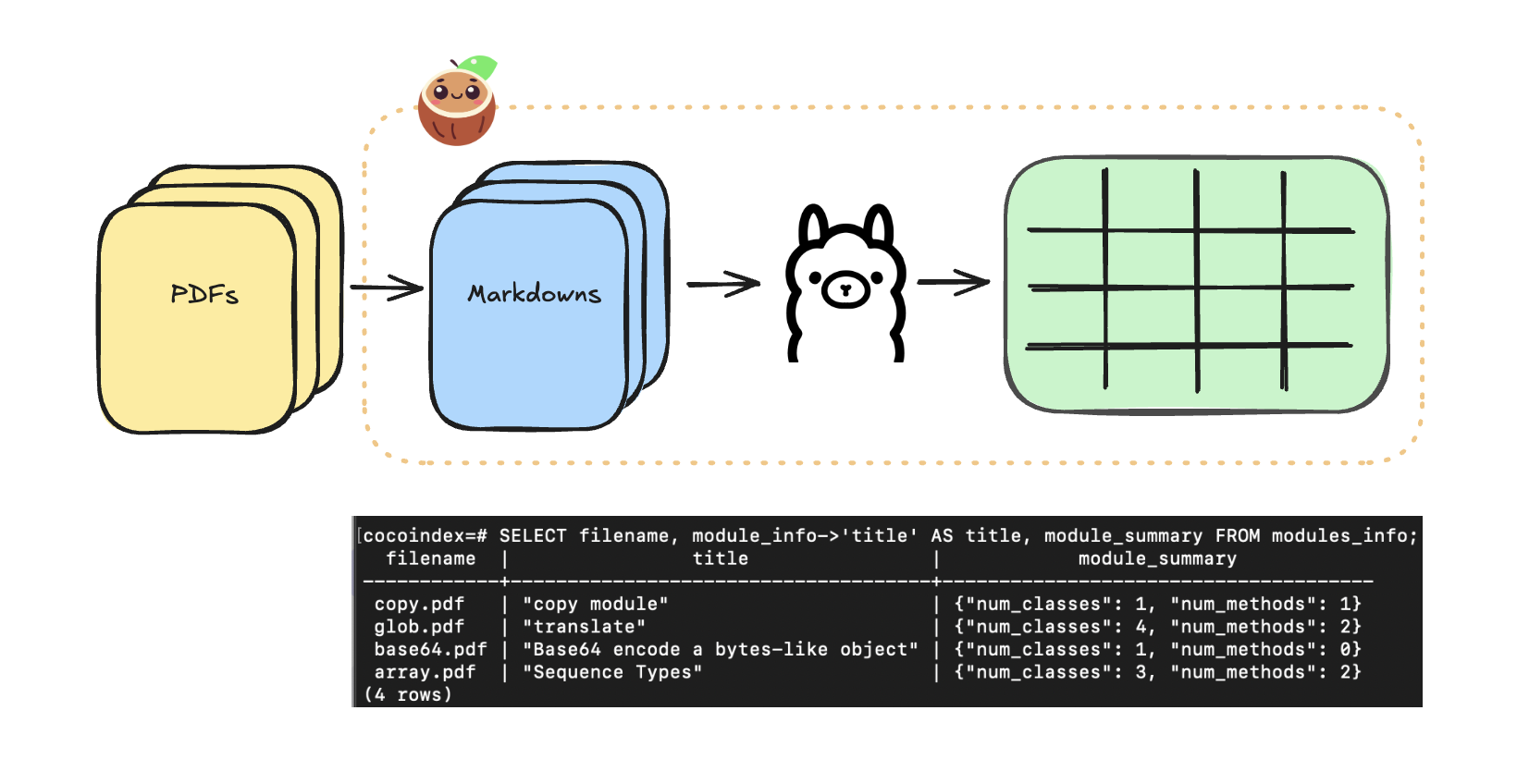
In this blog, we will show you how to use Ollama to extract structured data that you can run locally and deploy on your own cloud/server.
