Build Real-Time Product Recommendation Engine with LLM and Graph Database

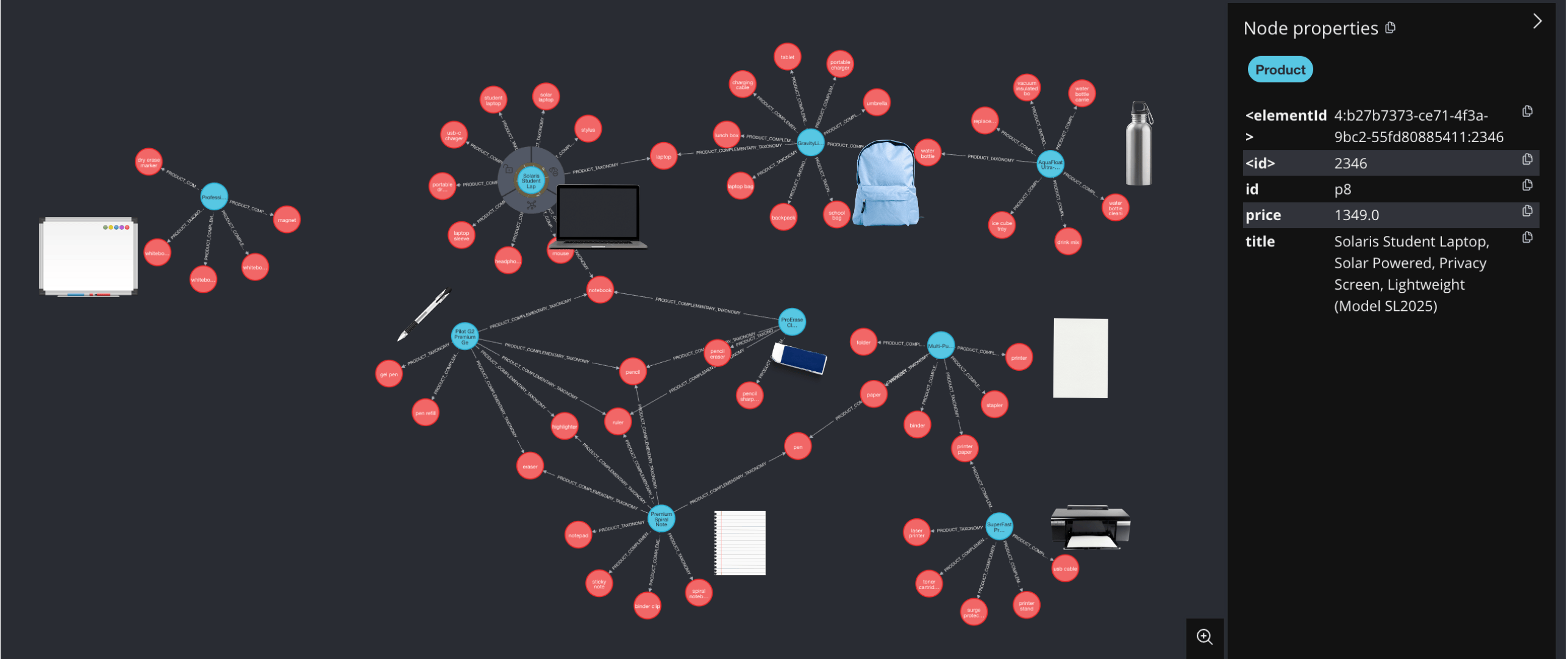
In this blog, we will build a real-time product recommendation engine with LLM and graph database. In particular, we will use LLM to understand the category (taxonomy) of a product. In addition, we will use LLM to enumerate the complementary products - users are likely to buy together with the current product (pencil and notebook). We will use Graph to explore the relationships between products that can be further used for product recommendations or labeling.
We are constantly improving, and more features and examples are coming soon. Stay tuned and follow our progress by starring our GitHub repo.
Product taxonomy is a way to organize product catalogs in a logical and hierarchical structure; a great detailed explanation can be found here. In practice, it is a complicated problem: a product can be part of multiple categories, and a category can have multiple parents.
The source code is available at Product Recommendation Code.
Prerequisites
- Install PostgreSQL. CocoIndex uses PostgreSQL internally for incremental processing.
- Install Neo4j, a graph database.
- Configure your OpenAI API key. Alternatively, you can switch to Ollama, which runs LLM models locally - guide.
Documentation
You can read the official CocoIndex Documentation for Property Graph Targets here.
