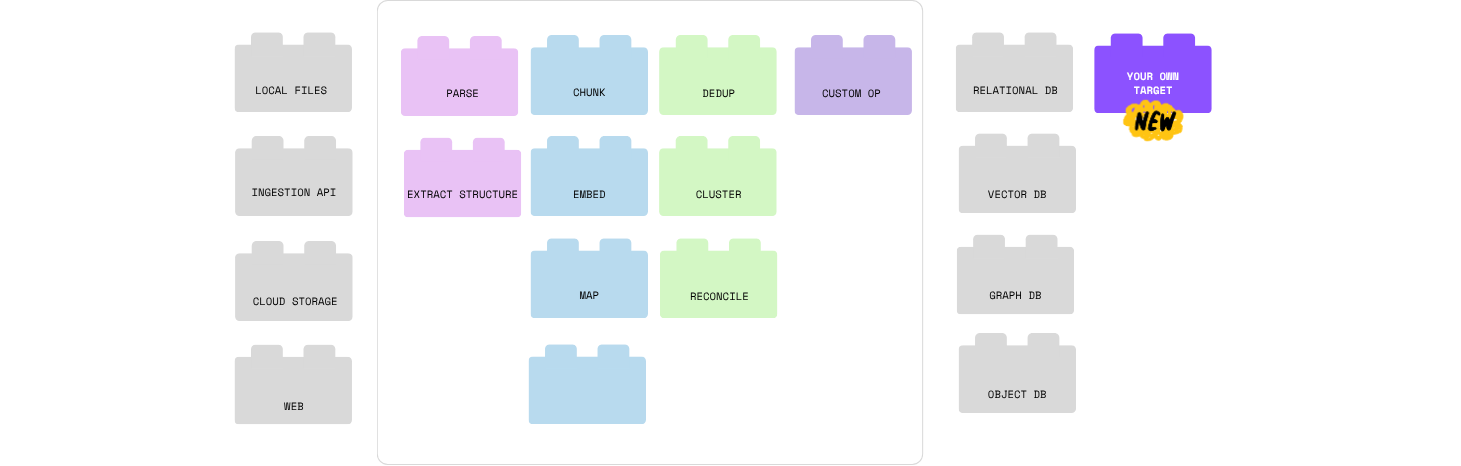
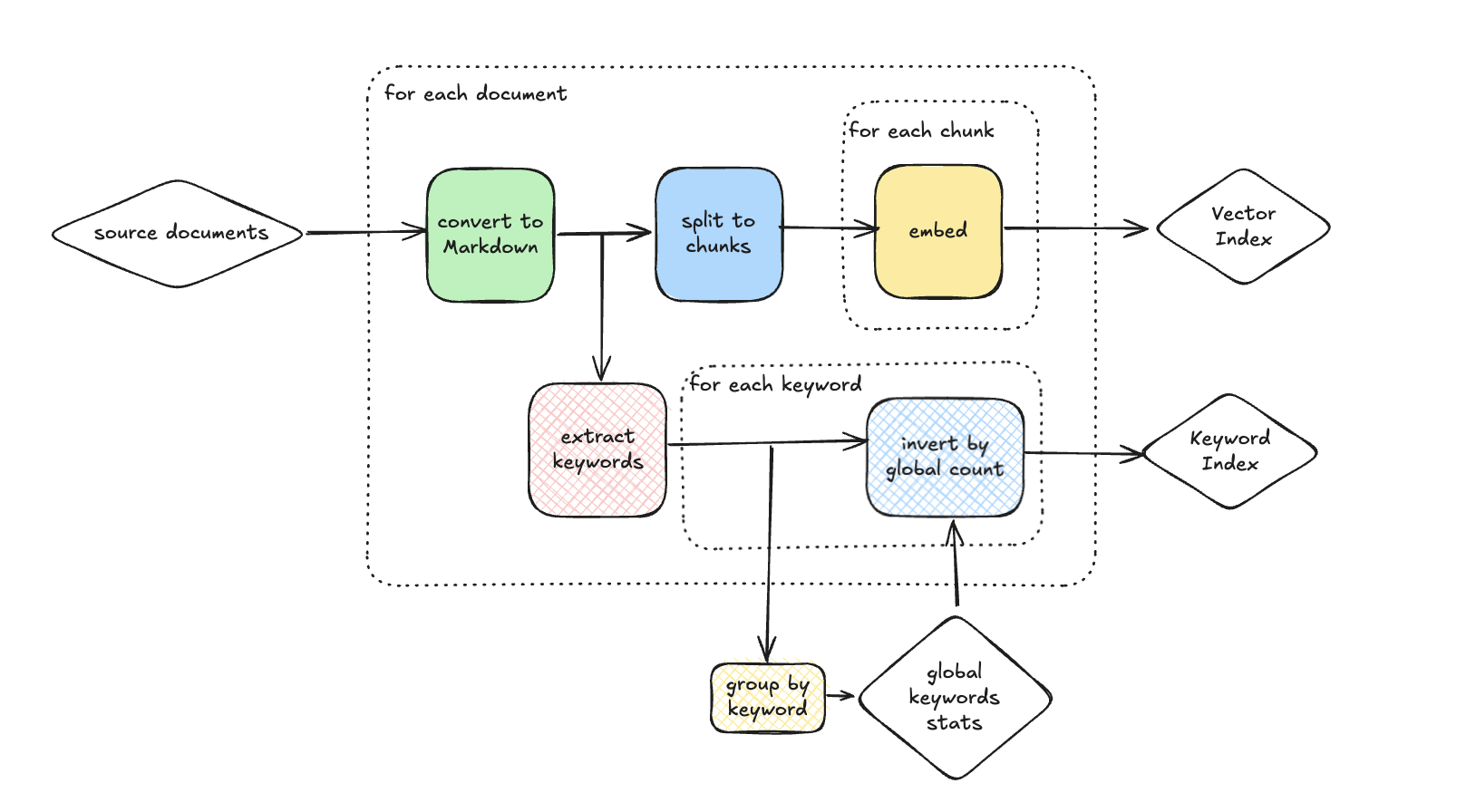
Build a pipeline that converts YouTube podcasts into a structured knowledge graph — extracting speakers, statements, and entities with LLM, then resolving duplicates with embeddings.
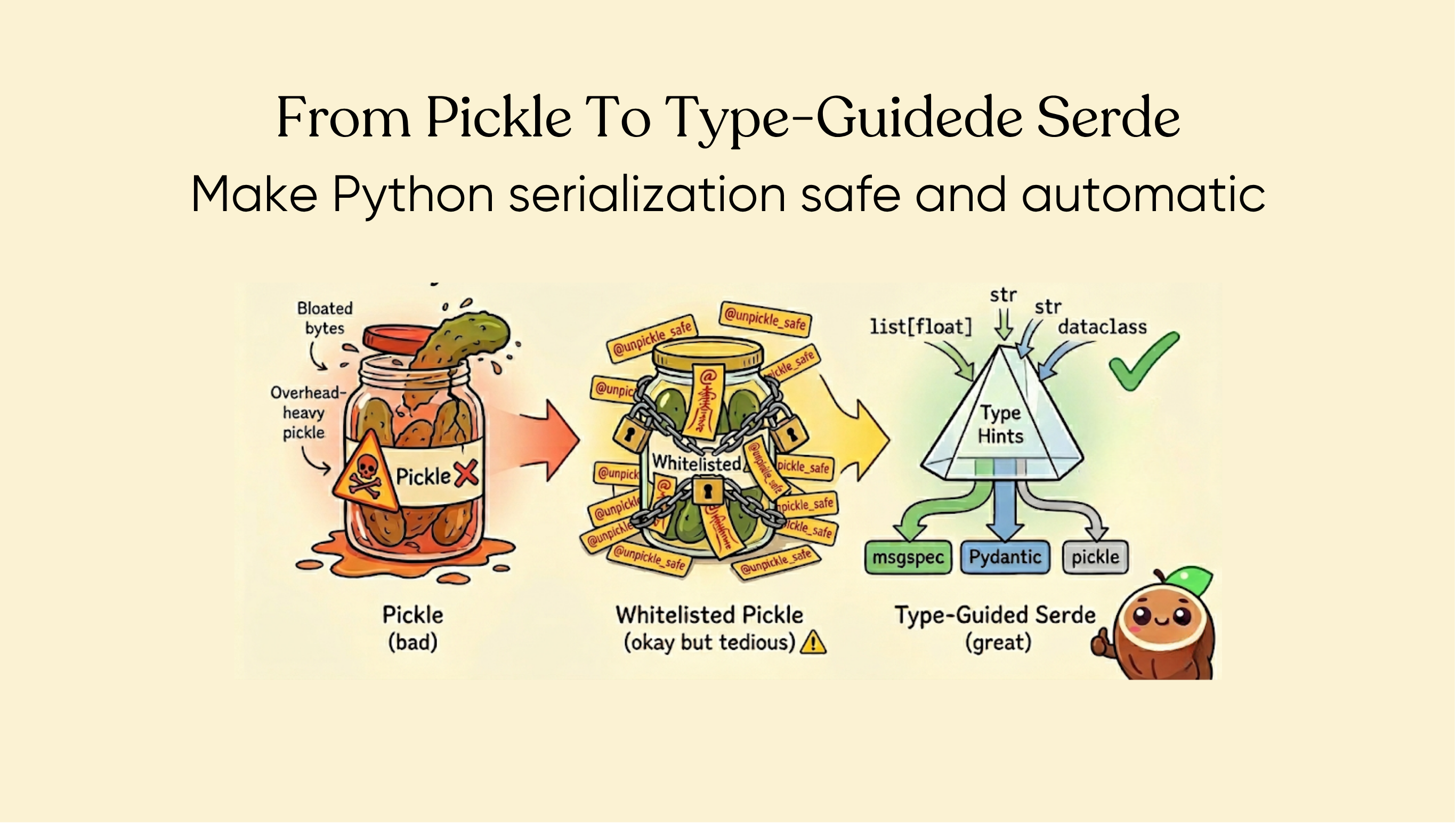
How CocoIndex evolved from pickle to a type-guided serialization system that uses Python type hints to automatically choose the right serializer — no decorators or registration needed.