You can find the full code here. Only ~ 100 lines of Python code, check it out 🤗!
If you like this post and our work, please ⭐ star Cocoindex on Github to support us ❤️. Thank you so much with a warm coconut hug 🥥🤗.

Prerequisites
Install Postgres
If you don’t have Postgres installed, please refer to the installation guide.
Install ollama
Ollama allows you to run LLM models on your local machine easily. To get started:
Download and install Ollama. Pull your favorite LLM models by the ollama pull command, e.g.
ollama pull llama3.2Extract structured data from Markdown files
1. Define output
We are going to extract the following information from the Python Manuals as structured data.
So we are going to define the output data class as the following. The goal is to extract and populate ModuleInfo.
@dataclasses.dataclass
class ArgInfo:
"""Information about an argument of a method."""
name: str
description: str
@dataclasses.dataclass
class MethodInfo:
"""Information about a method."""
name: str
args: cocoindex.typing.List[ArgInfo]
description: str
@dataclasses.dataclass
class ClassInfo:
"""Information about a class."""
name: str
description: str
methods: cocoindex.typing.List[MethodInfo]
@dataclasses.dataclass
class ModuleInfo:
"""Information about a Python module."""
title: str
description: str
classes: cocoindex.typing.List[ClassInfo]
methods: cocoindex.typing.List[MethodInfo]2. Define cocoIndex Flow
Let’s define the cocoIndex flow to extract the structured data from markdowns, which is super simple.
First, let’s add Python docs in markdown as a source. We will illustrate how to load PDF a few sections below.
@cocoindex.flow_def(name="ManualExtraction")
def manual_extraction_flow(flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope):
data_scope["documents"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="markdown_files"))
modules_index = data_scope.add_collector()flow_builder.add_source will create a table with the following sub fields, see documentation here.
filename(key, type:str): the filename of the file, e.g.dir1/file1.mdcontent(type:strifbinaryisFalse, otherwisebytes): the content of the file
Then, let’s extract the structured data from the markdown files. It is super easy, you just need to provide the LLM spec, and pass down the defined output type.
CocoIndex provides builtin functions (e.g. ExtractByLlm) that process data using LLM. We provide built-in support for Ollama, which allows you to run LLM models on your local machine easily. You can find the full list of models here. We also support OpenAI API. You can find the full documentation and instructions here.
# ...
with data_scope["documents"].row() as doc:
doc["module_info"] = doc["content"].transform(
cocoindex.functions.ExtractByLlm(
llm_spec=cocoindex.LlmSpec(
api_type=cocoindex.LlmApiType.OLLAMA,
# See the full list of models: https://ollama.com/library
model="llama3.2"
),
output_type=ModuleInfo,
instruction="Please extract Python module information from the manual."))After the extraction, we just need to cherrypick anything we like from the output using the collect function from the collector of a data scope defined above.
modules_index.collect(
filename=doc["filename"],
module_info=doc["module_info"],
)Finally, let’s export the extracted data to a table.
modules_index.export(
"modules",
cocoindex.storages.Postgres(table_name="modules_info"),
primary_key_fields=["filename"],
)3. Query and test your index
🎉 Now you are all set!
Run the following command to setup and update the index.
cocoindex update -L mainYou’ll see the index updates state in the terminal
After the index is built, you have a table with the name modules_info. You can query it at any time, e.g., start a Postgres shell:
psql postgres://cocoindex:cocoindex@localhost/cocoindexAnd run the SQL query:
SELECT filename, module_info->'title' AS title, module_summary FROM modules_info;You can see the structured data extracted from the documents. Here’s a screenshot of the extracted module information:

CocoInsight
CocoInsight is a tool to help you understand your data pipeline and data index. CocoInsight is in Early Access now (Free) 😊 You found us! A quick 3 minute video tutorial about CocoInsight: Watch on YouTube.