Data flow to build knowledge graph
Overview
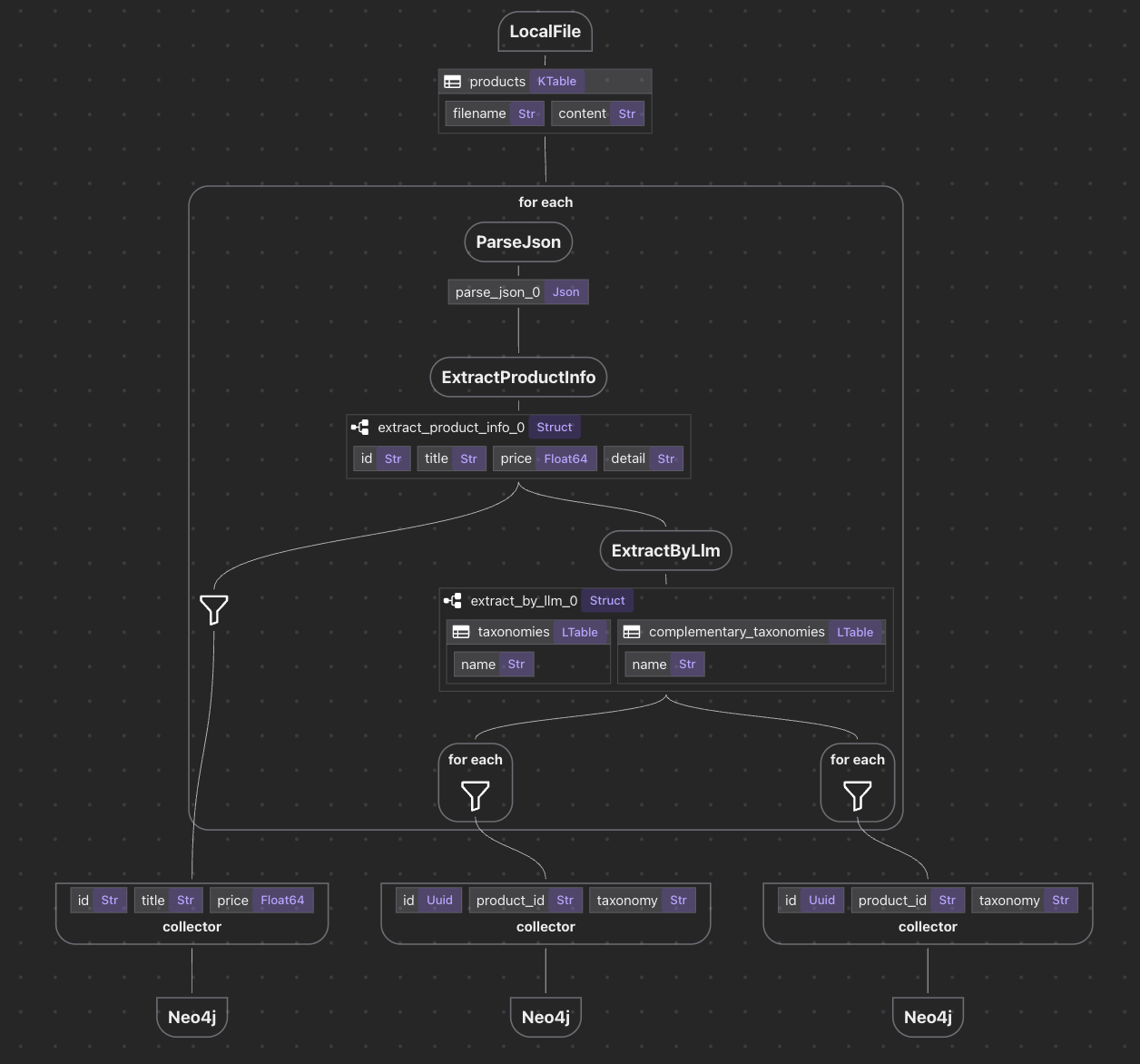
The core flow is about ~100 lines of python code
We are going to declare a data flow
- ingest products (in JSON)
- for each product,
- parse JSON
- map & clean up data
- extract taxonomy from the mapped data
- collect data
- export data to neo4j
Add documents as source
@cocoindex.flow_def(name="StoreProduct")
def store_product_flow(flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope):
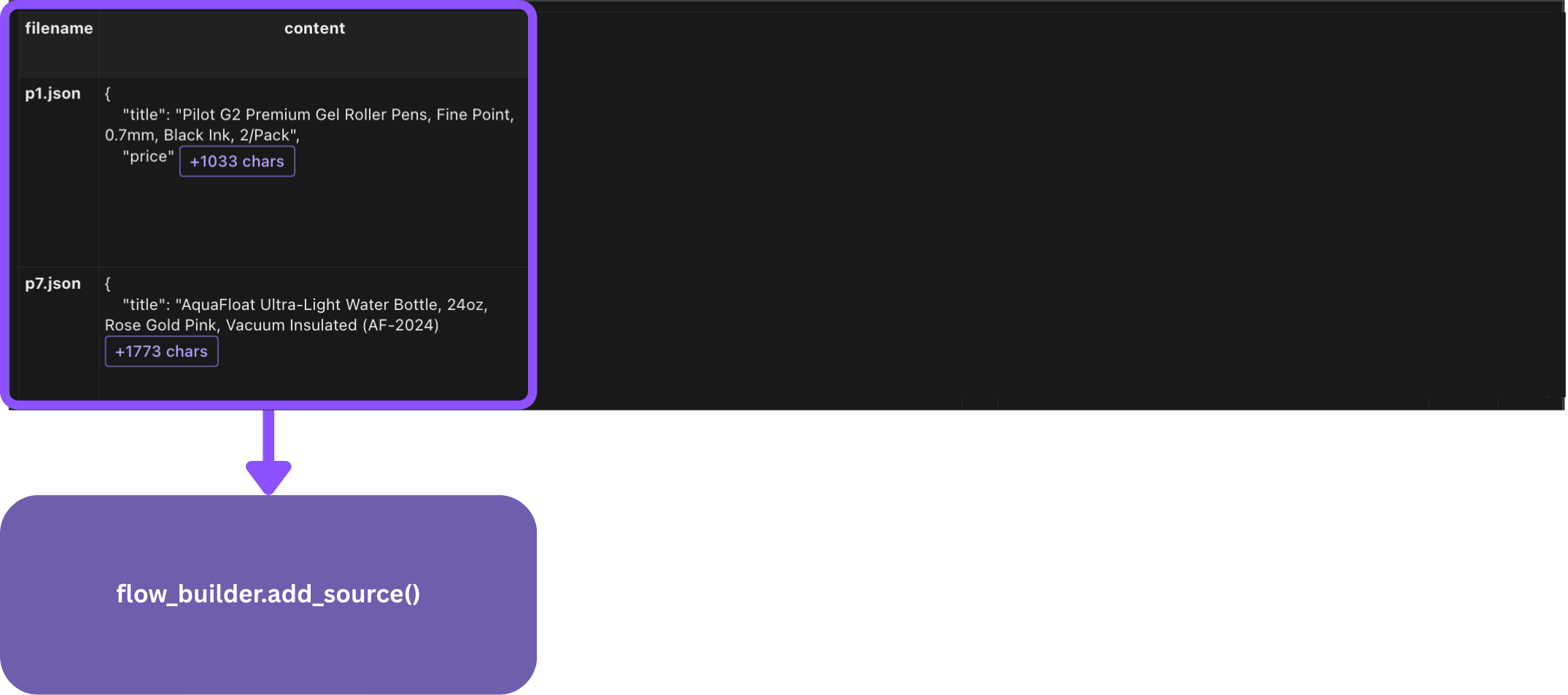
data_scope["products"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="products",
included_patterns=["*.json"]),
refresh_interval=datetime.timedelta(seconds=5))
Here flow_builder.add_source creates a KTable.