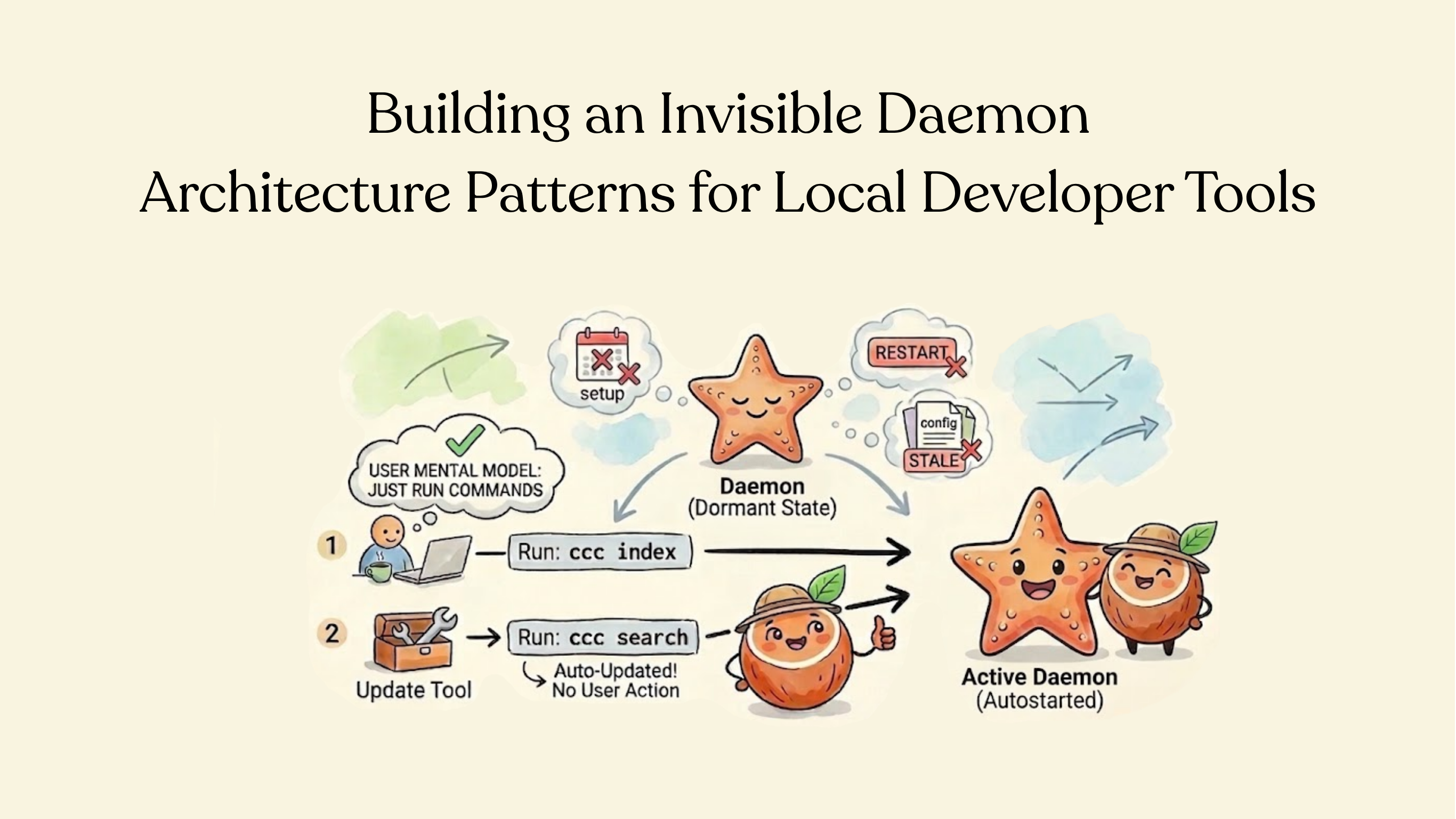
Patterns for building local daemons that start on first use, upgrade transparently, and shut down cleanly — learned from building cocoindex-code's semantic search daemon.
Featuring five new target connectors, filesystem-level change detection, Python 3.14 free-threading, and smarter pipeline lifecycle management.
CocoIndex participated in the GitHub Secure Open Source Fund, strengthening our security practices for the AI data infrastructure that developers depend on. Here's what we learned and what changed.
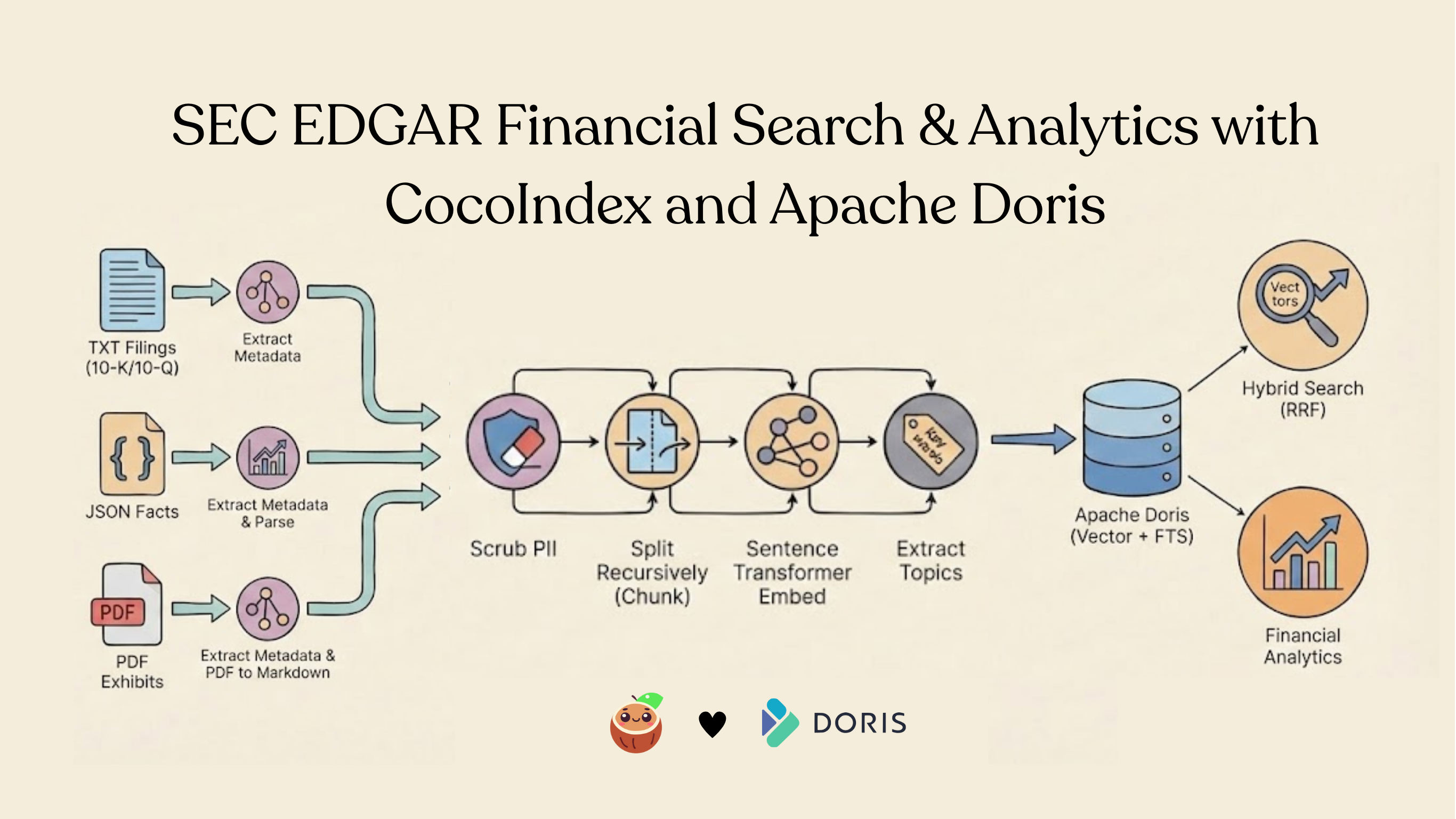
A multi-source pipeline that ingests SEC filings (TXT, JSON, PDF), scrubs PII, extracts topics, and powers hybrid search with CocoIndex + Apache Doris.
