CocoIndex Changelog 2025-07-07


In the past weeks, we've added support for in-process API and convenient CLI options for setup / drop, native support for EmbedText as building block, major improvement to support codebase indexing and many core improvements over 10+ releases.
We are also very excited about the great suggestions from our users and community, and many of our changes come directly from user feedback. Thank you ❤️!
Full changelog: v0.1.45...v0.1.57.
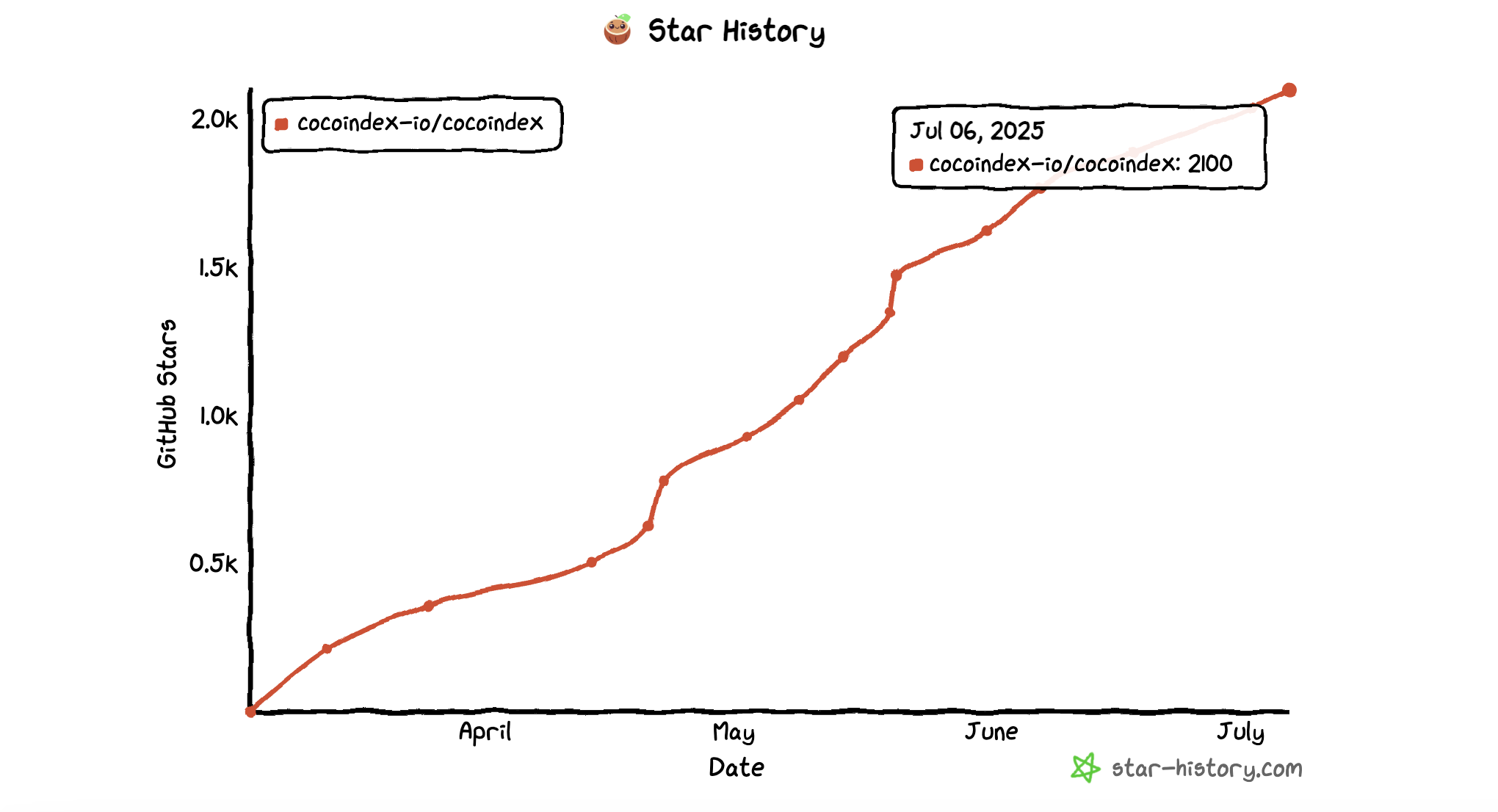
We officially crossed 2k stars on GitHub! 🎉
CocoIndex Crossed 2k stars last week with one day on Github Trending in Rust. Thank you everyone who contributed, starred the repo and shared the love! Let’s making the best ETL framework for AI 🚀 !
CocoInsight
We had announced a major milestone on CocoIndex companion - CocoInsight.
It has zero pipeline data retention and connects to your on-premise CocoIndex server for pipeline insights.
This makes data directly visible and easy to develop ETL pipelines.
Flexible API for flow backend setup / drop
CocoIndex automatically handles the flow setup - keeping everything in sync for the target stores (e.g., Qdrant, Postgres) automatically without explicit schema setup, all inferred from the flow itself.
As a follow-up, we've provided in-process API and convenient CLI options for setup / drop.
Previously, automatic flow backend setup / drop was only supported by cocoindex setup and cocoindex drop CLI commands.
This was less flexible and convenient:
- This must happen as a separate process.
setupworks for all loaded flows, but doesn't work for a single flow.
These limitations came from simplification of our early implementation. We rebuilt the related logic and supported lightweight in-process API for flow backend setup and drop.
With the new change, your can run
flow1.setup() # Apply setup updates for flow1. It's noop if already up-to-date.
flow1.drop() # Drop the setup for flow1
# We also support doing it for all
cocoindex.setup_all()
cocoindex.drop_all()
With this, you can programmatically setup your flow in your code before using the update() API to build the index:
flow1.setup()
flow1.update()
In addition, cocoindex update CLI starts to support a --setup option, which automatically pushes setup changes
before running the flow in the same CLI invocation.
cocoindex update --setup main
See the document for more details.
This is a major framework update — we've made significant improvements to state management, including smarter handling of when to load global metadata, when to trigger setup, and how each component updates. We're committed to taking care of the underlying infrastructure so developers can focus on what matters: the data and the logic.
New building block: EmbedText
CocoIndex provides native builtins for different sources, targets and transformations, based on standardize interface. Components can be switched by one-line code change.
We are committed to making it convenient to plugin the best from ecosystem seamlessly.
EmbedText embeds text into a vector space using various LLM APIs that support text embedding.
It has native OpenAI, Gemini, and Voyage support.
You can view more about EmbedText in this documentation.
Example:
text.transform(
cocoindex.functions.EmbedText(
api_type=cocoindex.LlmApiType.VOYAGE,
model="voyage-code-3",
)
)
Optimization: skip source row reprocessing on unchanged content hash
CocoIndex supports incremental processing out-of-the-box that only reprocesses what's changed at minimum. It can be at a source level, or during a transformation, e.g., a few chunks in a document have changed.
This improvement saves reprocessing cost when the content of a source row doesn't change. Previously we used an ordinal (e.g. based on file modification time for file-based sources) to determine if there's content change. Sometimes modification time changes without content change (e.g. Git always uses the current time after checkout), and we want to skip processing in this case too.
Major improvements on SplitRecursively function
We've made major improvements on native support for SplitRecursively (for chunking) building blocks.
- Holistically planning the way of chunking to minimize "cost", considering the following factors:
- AST structural level
- Literal styles (new lines, double new lines)
- Efficiency of overlap leverage
- Also for non-dividable elements (e.g. large comments, large strings), fallback to regex-based text chunking
- Add line/column to output of
SplitRecursively - Support customizing separators for the splitter
Checkout this example of how to use SplitRecursively to index codebase:
codebase-indexing.
Union types
We’ve added support for union type for basic types.
Union types are supported in Python (e.g. str | int).
you can read more about union types here.
NumPy type support
CocoIndex started to support NumPy numeric types and array types in CocoIndex functions. Specifically:
numpy.int64: binds to Int64numpy.float32: binds to Float32numpy.float64: binds to Float64numpy.typing.NDArray[T], whereTis any NumPy numeric type above: binds to Vector
See the document for more details.
Supporting more LLM APIs
We’ve added LiteLLM (Proxy), OpenRouter Support, read more here.
New target store - Kuzu
CocoIndex now provides native support for Kuzu as a target graph data store. This integration features a high performance knowledge graph stack with real-time updates. You can read more here.
Thanks to the community
Welcome new contributors to the CocoIndex community! We are so excited to have you!
@lemorage