filename is the key of the KTable.
Add data collectors
Add collectors at the root scope to collect the product, taxonomy and complementary taxonomy.
product_node = data_scope.add_collector()
product_taxonomy = data_scope.add_collector()
product_complementary_taxonomy = data_scope.add_collector()
Process each product
We will parse the JSON file for each product, and transform the data to the format that we need for downstream processing.
Data mapping
@cocoindex.op.function(behavior_version=2)
def extract_product_info(product: cocoindex.typing.Json, filename: str) -> ProductInfo:
return ProductInfo(
id=f"{filename.removesuffix('.json')}",
url=product["source"],
title=product["title"],
price=float(product["price"].lstrip("$").replace(",", "")),
detail=Template(PRODUCT_TEMPLATE).render(**product),
)
Here we define a function for data mapping, e.g.,
- clean up the
idfield - map
title->title - clean up the
pricefield - generate a markdown string for the product detail based on all the fields (for LLM to extract taxonomy and complementary taxonomy, we find that markdown works best as context for LLM).
Flow
Within the flow, we plug in the data mapping transformation to process each product JSON.
with data_scope["products"].row() as product:
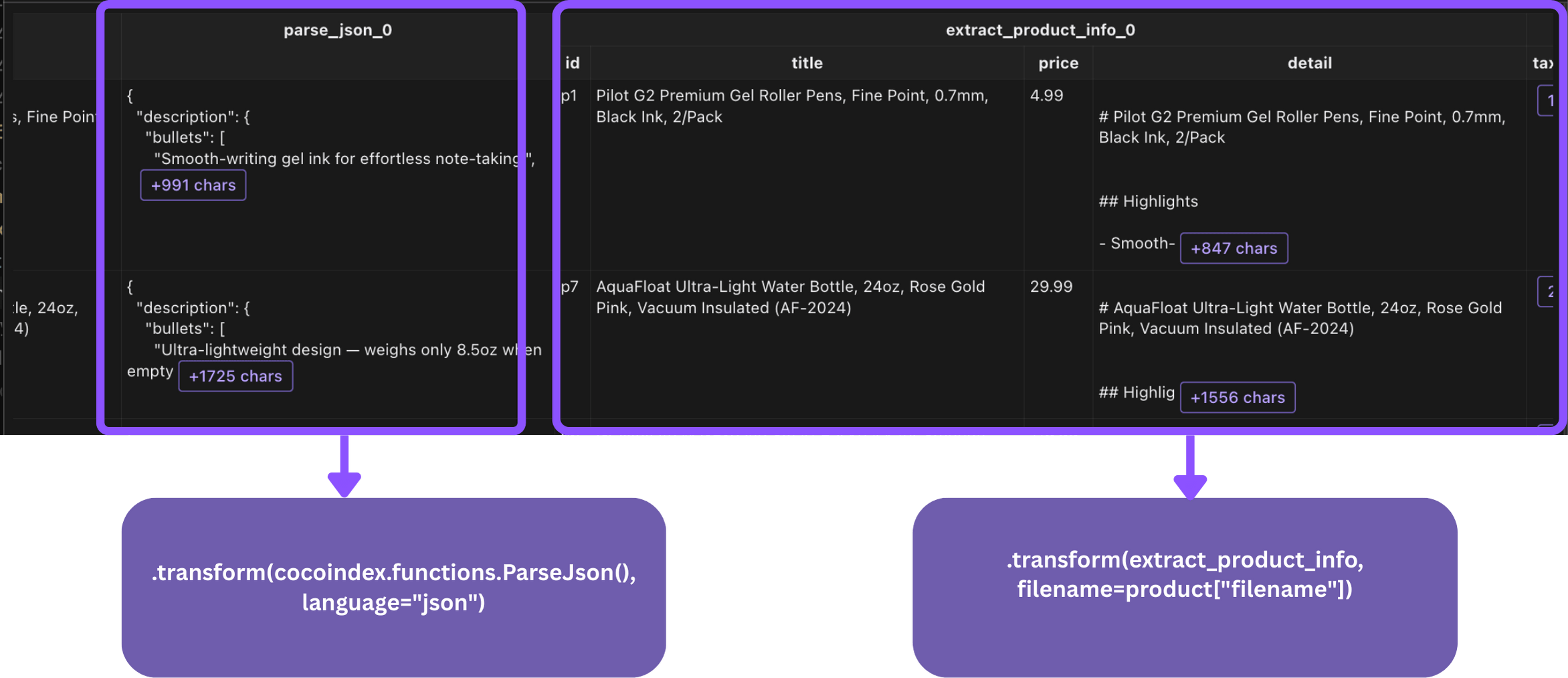
data = (product["content"]
.transform(cocoindex.functions.ParseJson(), language="json")
.transform(extract_product_info, filename=product["filename"]))
product_node.collect(id=data["id"], url=data["url"], title=data["title"], price=data["price"])
- The first
transform()parses the JSON file. - The second
transform()performs the defined data mapping. - We collect the fields we need for the product node in Neo4j.