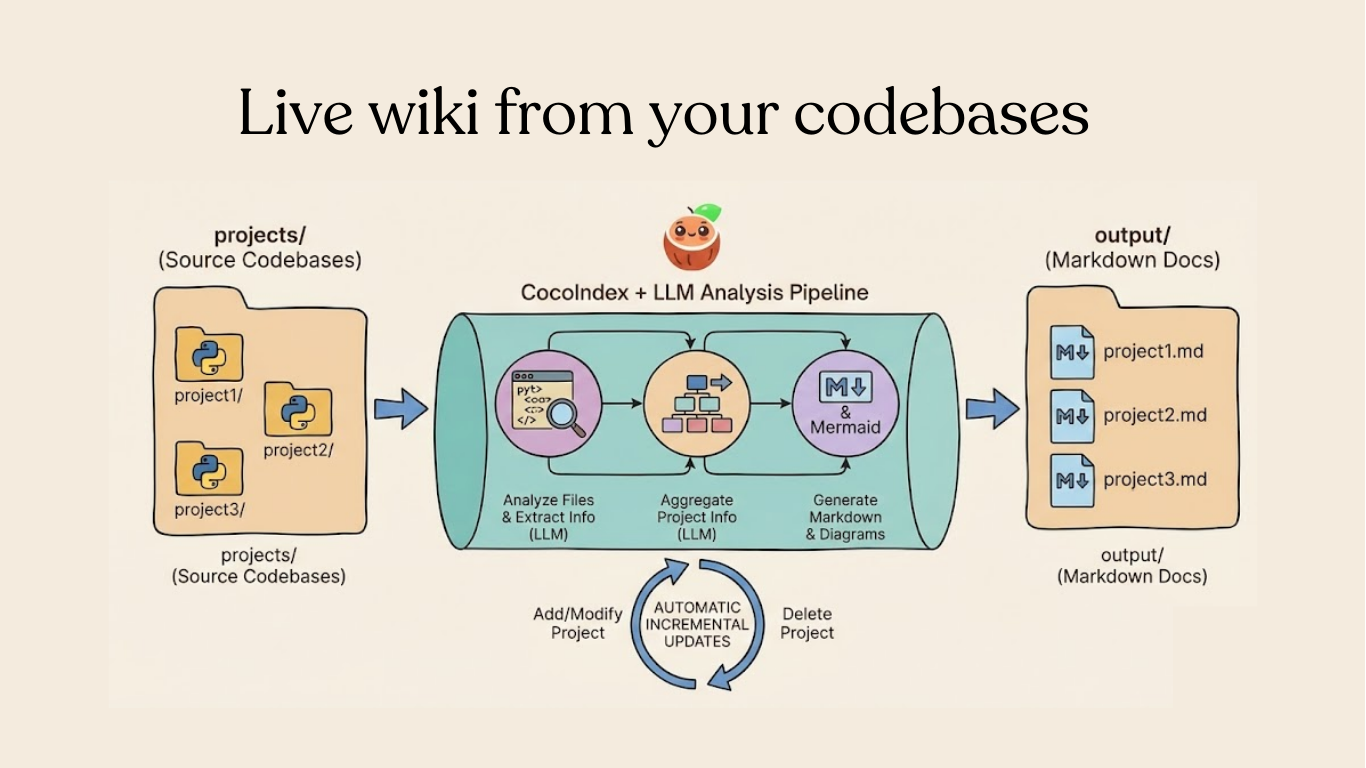
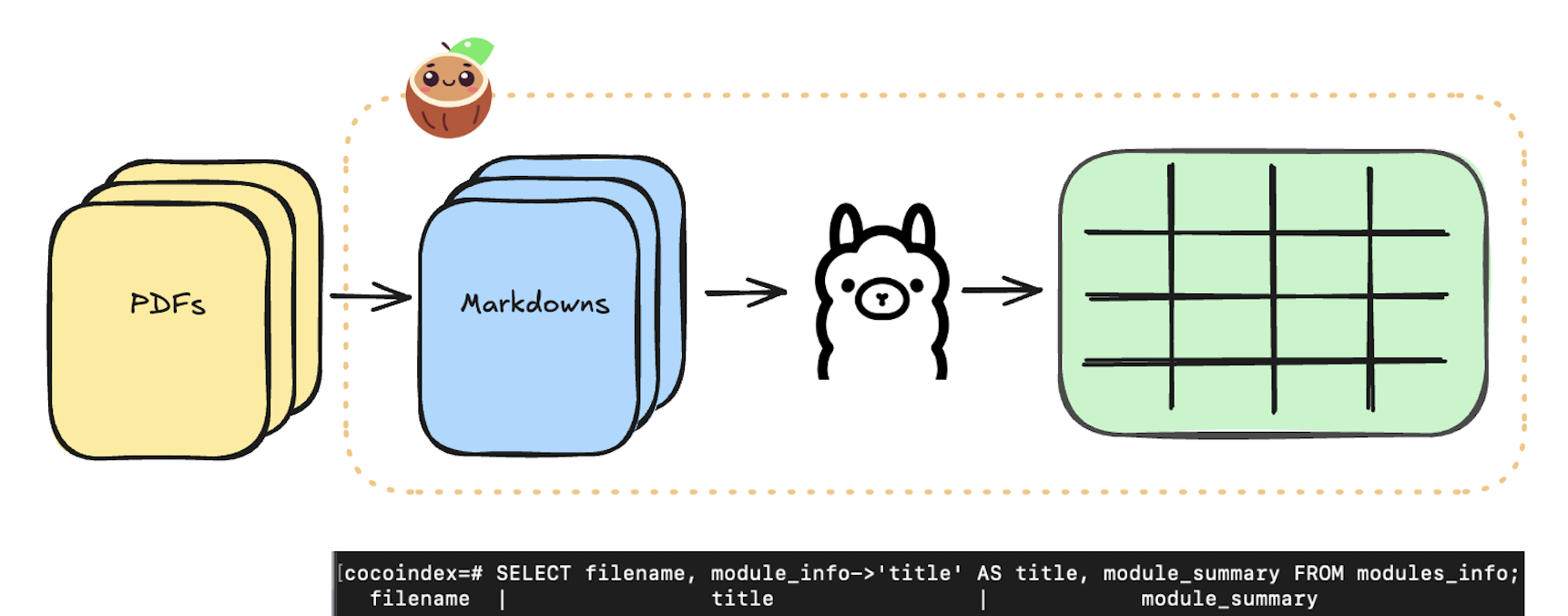
Automatically generates a wiki page for each project in your codebase, and keeps it fresh with incremental processing.
Turn slide decks into a continuously updated, searchable multimodal dataset. CocoIndex watches a Drive folder for new and modified files, extracts structured speaker notes, synthesizes narration, and keeps LanceDB in sync.
Featuring production-ready resilience, structured error system, expanded integrations, and always-fresh structured context for agents operating in the real world.
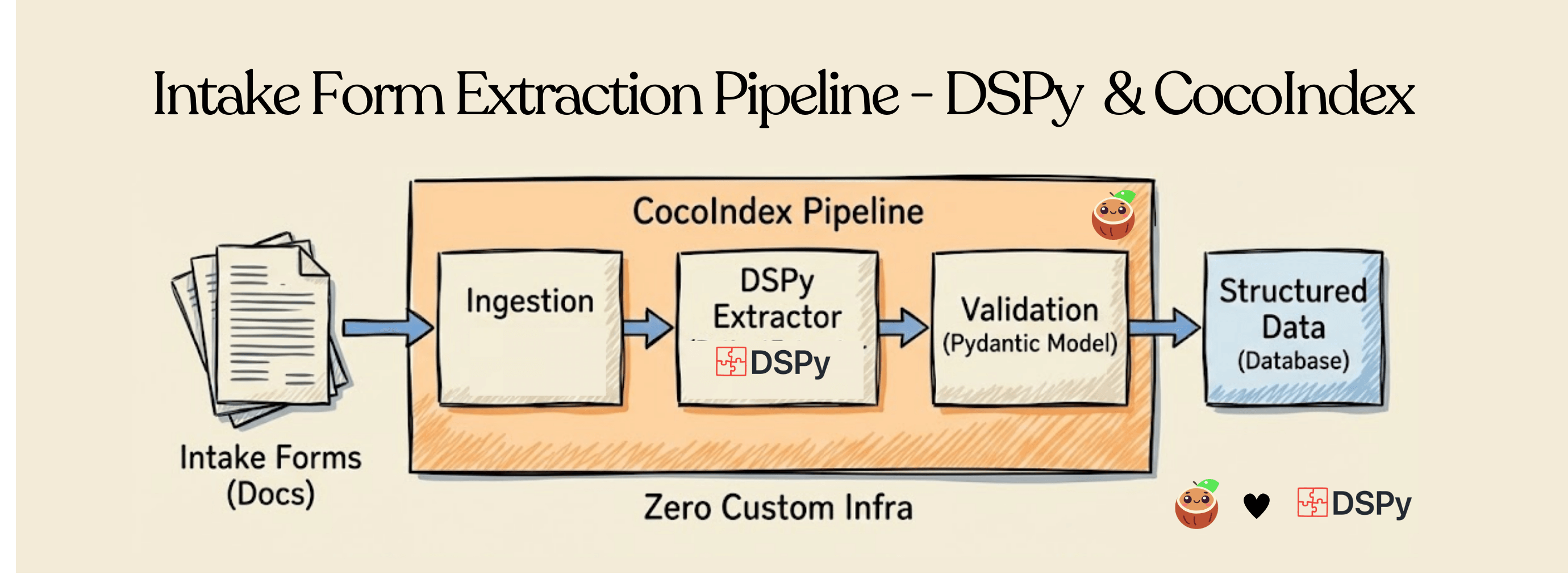
Continuously extract clean, typed, Pydantic-validated structured data directly from patient intake forms, using DSPy and CocoIndex. This tutorial demonstrates building scalable, production-grade AI pipelines with typed Pydantic validation, OCR vision models, and fast, incremental data processing.
