

CocoIndex changelog 0.3.27–0.3.34
Since the last release, CocoIndex shipped 8 releases (0.3.27–0.3.34) and this cycle was focused on one clear goal: making CocoIndex the context engine that adapts to the knowledge ecosystems - vector stores, graph databases, or analytics backends your agents need — while getting even smarter about keeping itself healthy underneath.
We are super excited to build with the amazing infrastructure projects together on the path of agents going to production in 2026.
Agents don’t just need fresh data — they need it wherever it lives. Different teams pick different databases by their usecases. Some want LanceDB for multi-modal capability. Some want ChromaDB for local-first development. Graph-heavy workloads need FalkorDB or Ladybug. Analytics & Search workloads want Apache Doris. And… a lot more great projects in the ecosystems coming soon. This cycle, we made sure CocoIndex speaks all of them — so you pick the best target for your use case, and CocoIndex handles the rest.
CocoIndex helps you ace the data for agents without heavy data engineering work. — Continuous fresh, structured and programmable context for AI, from PDFs, Codebase, Emails, Screenshots, Meeting Notes, … — always up-to-date, at any scale, ultra-performant, with a smart incremental engine. ⭐ Star the repo
Here what we shipped since last release -
0.3.27–0.3.34 was about target reach and engine hardening: five new target connectors, filesystem-level change detection, Python 3.14 free-threading, and smarter pipeline lifecycle management.
Core capability
CocoIndex’s core engine got sharper this cycle. The runtime now automatically cleans up stale derived metadata and data when you rename or remove a source — no manual intervention, no orphaned rows. Tighter validation catches bad table and column names before they hit your database. A new print_stats option surfaces pipeline statistics directly in the update() API. And for the first time, CocoIndex supports Python 3.14 free-threaded mode — running without the GIL for true parallelism in Python-heavy pipelines.
Automatic stale source cleanup
When CocoIndex detects that a source has been renamed or removed, it now automatically streams through tracking metadata, deletes corresponding target rows, and removes stale state records — all during flow setup with controlled parallelism to avoid overloading your database (#1468).
Python 3.14 free-threaded support
CocoIndex now runs natively in Python 3.14’s free-threaded mode (no GIL). CI builds ship free-threaded wheels on manylinux — so you can leverage true multi-threaded Python without any config changes (#1357, #1609, #1638).
Tighter target validation
Table names and column names are now validated before target setup — catching naming issues early instead of surfacing cryptic database errors downstream (#1714).
Execution plan initialization fix
Fixed a race condition where the execution plan could be used before target setup completed, ensuring correct pipeline initialization order (#1715).
Pipeline stats in update() API
Added a print_stats option to the update() API, giving you runtime statistics directly at the call site — useful for monitoring, benchmarking, and debugging pipeline performance (#1525).
Custom database schema for internal tables
CocoIndex’s internal metadata and tracking tables now support custom Postgres schemas via explicit schema.table qualification. This means cleaner isolation in shared databases — no more search_path side effects (#1459).
Slow HTTP request warnings
The runtime now warns when HTTP requests (e.g., to LLM providers or external APIs) are running slow — making it easier to spot bottlenecks in your pipeline (#1617).