Extract taxonomy and complementary taxonomy using LLM
Product taxonomy definition
Since we are using LLM to extract product taxonomy, we need to provide a detailed instruction at the class-level docstring.
@dataclasses.dataclass
class ProductTaxonomy:
"""
Taxonomy for the product.
A taxonomy is a concise noun (or short noun phrase), based on its core functionality, without specific details such as branding, style, etc.
Always use the most common words in US English.
Use lowercase without punctuation, unless it's a proper noun or acronym.
A product may have multiple taxonomies. Avoid large categories like "office supplies" or "electronics". Use specific ones, like "pen" or "printer".
"""
name: str
Define product taxonomy info
Basically we want to extract all possible taxonomies for a product, and think about what other products are likely to be bought together with the current product.
@dataclasses.dataclass
class ProductTaxonomyInfo:
"""
Taxonomy information for the product.
Fields:
- taxonomies: Taxonomies for the current product.
- complementary_taxonomies: Think about when customers buy this product, what else they might need as complementary products. Put labels for these complentary products.
"""
taxonomies: list[ProductTaxonomy]
complementary_taxonomies: list[ProductTaxonomy]
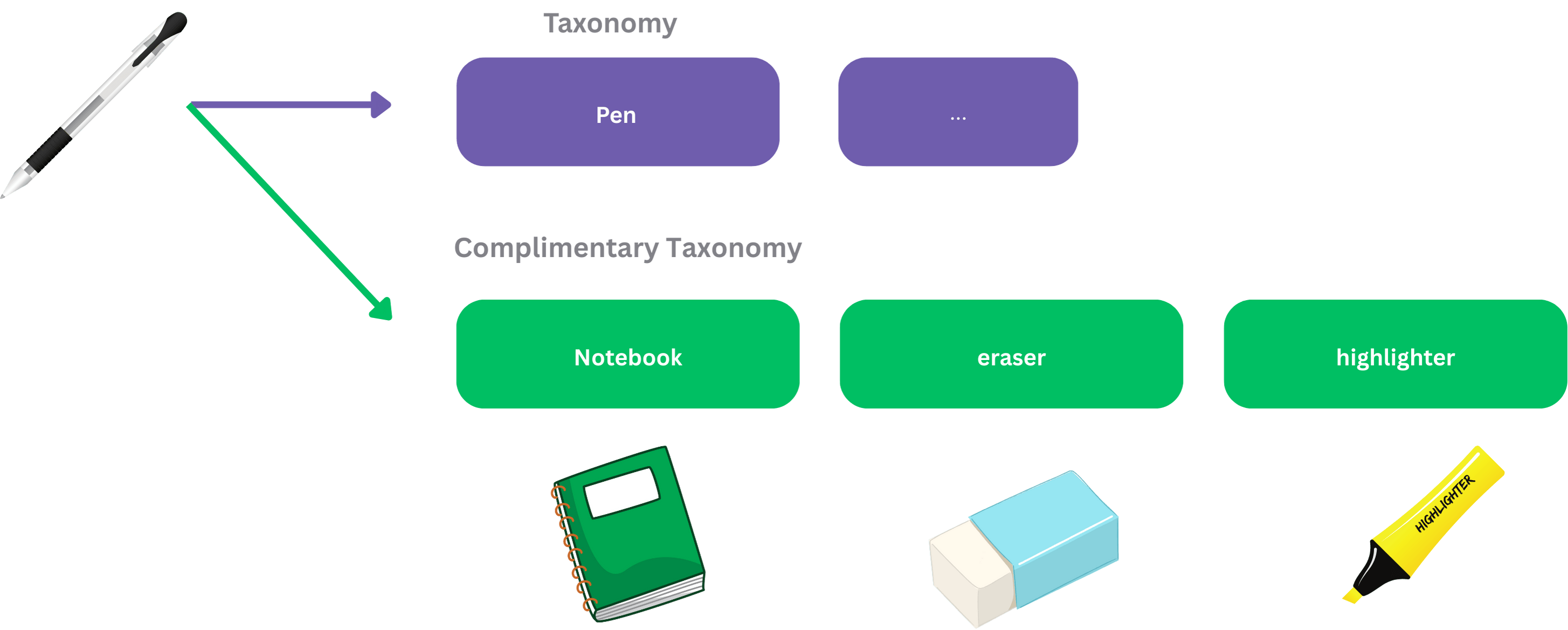
For each product, we want some insight about its taxonomy and complementary taxonomy and we could use that as bridge to find related product using knowledge graph.
LLM extraction
Finally, we will use cocoindex.functions.ExtractByLlm to extract the taxonomy and complementary taxonomy from the product detail.