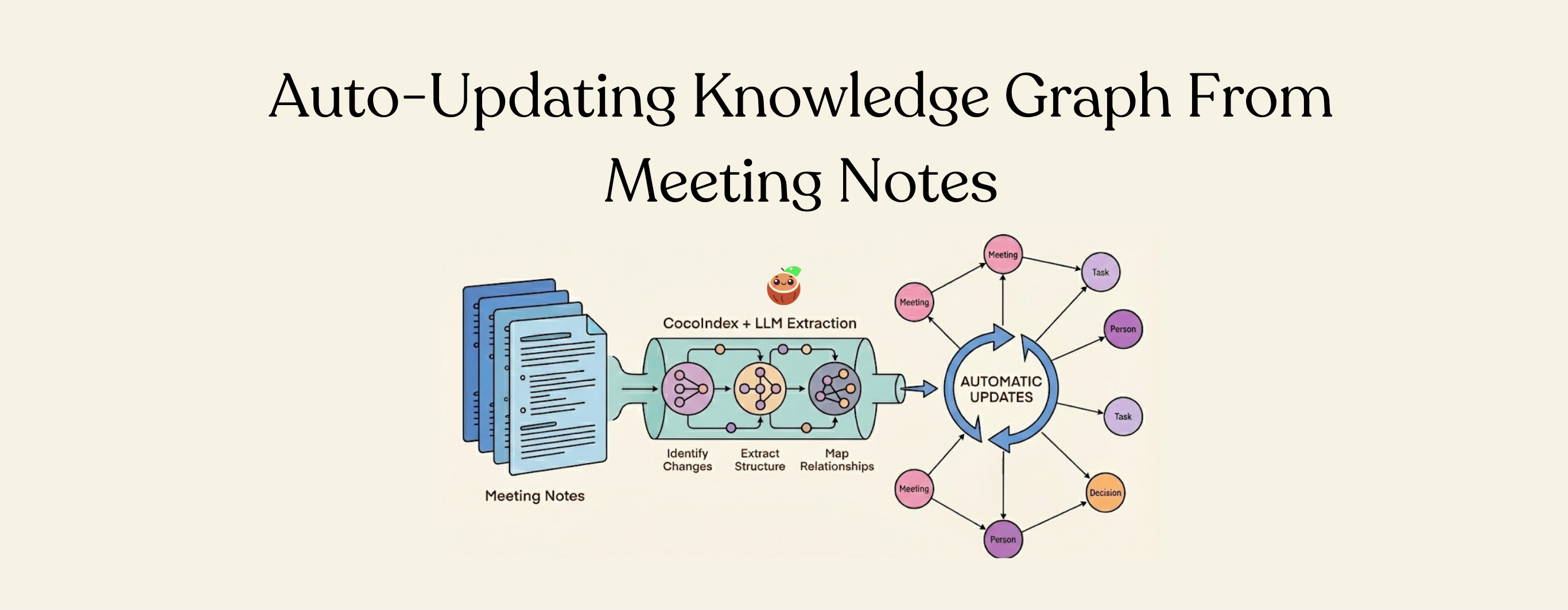
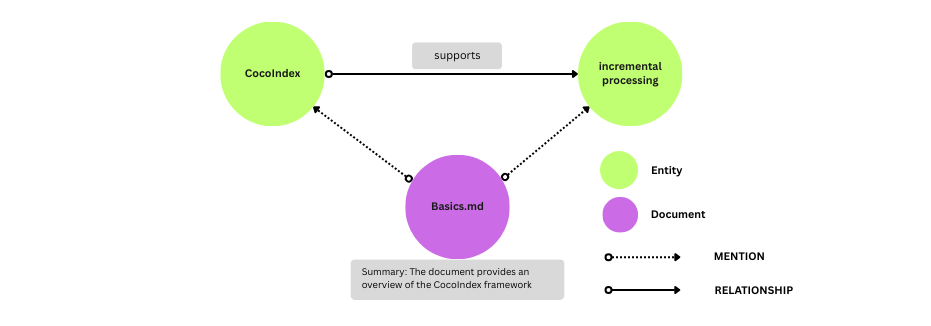
Most companies sit on an ocean of meeting notes - inside those documents are decisions, tasks, owners, and relationships — an untapped knowledge graph that is constantly changing. A full walkthrough to turn meeting notes in Google Drive into a live-updating Neo4j knowledge graph using CocoIndex and LLM.
Building a Real-Time HackerNews Trending Topics Detector with CocoIndex: A Deep Dive into Custom Sources and AI
Featuring batching support for CocoIndex functions, execution robustness, schema & type system improvements, custom source support, and more.
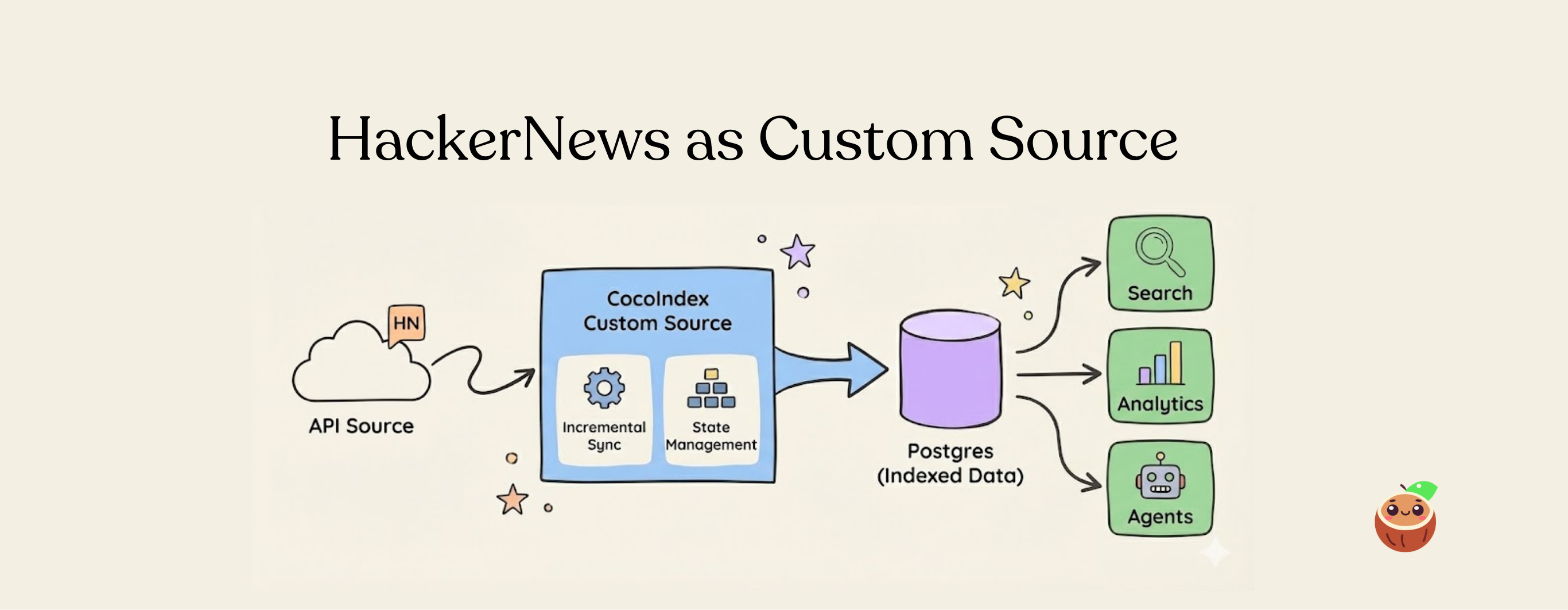
Build a lightweight, incremental pipeline by treating any API as a data component - custom incremental connector for HackerNews using CocoIndex’s Custom Source API. Export the data to Postgres for semantic search and analytics.
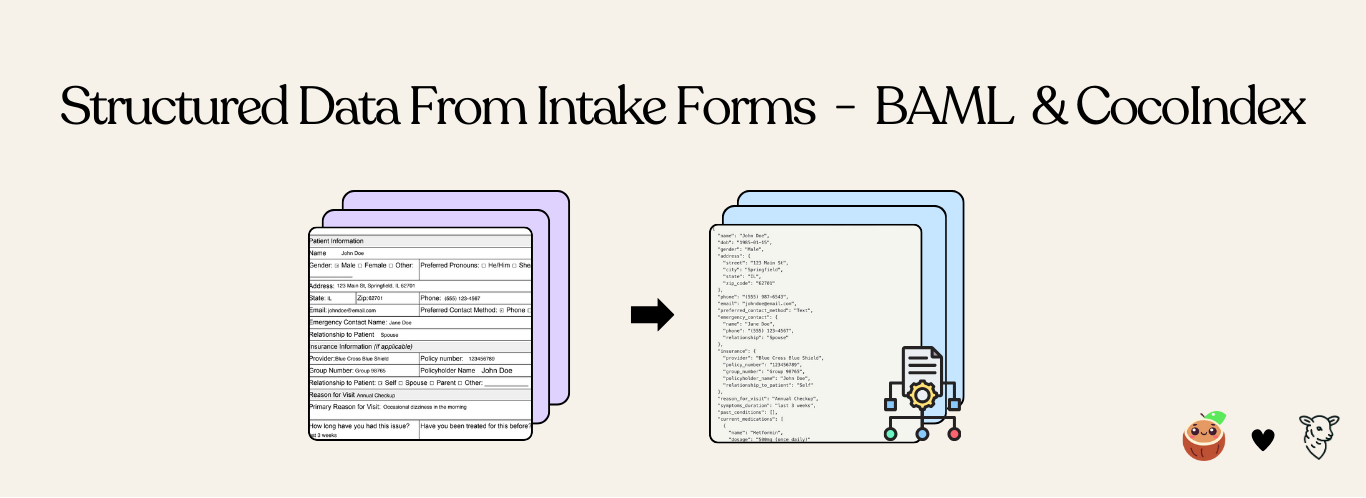
How to use BAML and CocoIndex to extract structured data from patient intake forms in PDF/Word with LLM continuous for production.