1. Run the CocoIndex server
cocoindex server -ci mainto see the CocoInsight dashboard https://cocoindex.io/cocoinsight. It connects to your local CocoIndex server with zero data retention.
There are two parts of the CocoInsight dashboard:
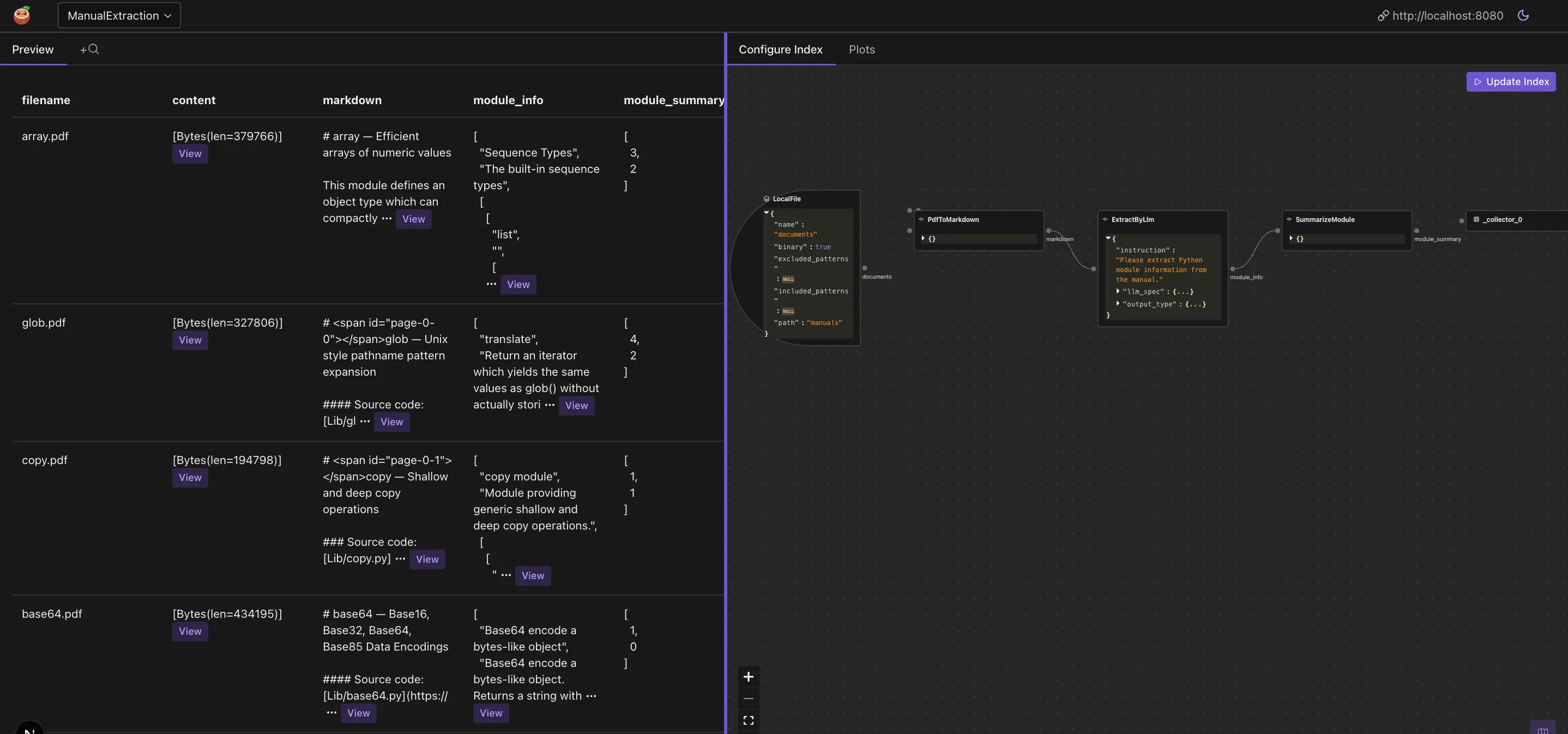
- Flows: You can see the flow you defined, and the data it collects.