taxonomy = data["detail"].transform(cocoindex.functions.ExtractByLlm(
llm_spec=cocoindex.LlmSpec(
api_type=cocoindex.LlmApiType.OPENAI, model="gpt-4.1"),
output_type=ProductTaxonomyInfo))
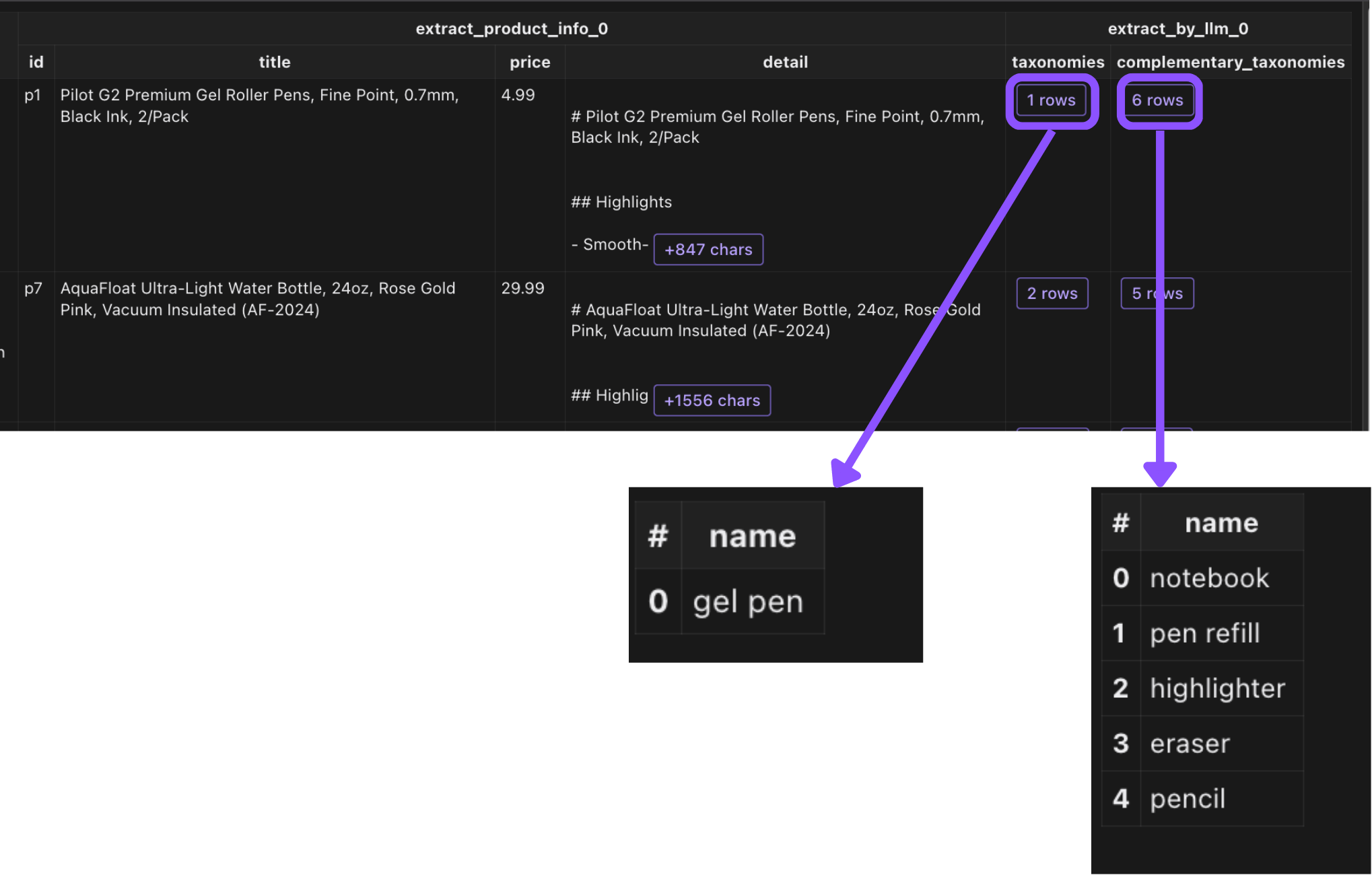
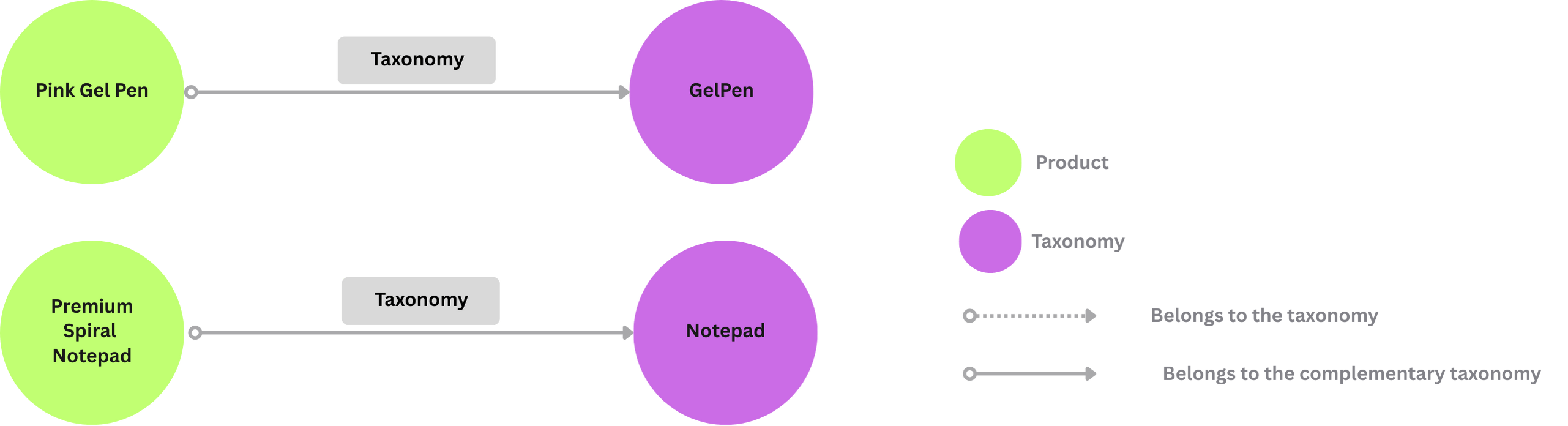
For example, LLM takes the description of the gel pen, and extracts taxonomy to be gel pen. Meanwhile, it suggests that when people buy gel pen, they may also be interested in notebook etc as complimentary taxonomy.