Discover how CocoIndex delivers automatic batch processing for GPU workloads and machine learning pipelines. Framework-level batching optimizes performance for text embeddings and other AI operations without configuration.
Why the next wave of AI needs open source, scalable, and AI-native data infrastructure, and how CocoIndex is building the foundation for the future of intelligent data pipelines.
Extracts, embeds, and stores multimodal PDF elements — text with SentenceTransformers and images with CLIP — in vector database for unified semantic search. Includes full metadata traceability, thumbnail generation, and flow definitions for building multimodal retrieval systems.
CocoIndex now officially supports custom sources — giving you the power to read data from any system you want. You can use CocoIndex for anything, and enjoy the robust incremental computing to build fresh knowledge for AI.
Featuring significant optimizations for production ready infrastructure: durable execution, efficient incremental processing optimizations over large datasets, GPU isolation, etc. and better support over native building blocks.
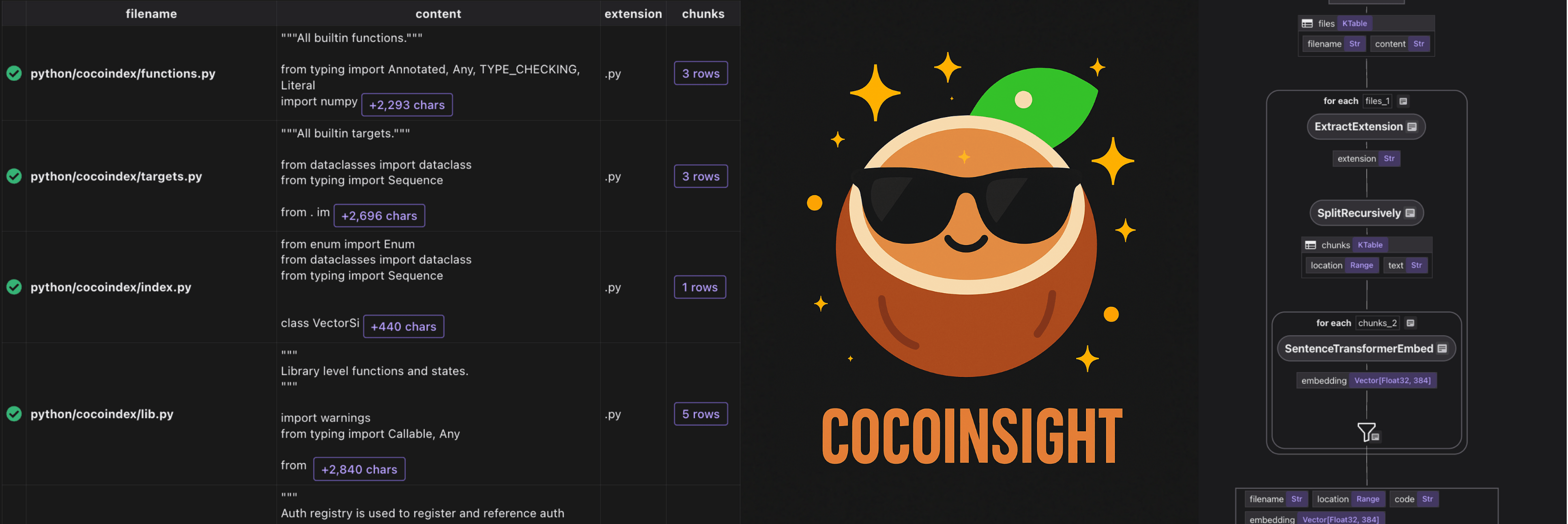
Discover how to rapidly optimize your data indexing strategy with CocoIndex and CocoInsight. Learn to define query handlers, trace search results back to source data, and seamlessly integrate AI-powered transformations for efficient, end-to-end retrieval and analytics.
A mental framework for Rust's memory safety concepts. Think systematically about ownership, references, Send, Sync, and Rc, Arc, RefCell, Mutex, etc.
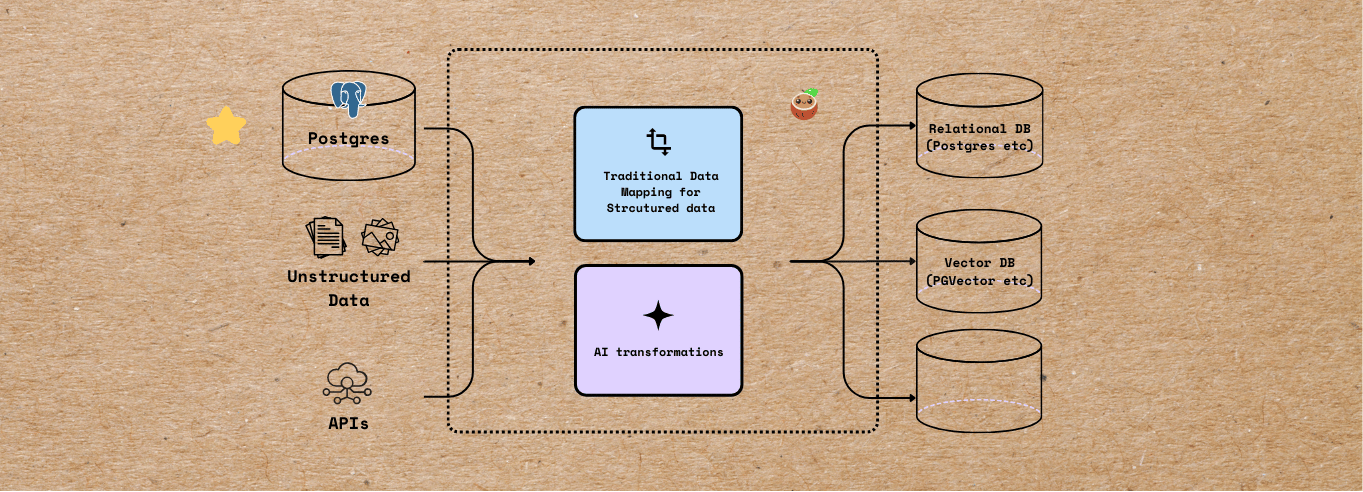
Comprehensive walkthrough on using CocoIndex to build unified, incrementally updated search and analytics pipelines across both structured and unstructured data sources, using PostgreSQL tables as the main origin and target for indexed data.
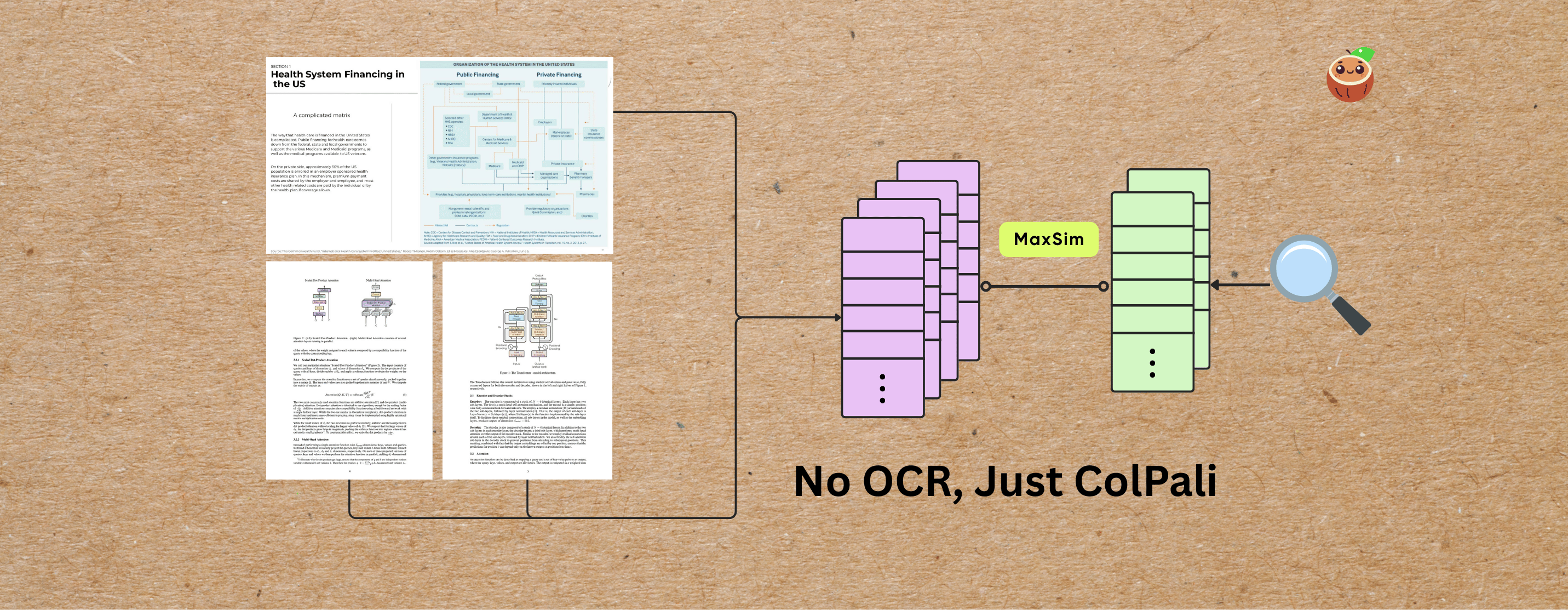
Build a unified visual document index from multiple file formats — including PDFs, images, and slides — using CocoIndex and ColPali, No OCR needed.