Thanks to @lemorage for the contributions! CocoIndex has received a series of high-quality PRs from him, and we truly appreciate his excellent work and passion for the project. @lemorage has also been helping us keeping the repo healthy as first responders to breaking changes. Thank you so much!
- use theme aligning with user system preferences #572
- feat: add NumPy array support for vector representations #586
- fix: remove unsupported type casting in integer vector handling #619
- feat: support scalar NumPy value encodings #620
- ops: add pre-commit and hooks for code checking #641
@vumichien

Thanks to @vumichien for the contributions — especially PR #629, which tackles some complex and core aspects of CocoIndex. We really appreciate the thoughtful work and sustained effort over the past few weeks.
- chore: update Rust version to 1.86 and remove unused
as_anymethods #597 - feat(cli): add force option to setup and drop commands for bypassing confirmation prompts #602
- feat: allow optional database configuration #608
- feat: add content hash support for change detection in source processing #629
@chardoncs

Thanks to @chardoncs for the contributions! We appreciate the work on supporting union types for basic types.
- feat: support union type for basic types #510
@par4m

Thanks to @par4m for the contributions! We appreciate the work on adding LiteLLM and OpenRouter support, which gives users more flexibility to pick their favorite models.
@cijiugechu

Thanks to @cijiugechu for the contributions! We appreciate the work on performance optimizations.
- chore(example): replace deprecated startup event with
lifespan#590 - chore(server): upgrade to
axum0.8 #591 - perf(google_drive): generate
EXPORT_MIME_TYPESat compile time #593
@theparthgupta

Thanks to @theparthgupta for the contributions! We appreciate the work on making sentence_transformers an optional dependency, which helps reduce the base package size and gives users more flexibility.
- feat: make sentence_transformers an optional dependency #674
@dubin555

Thanks to @dubin555 for the contributions! We appreciate the work on improving logging information.
- chore: add more info in log #614
@TwistingTwists

Thanks to @TwistingTwists for the contributions! We appreciate the work on improving unit tests for Python values.
- fix: unit tests for python values #452
@SaiSakthidar

Thanks to @SaiSakthidar for the contributions! We appreciate the work on migrating custom UUID conversion logic to pyo3.uuid package, which improves code maintainability.
- feat: Migrated custom UUID conversion logic to pyo3.uuid package #663
Support our work
We are constantly improving CocoIndex, more features are coming soon! Stay tuned and follow us by starring our GitHub repo.