And then we will collect the taxonomy and complementary taxonomy to the collector.
with taxonomy['taxonomies'].row() as t:
product_taxonomy.collect(id=cocoindex.GeneratedField.UUID, product_id=data["id"], taxonomy=t["name"])
with taxonomy['complementary_taxonomies'].row() as t:
product_complementary_taxonomy.collect(id=cocoindex.GeneratedField.UUID, product_id=data["id"], taxonomy=t["name"])
Build knowledge graph
Basic concepts
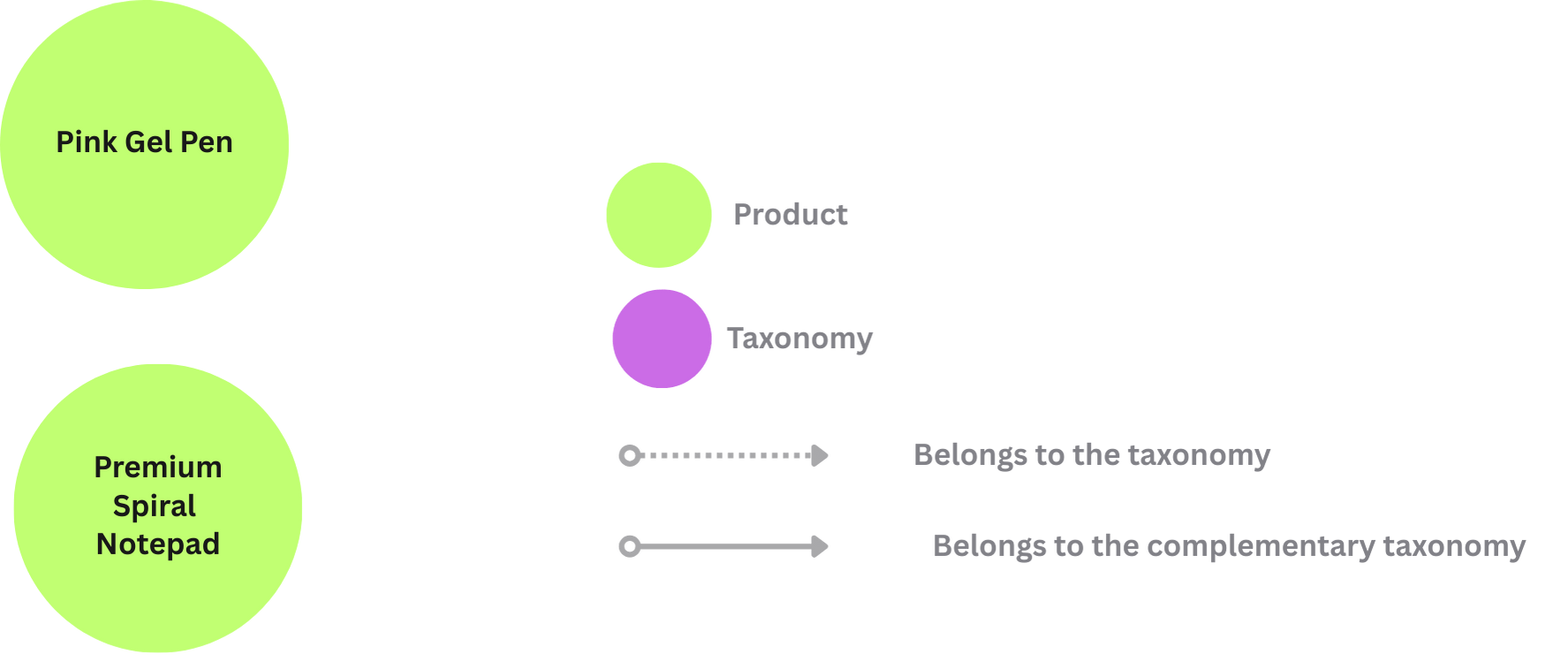
All nodes for Neo4j need two things:
- Label: The type of the node. E.g.,
Product,Taxonomy. - Primary key field: The field that uniquely identifies the node. E.g.,
idforProductnodes.
CocoIndex uses the primary key field to match the nodes and deduplicate them. If you have multiple nodes with the same primary key, CocoIndex keeps only one of them.
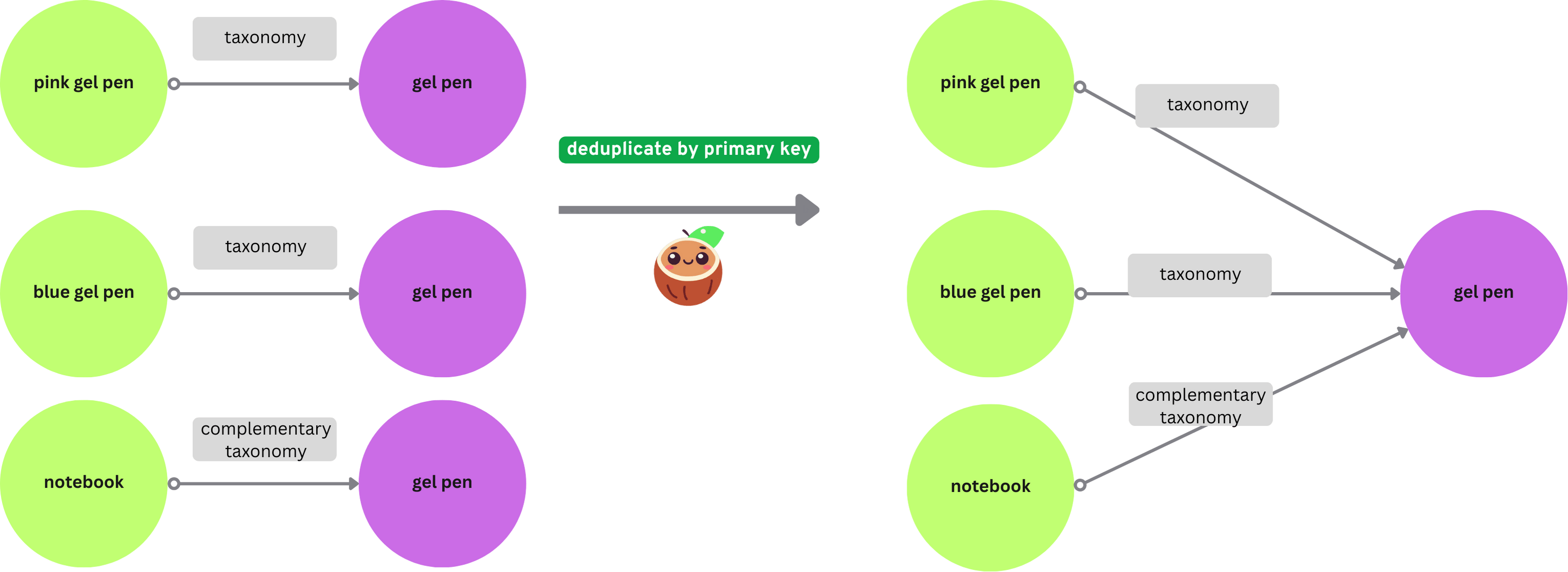
There are two ways to map nodes:
- When you have a collector just for the node, you can directly export it to Neo4j. For example
Product. We've collected each product explicitly. - When you have a collector for relationships connecting to the node, you can map nodes from selected fields in the relationship collector. You must declare a node label and primary key field.