Featuring production readiness, scalability, and reliability. More flexibility with customization and native integrations. Extended features for multi-modalities pipelines and more.
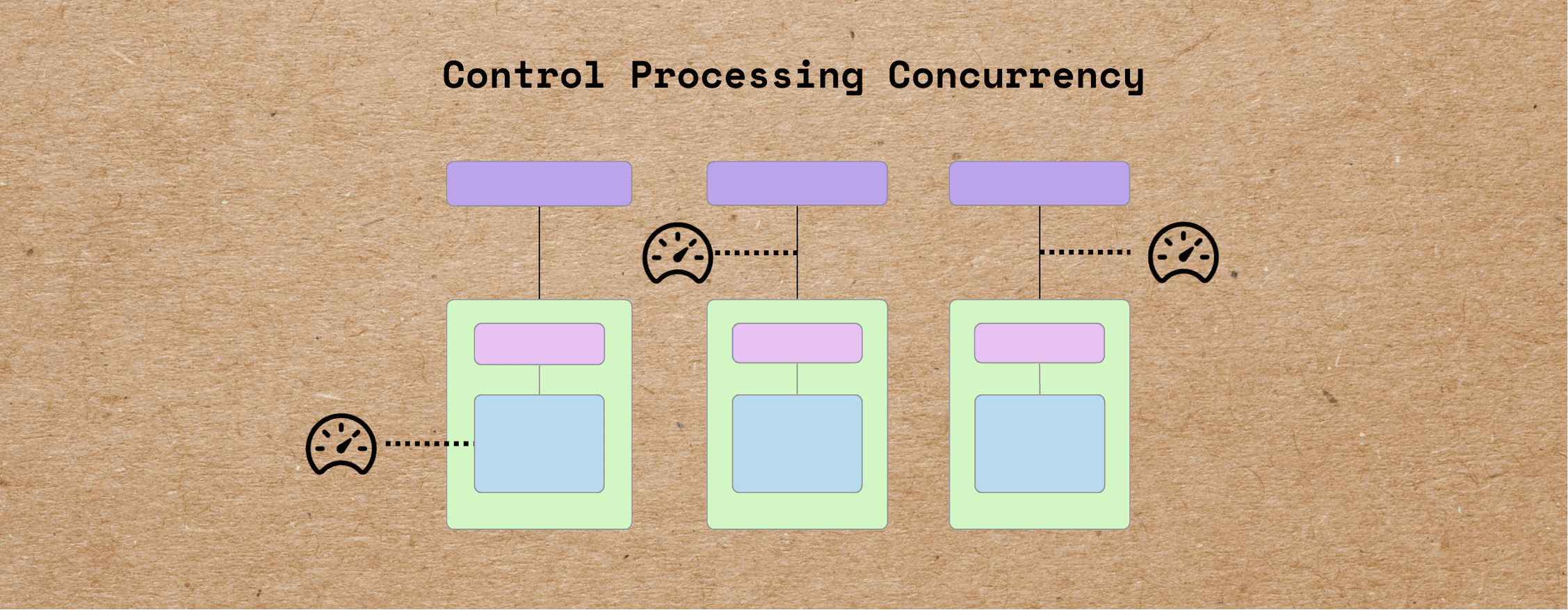
Learn how CocoIndex's layered concurrency control features help you optimize data processing performance, prevent system overload, and ensure stable, efficient pipelines at scale.
CocoIndex now supports native integration with ColPali — enabling multi-vector, patch-level image indexing.
CocoIndex natively handles typed multi-dimensional vectors — from simple arrays to multi-vector embeddings, unlocks multimodal AI pipelines at scale.
CocoIndex now officially supports custom targets — giving you the power to export data to any destination, whether it's a local file, cloud storage, a REST API, or your own bespoke system.
Build a scalable face detection and recognition pipeline using CocoIndex. This tutorial covers extracting and embedding faces from images, structuring data for visual search, and exporting to a vector database for face similarity queries.
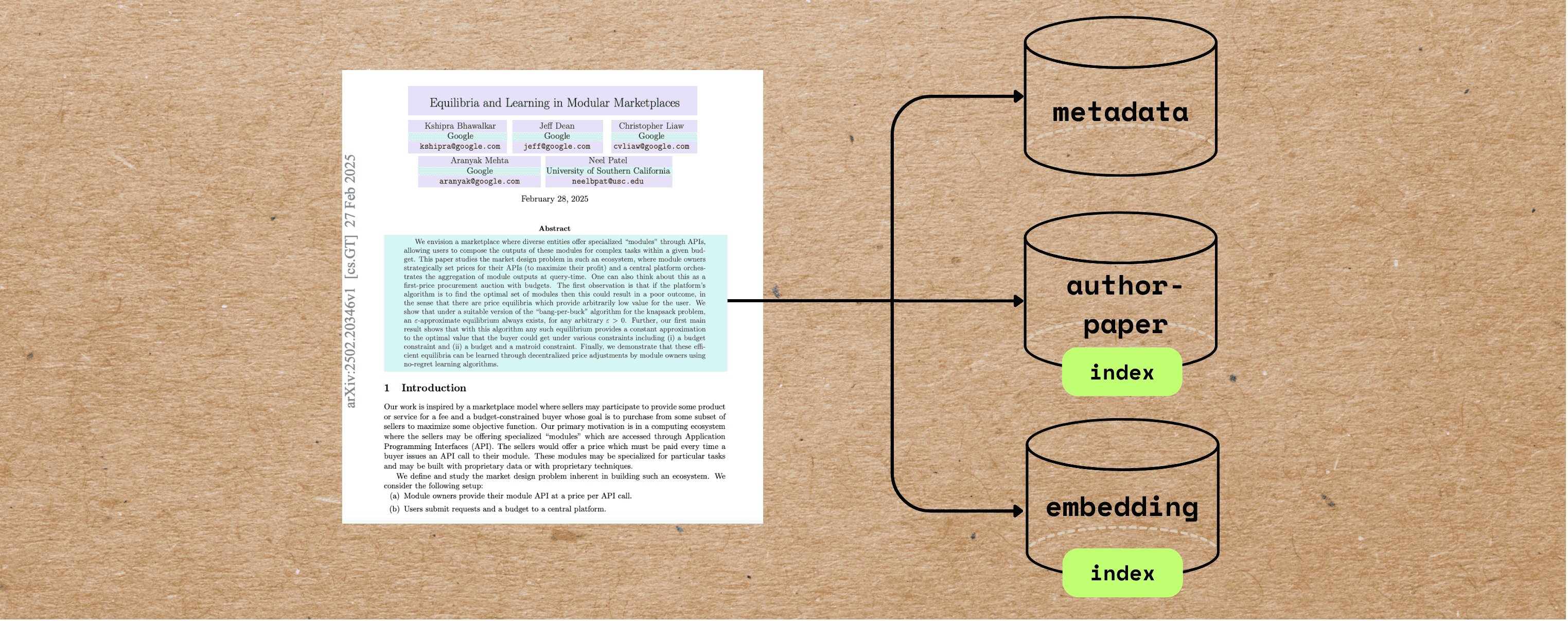
How to index academic research papers by extracting metadata (e.g., title, authors, abstract) for AI agents and AI workflows using LLMs and CocoIndex
CocoIndex updates: in-process API, CLI improvements, EmbedText support, codebase indexing enhancements, and more.
CocoInsight is a platform for data lineage and data observability.
Automatic schema inference for Qdrant.
Integrate Kuzu with CocoIndex.
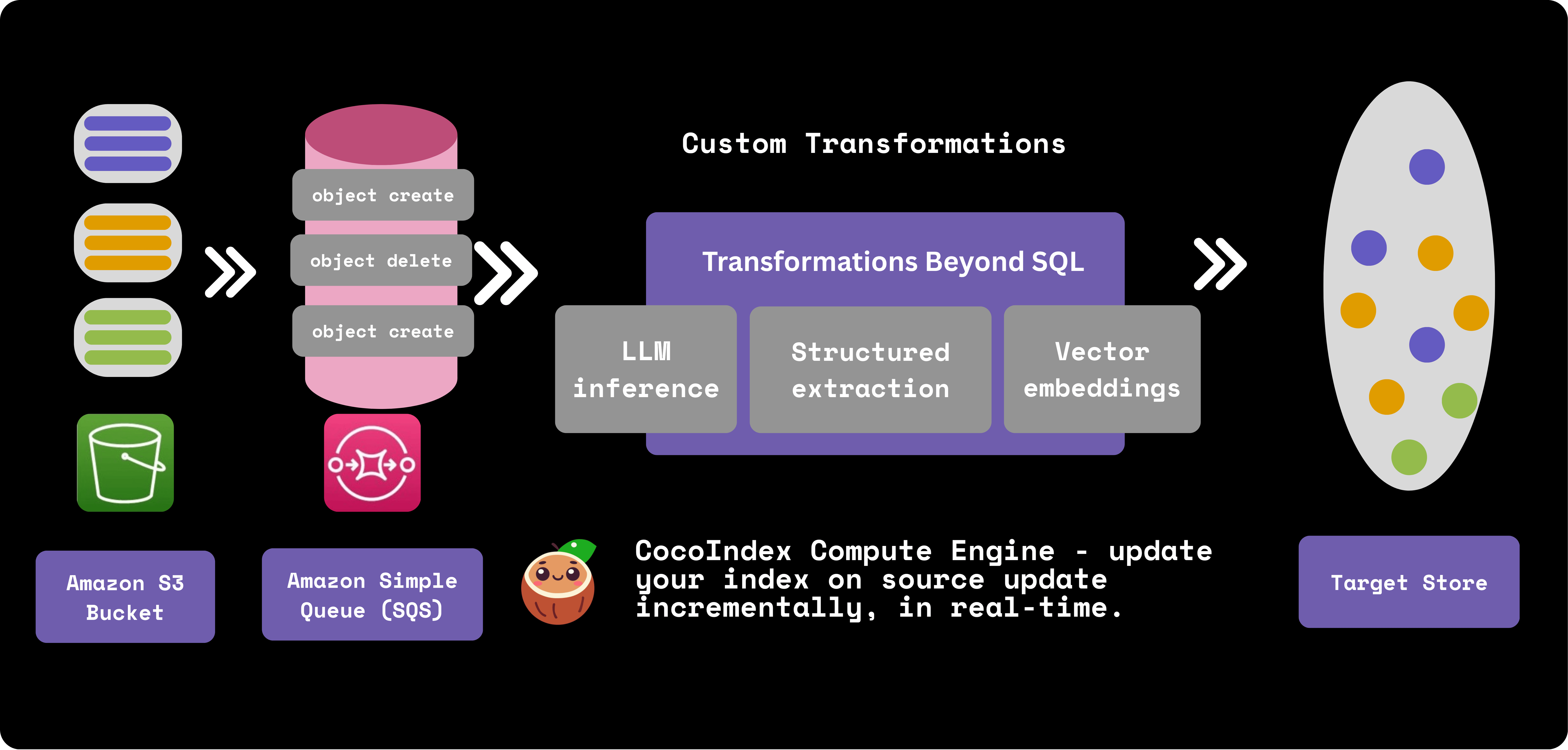
CocoIndex updates: Amazon S3 as a data source, updates on query handling, standalone, and more.