- Data: You can see the data in the data index.
On the data side, you can click on any data and scroll down to see the details. In this data extraction example, you can see the data extracted from the markdown files and the structured data presented in tabular format.
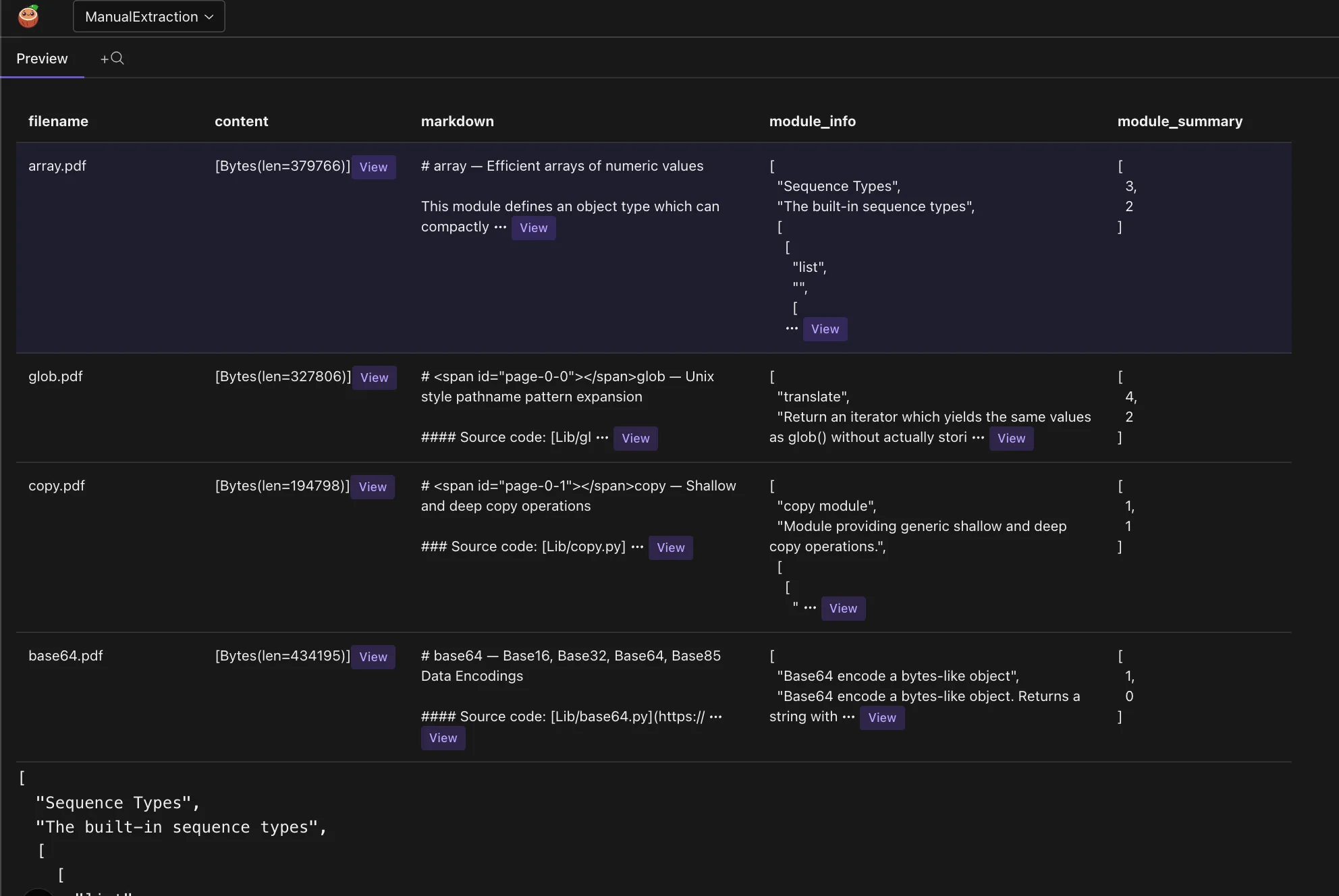
For example, for the array module, you can preview the data by clicking on the data.