For example,
product_taxonomy.collect(id=cocoindex.GeneratedField.UUID, product_id=data["id"], taxonomy=t["name"])
Collects a relationship, and taxonomy node is created from the relationship.
Configure Neo4j connection:
conn_spec = cocoindex.add_auth_entry(
"Neo4jConnection",
cocoindex.storages.Neo4jConnection(
uri="bolt://localhost:7687",
user="neo4j",
password="cocoindex",
))
Export Product nodes to Neo4j
product_node.export(
"product_node",
cocoindex.storages.Neo4j(
connection=conn_spec,
mapping=cocoindex.storages.Nodes(label="Product")
),
primary_key_fields=["id"],
)
This exports Neo4j nodes with label Product from the product_node collector.
- It declares Neo4j node label
Product. It specifiesidas the primary key field. - It carries all the fields from
product_nodecollector to Neo4j nodes with labelProduct.
Export Taxonomy nodes to Neo4j
We don't have explicit collector for Taxonomy nodes.
They are part of the product_taxonomy and product_complementary_taxonomy collectors and fields are collected during the taxonomy extraction.
To export them as Neo4j nodes, we need to first declare Taxonomy nodes.
flow_builder.declare(
cocoindex.storages.Neo4jDeclaration(
connection=conn_spec,
nodes_label="Taxonomy",
primary_key_fields=["value"],
)
)
Next, export the product_taxonomy as relationship to Neo4j.
product_taxonomy.export(
"product_taxonomy",
cocoindex.storages.Neo4j(
connection=conn_spec,
mapping=cocoindex.storages.Relationships(
rel_type="PRODUCT_TAXONOMY",
source=cocoindex.storages.NodeFromFields(
label="Product",
fields=[
cocoindex.storages.TargetFieldMapping(
source="product_id", target="id"),
]
),
target=cocoindex.storages.NodeFromFields(
label="Taxonomy",
fields=[
cocoindex.storages.TargetFieldMapping(
source="taxonomy", target="value"),
]
),
),
),
primary_key_fields=["id"],
)
Similarly, we can export the product_complementary_taxonomy as relationship to Neo4j.
product_complementary_taxonomy.export(
"product_complementary_taxonomy",
cocoindex.storages.Neo4j(
connection=conn_spec,
mapping=cocoindex.storages.Relationships(
rel_type="PRODUCT_COMPLEMENTARY_TAXONOMY",
source=cocoindex.storages.NodeFromFields(
label="Product",
fields=[
cocoindex.storages.TargetFieldMapping(
source="product_id", target="id"),
]
),
target=cocoindex.storages.NodeFromFields(
label="Taxonomy",
fields=[
cocoindex.storages.TargetFieldMapping(
source="taxonomy", target="value"),
]
),
),
),
primary_key_fields=["id"],
)
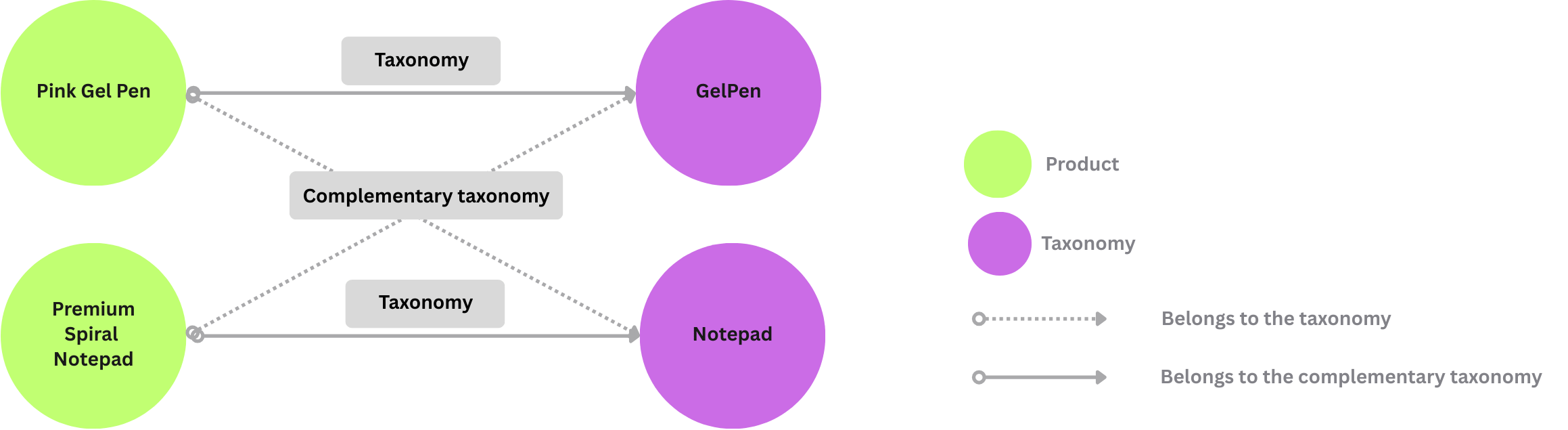
The cocoindex.storages.Relationships declares how to map relationships in Neo4j.