Build real-time data transformation pipeline with S3 and CocoIndex.
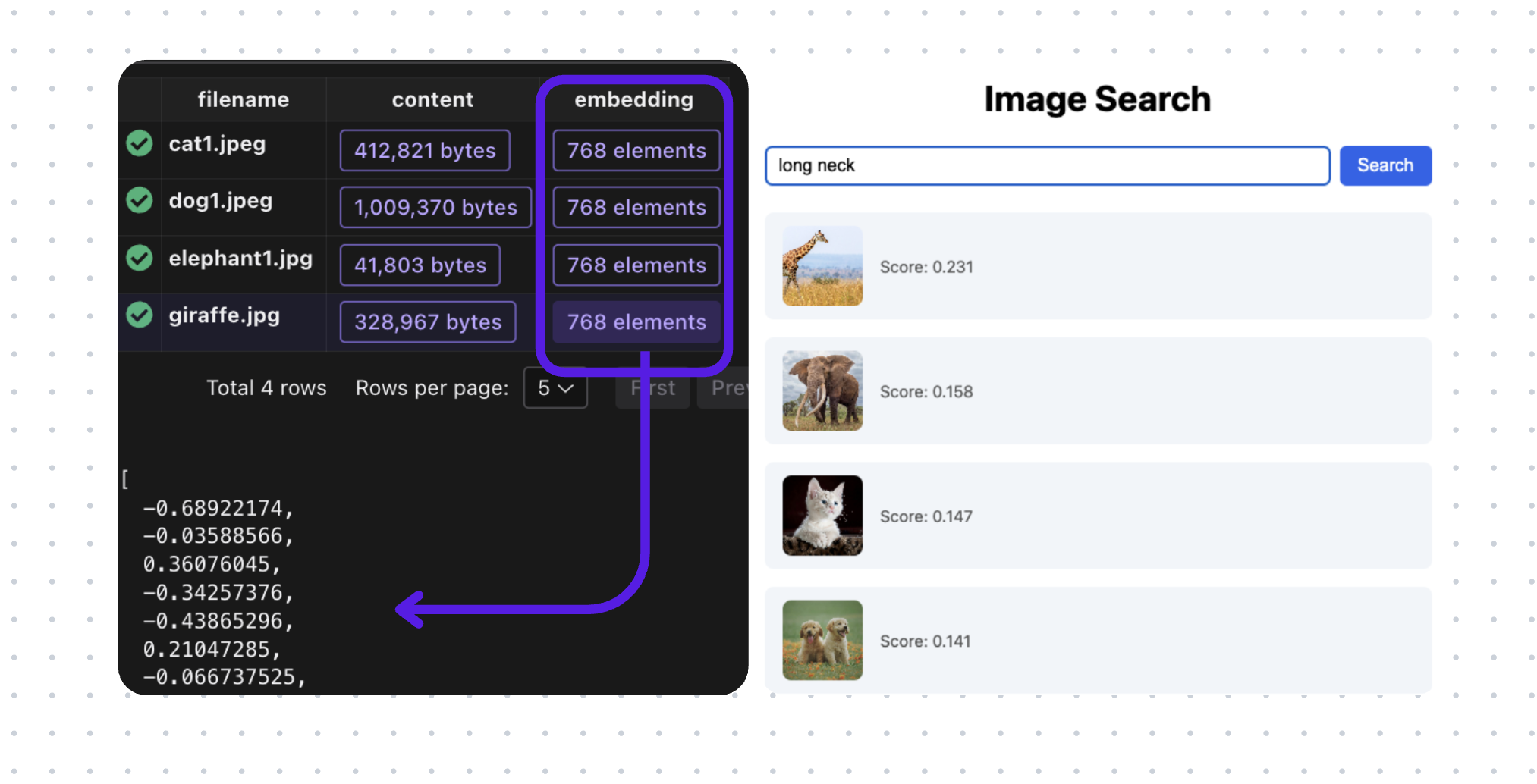
Indexing images with CocoIndex and Vision Model in real-time: multi-modal embedding, and build vector index for efficient retrieval.
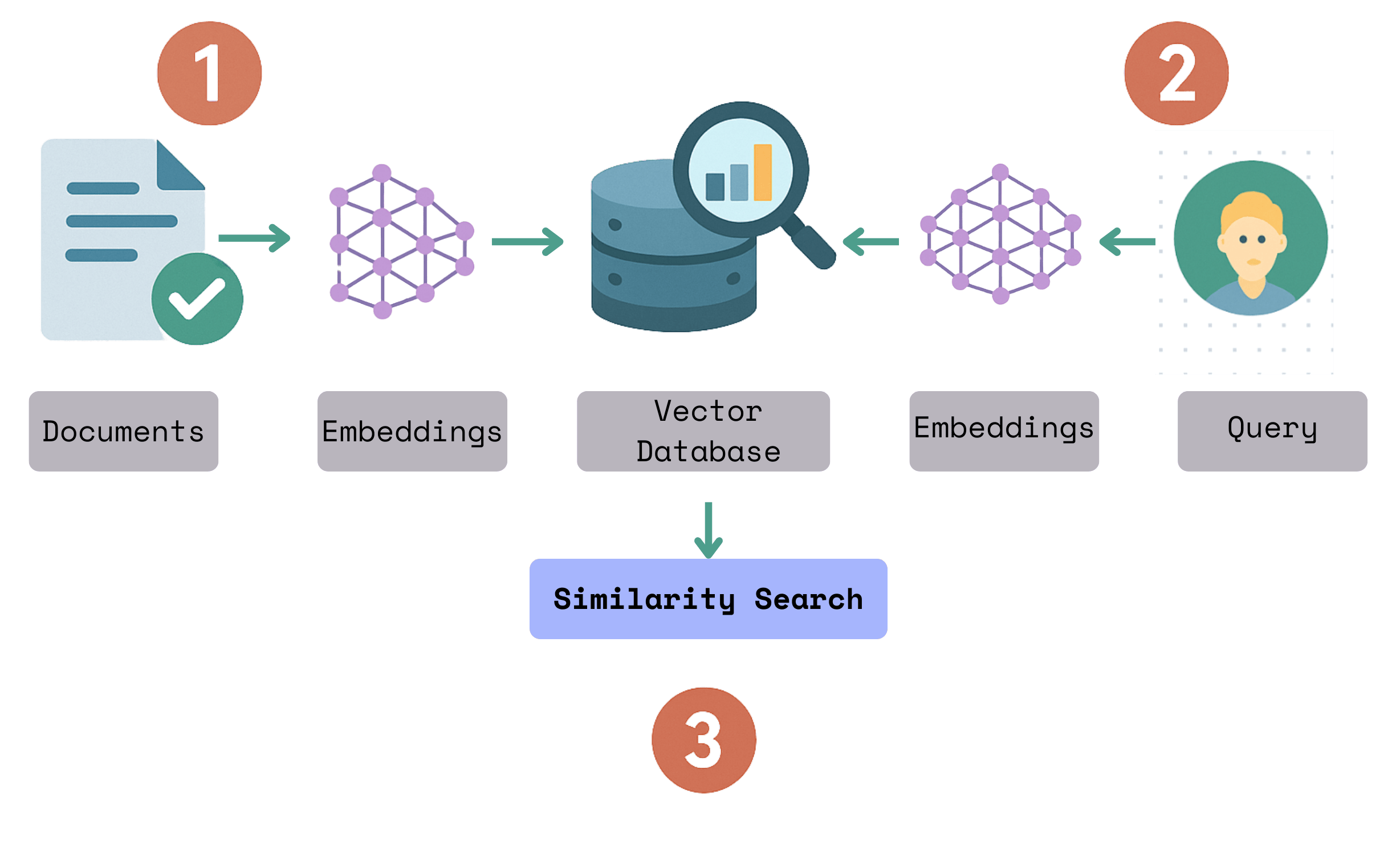
Indexing text with CocoIndex and text embeddings, and query it with natural language.