Enhanced tracing
Improved tracing coverage across the engine for better observability and debugging (#1618).
ColPali/ColQwen organization prefix fix
Fixed a crash when using ColPali or ColQwen models with organization-prefixed model names (e.g., org/model-name) (#1624).
Together, these changes make the core engine more self-healing, more observable, and ready for the next generation of Python runtimes.
Integrations
This cycle is a massive expansion of where CocoIndex can send data — five brand-new target connectors, filesystem-level change detection for local files, and deeper LanceDB indexing support.
Sources
Local file change notifications
The LocalFile source now supports native filesystem change notifications via the notify crate. Enable the new watch_changes option and CocoIndex will detect file changes through OS-level events instead of polling — faster reaction times, less CPU overhead, and your include/exclude patterns are respected automatically (#1669).
Targets
Apache Doris
Full-featured native support for Apache Doris 4.0 (and VeloDB Cloud) as a vector database target. Includes HNSW and IVF vector indexes, inverted full-text search indexes with Unicode/English/Chinese parsers, Stream Load ingestion with batching and exponential backoff, and upsert/delete support. A complete text embedding example ships alongside (#1475, #1642).
ChromaDB
Initial ChromaDB integration with support for PersistentClient, CloudClient (with SPANN+SPFresh), and HttpClient. Includes HNSW configuration options, explicit document_field specification, and early validation for vector fields (#1548, #1663).
FalkorDB
New property graph target powered by FalkorDB — a high-performance graph database built on Redis. Full support for nodes, relationships, vector and FTS indexes, and batch operations. Ships with a complete docs-to-knowledge-graph example using LLM extraction (#1481).
Ladybug (successor to Kuzu)
Kuzu was archived in October 2025 — Ladybug is the active community fork and a drop-in replacement with an identical Cypher API. CocoIndex now targets Ladybug natively, with backward-compatible Kuzu* type aliases so existing pipelines migrate seamlessly (#1487).
LanceDB
Added VectorIndexMethod support for HNSW and IVF Flat indexes in LanceDB, giving you fine-grained control over index configuration (#1409).
Pinecone
Pinecone is now a built-in target connector — bring your managed Pinecone indexes directly into CocoIndex pipelines with a text embedding example included out of the box (#1556).
These integrations bring CocoIndex’s supported target ecosystem to 10+ databases — covering vector stores, graph databases, relational systems, and analytics engines.
Build with CocoIndex
SEC EDGAR financial analytics with CocoIndex + Apache Doris
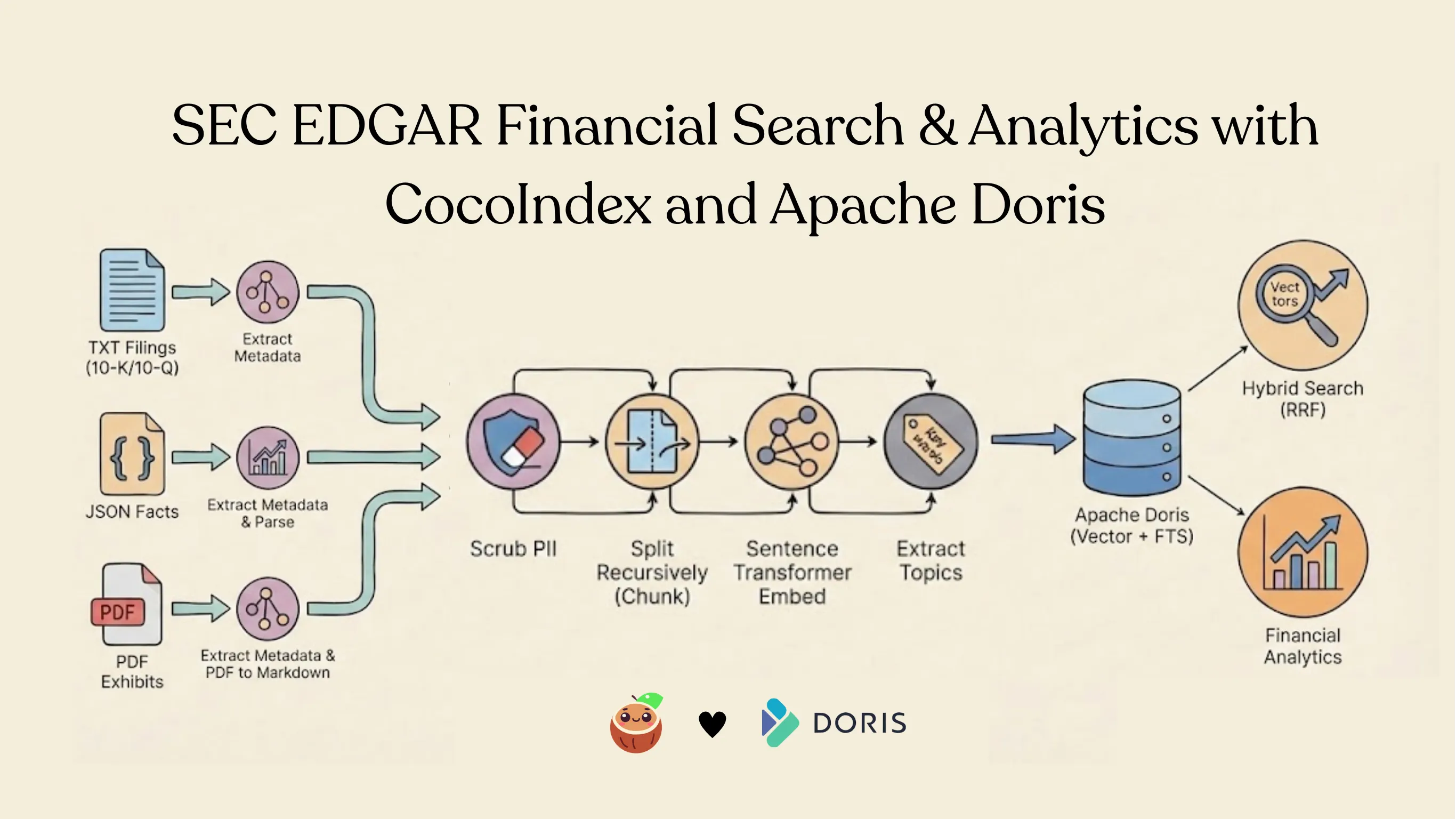
A full multi-source ETL pipeline demonstrating how to build a financial analytics system from SEC EDGAR data using CocoIndex and Apache Doris.
The example ingests three data sources — TXT filings (10-K/10-Q risk factors), JSON company facts from the SEC XBRL API, and PDF proxy statements — then indexes them into Apache Doris with hybrid search (vector + keyword via Reciprocal Rank Fusion), topic filtering with JSON arrays, and portfolio-level search with per-company aggregation.
It also demonstrates PII scrubbing before indexing and incremental updates with caching — a production-ready pattern for financial data pipelines.
Checkout the tutorial for more details.
Slides-to-Speech: Turn slide decks into searchable, narrated knowledge