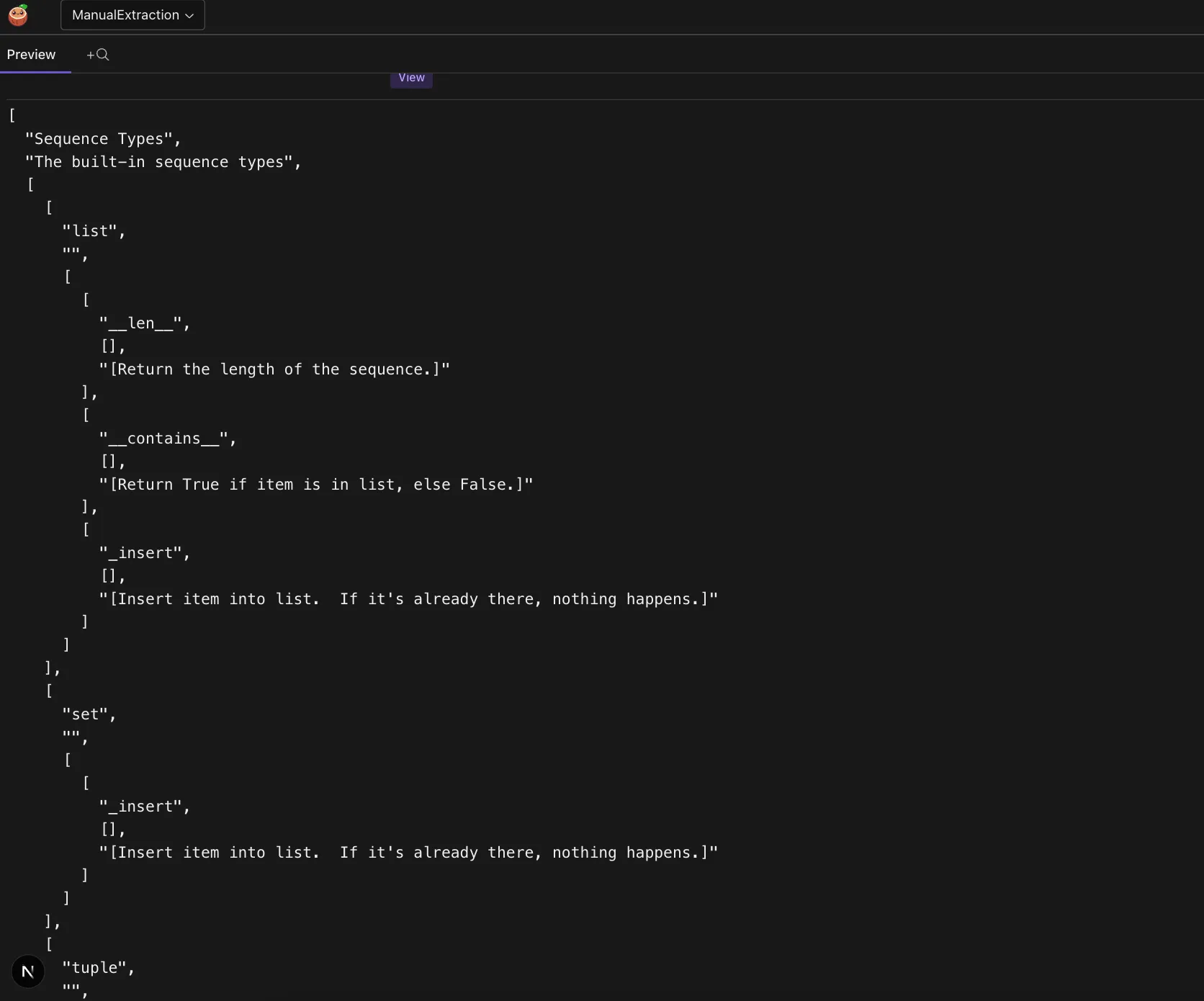
Lots of great updates coming soon, stay tuned!