CocoIndex is the world's first open-source engine that supports both custom transformation logic and incremental processing specialized for data indexing. We just crossed 1k stars, thank you so much!
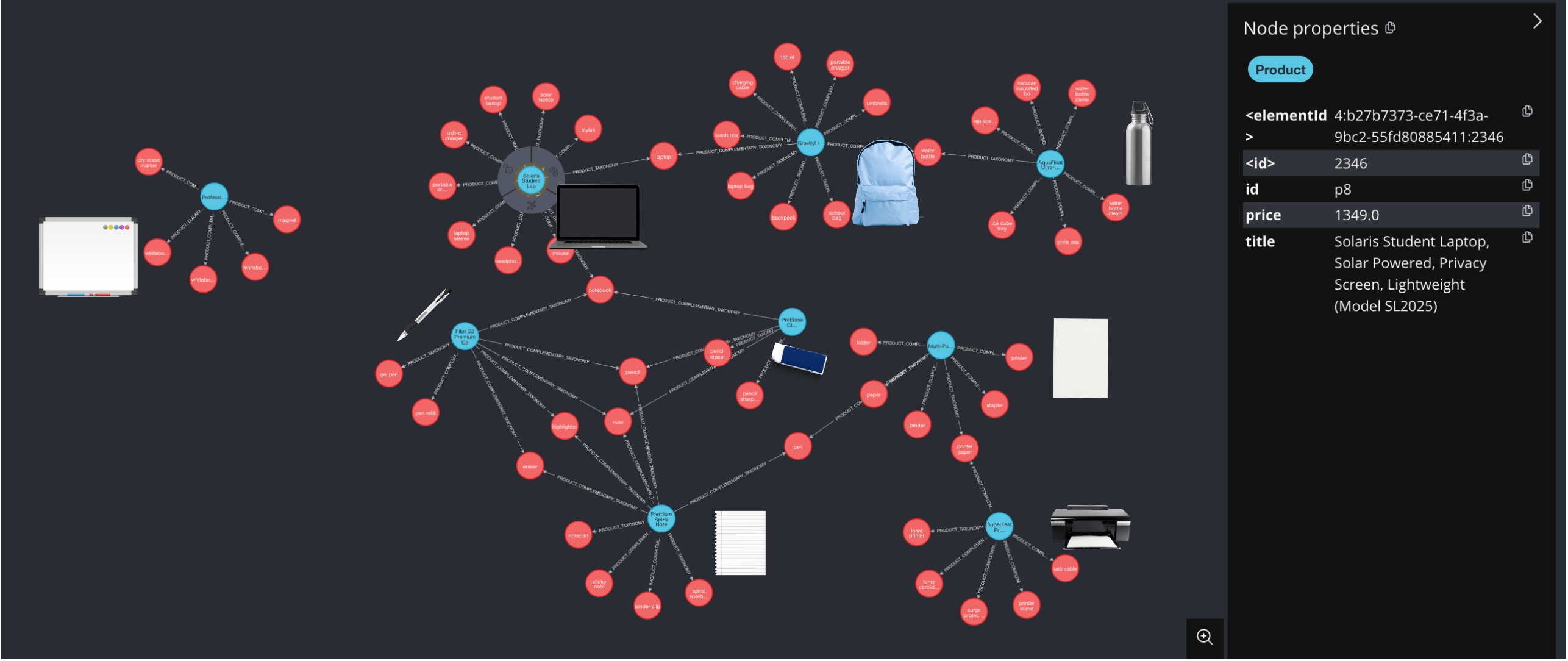
Build a real-time product recommendation engine with LLM and graph database, from the aspect of product category (taxonomy) understanding.
CocoIndex updates: Knowledge Graphs, Qdrant, Supabase, KTable/LTable, and more LLM providers.
CocoIndex now supports knowledge graph with incremental processing. Build live knowledge for agents is super easy with CocoIndex!
CocoIndex updates: Incremental processing with live update mode, evaluation utilities, support for date/time types, Google Drive, and assorted core/performance improvements
CocoIndex continuously watches source changes and keeps derived data in sync, with low latency and minimal performance overhead.
CocoIndex helps to keep index up to date with source changes, super efficient and low latency - with the support of incremental processing.
Extract structured data from patient intake forms in PDF/Word with LLM by CocoIndex.
Tutorial to create text embeddings from docs on Google Drive, save in vector stores for semantics search / RAG, using CocoIndex.
First release of CocoIndex Changelog: LLM support, codebase indexing, custom functions, and assorted core/performance improvements
Indexing codebase for RAG with CocoIndex and Tree-sitter in real-time: chunking, embedding, semantic search, and build vector index for efficient retrieval.
Learn to use CocoIndex extracting structured data from PDF/Markdown with Ollama's local LLM models. All running on premise without sending data to external APIs.
CocoIndex is the world's first open-source engine that supports both custom transformation logic and incremental processing specialized for data indexing. We are now officially open sourced!
Explain what customizable data indexing pipelines are through comparisons and examples.
Understanding the unique characteristics of indexing pipelines compared to other data processing systems. Learn why indexing requires special handling for incremental processing and persistence.
Explore how CocoIndex handles system updates in indexing flows and our approach to automatic schema inference. Learn about the challenges of managing data and logic evolution, infrastructure setup, and how CocoIndex simplifies these processes through smart automation.
Learn best practices for handling large files in data indexing systems. Understand processing granularity, fan-in/fan-out scenarios, and strategies for efficient processing of large datasets like patent XML files. Discover how CocoIndex helps manage memory pressure and ensures reliable processing.
Explore the challenges and solutions for maintaining data consistency in indexing pipelines. Learn about concurrent updates, data exposure risks, and best practices for ensuring reliable, up-to-date indexes using CocoIndex's data-driven approach.
Explore the fundamentals of data indexing pipelines for RAG applications. Learn about key characteristics of effective indexing systems, common challenges in production, and how CocoIndex solves them. Discover best practices for building maintainable, cost-effective, and scalable data indexing infrastructure.
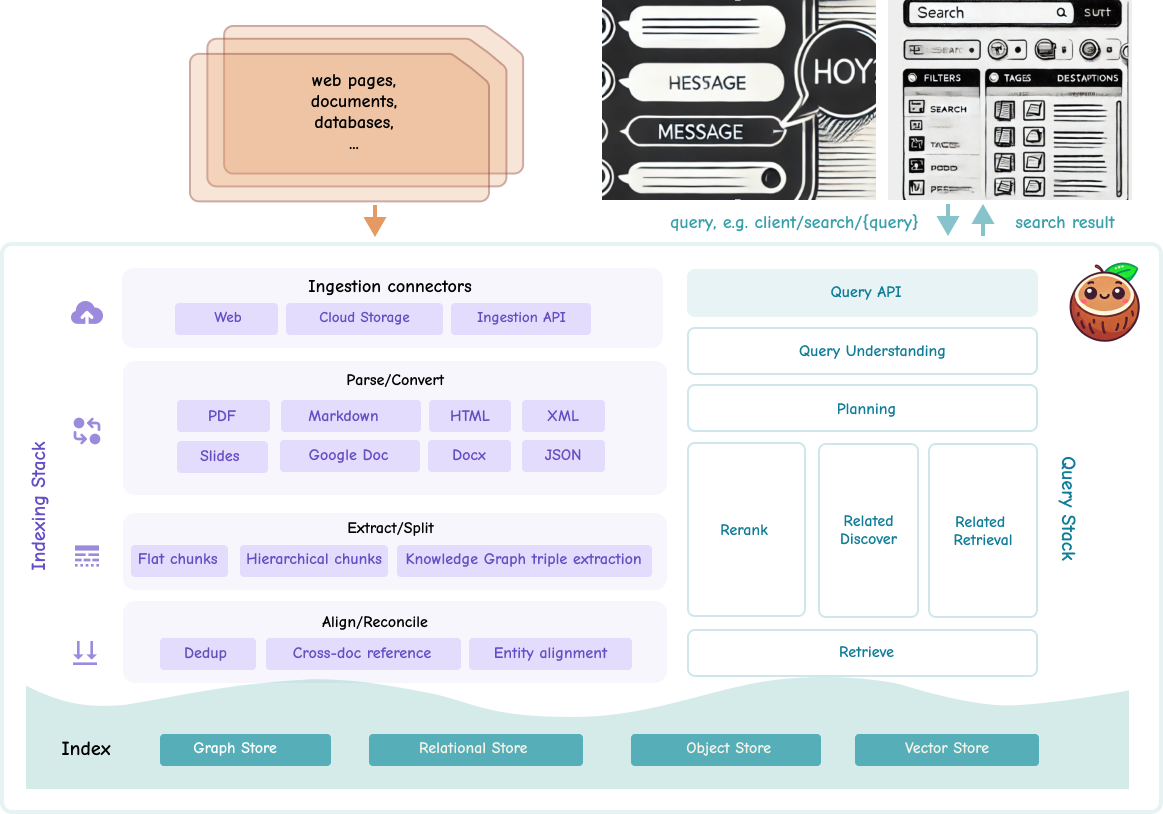
Discover how CocoIndex simplifies data indexing for AI applications. Learn about our comprehensive platform that handles data ingestion, processing, and management for RAG, semantic search, and other AI use cases.
Welcome to the official CocoIndex blog! We're excited to share our journey in building high-performance indexing infrastructure for AI applications.