Static slide decks sitting in Google Drive are one of the most underutilized knowledge sources in any organization. We published a full walkthrough showing how to build a continuously updating slides-to-speech pipeline using CocoIndex and LanceDB.
The pipeline watches a Drive folder for new or modified PDF decks, converts each slide to an image with PyMuPDF, extracts structured speaker notes using BAML + Gemini Vision, synthesizes narration with Piper-TTS, generates embeddings, and indexes everything into LanceDB — images, transcripts, audio bytes, and metadata all in one place.
What’s cool about this example:
- Incremental by design — Only changed slides get reprocessed. Update one slide in a 200-page deck? CocoIndex touches only that slide — regenerating its audio, transcript, and embedding while leaving the rest untouched.
- True multimodal search — Semantic queries return the top matching slides with images, speaker notes, and synced audio — not just filenames.
- Local-first TTS — Neural text-to-speech runs locally via Piper, so there are no API costs for audio generation.
- Living knowledge base — What used to be a static PDF becomes a searchable, listenable, always-fresh dataset ready for agents, accessibility tools, or video generation.
Checkout the blog post for more details.
Thanks to the community 🤗🎉
Welcome new contributors to the CocoIndex community! We are so excited to have you!
@tomz-alt

Thanks @tomz-alt for adding the Apache Doris 4.0 vector database connector — a full-featured target with vector indexes, full-text search, and Stream Load ingestion — and for building the SEC EDGAR financial analytics example demonstrating multi-source ETL with hybrid search, plus improving the Doris text embedding example and cleaning up the SEC EDGAR tutorial for an end-to-end demo experience.
@prrao87

@galshubeli

Thanks @galshubeli for adding the FalkorDB target — a complete property graph integration with nodes, relationships, vector/FTS indexes, and a docs-to-knowledge-graph example.
@Geoff-Robin

Thanks @Geoff-Robin for adding custom database schema support for CocoIndex’s internal tables, enabling cleaner isolation in shared Postgres databases with explicit schema.table qualification.
@wuxiaobai24

Thanks @wuxiaobai24 for adding Python 3.14 free-threaded support, configuring PyO3 for GIL-free operation and bringing CocoIndex to the cutting edge of Python parallelism.
@ceshine

Thanks @ceshine for fixing the ColPali/ColQwen crash when using models with organization prefixes, unblocking multimodal embedding workflows.
@LED-0102

Thanks @LED-0102 for adding filesystem change notifications to the LocalFile source using the notify crate, enabling OS-level file watching for faster live updates.
@prithvi-moonshot

Thanks @prithvi-moonshot for adding Pinecone as a target connector with a text embedding example, bringing managed vector search into the CocoIndex ecosystem.
@Haleshot

Thanks @Haleshot for building the initial ChromaDB target integration with support for PersistentClient, CloudClient, and HttpClient, fixing ChromaDB collection creation on first run, adding ChromaDB documentation, adding llms.txt to docs, adding short flag aliases for common CLI options, clarifying .env usage across examples, and migrating CI from pre-commit to prek.
@thisisharsh7

Thanks @thisisharsh7 for adding automatic cleanup of stale source data, ensuring renamed or removed sources don’t leave orphaned tracking metadata or target rows.
@majiayu000

Thanks @majiayu000 for adding VectorIndexMethod support for HNSW and IVF Flat indexes in LanceDB, expanding vector index configuration options.
Summary
CocoIndex continues evolving into a universal, resilient data engine for the modern AI stack.
This cycle focuses on target ecosystem breadth, engine self-healing, and Python 3.14 readiness — ensuring your pipelines can write to any database your agents need, clean up after themselves, and run on the latest Python runtime without compromise.
If you like this project, please support us with a star ⭐ at https://github.com/cocoindex-io/cocoindex !
🔥🔥 We are cooking something big! - v1 coming soon and stay tuned! If you read all the way here, you are a true fan!

About the author.

Maintainer of CocoIndex, Ex-Google Infra Lead. Writes about incremental data infrastructure, Rust internals, and the engineering decisions behind the engine.