Add summary to the data
Using cocoindex as framework, you can easily add any transformation on the data (including LLM summary), and collect it as part of the data index. For example, let’s add some simple summary to each module - like number of classes and methods, using simple Python funciton.
We will add a LLM example later.
1. Define output
First, let’s add the structure we want as part of the output definition.
@dataclasses.dataclass
class ModuleSummary:
"""Summary info about a Python module."""
num_classes: int
num_methods: int2. Define cocoIndex Flow
Next, let’s define a custom function to summarize the data. You can see detailed documentation here
@cocoindex.op.function()
def summarize_module(module_info: ModuleInfo) -> ModuleSummary:
"""Summarize a Python module."""
return ModuleSummary(
num_classes=len(module_info.classes),
num_methods=len(module_info.methods),
)3. Plug in the function into the flow
# ...
with data_scope["documents"].row() as doc:
# ... after the extraction
doc["module_summary"] = doc["module_info"].transform(summarize_module)🎉 Now you are all set!
Run the following command to setup and update the index.
cocoindex update --setup mainExtract structured data from PDF files
Ollama does not support PDF files directly as input, so we need to convert them to markdown first.
To do this, we can plugin a custom function to convert PDF to markdown. See the full documentation here.
1. Define a function spec
The function spec of a function configures behavior of a specific instance of the function.
class PdfToMarkdown(cocoindex.op.FunctionSpec):
"""Convert a PDF to markdown."""2. Define an executor class
The executor class is a class that implements the function spec. It is responsible for the actual execution of the function.
This class takes PDF content as bytes, saves it to a temporary file, and uses PdfConverter to extract the text content. The extracted text is then returned as a string, converting PDF to markdown format.
It is associated with the function spec by spec: PdfToMarkdown.
@cocoindex.op.executor_class(gpu=True, cache=True, behavior_version=1)
class PdfToMarkdownExecutor:
"""Executor for PdfToMarkdown."""
spec: PdfToMarkdown
_converter: PdfConverter
def prepare(self):
config_parser = ConfigParser({})
self._converter = PdfConverter(create_model_dict(), config=config_parser.generate_config_dict())
def __call__(self, content: bytes) -> str:
with tempfile.NamedTemporaryFile(delete=True, suffix=".pdf") as temp_file:
temp_file.write(content)
temp_file.flush()
text, _, _ = text_from_rendered(self._converter(temp_file.name))
return text
You may wonder why we want to define a spec + executor (instead of using a standalone function) here. The main reason is there’re some heavy preparation work (initialize the parser) needs to be done before being ready to process real data.
3. Plugin it to the flow
# Note the binary = True for PDF
data_scope["documents"] = flow_builder.add_source(cocoindex.sources.LocalFile(path="manuals", binary=True))
modules_index = data_scope.add_collector()
with data_scope["documents"].row() as doc:
# plug in your custom function here
doc["markdown"] = doc["content"].transform(PdfToMarkdown())
🎉 Now you are all set!
Run the following command to setup and update the index.
cocoindex update --setup mainCommunity
We love to hear from the community! You can find us on Github and Discord.
If you like this post and our work, please ⭐ star Cocoindex on Github to support us. Thank you with a warm coconut hug 🥥🤗.

CocoIndex
An incremental engine for long-horizon agents — always-fresh, explainable data, one Python file.
About the author.

Posts from the CocoIndex team — product launches, release notes, and announcements.