In a relationship, there's:
- A source node and a target node.
- A relationship connecting the source and target. Note that different relationships may share the same source and target nodes.
NodeFromFields takes the fields from the entity_relationship collector and creates Taxonomy nodes.
Query and test your index
🎉 Now you are all set!
-
Install the dependencies:
pip install -e . -
Run the following command to setup and update the index.
cocoindex update --setup mainYou'll see the index updates state in the terminal. For example, you'll see the following output:
documents: 9 added, 0 removed, 0 updated -
(Optional) I used CocoInsight to troubleshoot the index generation and understand the data lineage of the pipeline. It is in free beta now, you can give it a try. Run following command to start CocoInsight:
cocoindex server -ci mainAnd then open the url https://cocoindex.io/cocoinsight. It just connects to your local CocoIndex server, with Zero pipeline data retention.
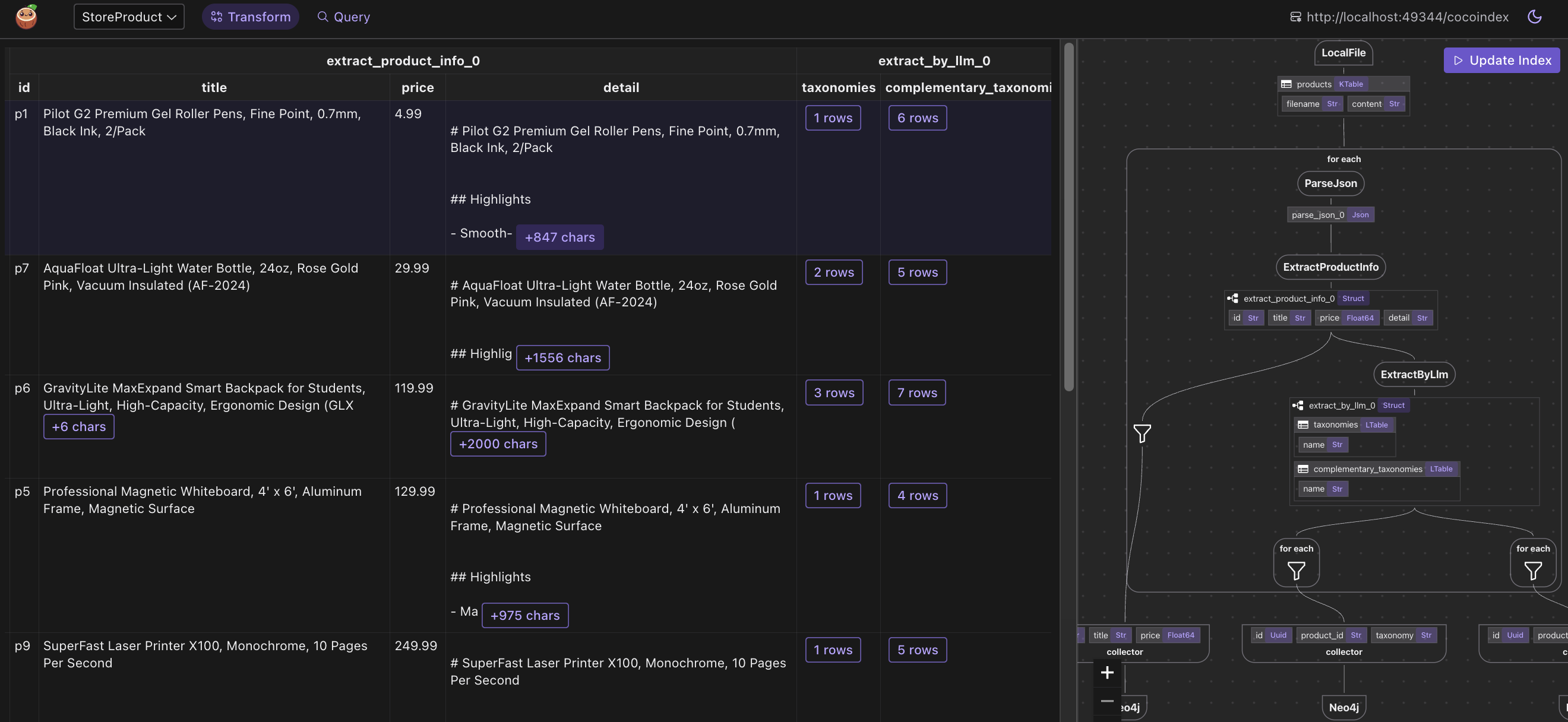
Browse the knowledge graph
After the knowledge graph is built, you can explore the knowledge graph you built in Neo4j Browser.
For the dev environment, you can connect to Neo4j browser using credentials:
- username:
Neo4j - password:
cocoindexwhich is pre-configured in our docker compose config.yaml.
You can open it at http://localhost:7474, and run the following Cypher query to get all relationships:
MATCH p=()-->() RETURN p
Support us
We are constantly improving, and more features and examples are coming soon. If you love this article, please give us a star ⭐ at GitHub repo to help us grow.
Thanks for reading!