeared. The debugging was correct. The design was wrong.
Support the Project
If you find this article helpful, please check out cocoindex-code for the implementation and star the project if you like it!