
In the past weeks, we’ve added support for Amazon S3 as native data source, updated query handling, and many core improvements in performance and stability over 15 releases. We’re all in on building the best real-time incremental data framework — and we couldn’t be more excited.
Full changelog: v0.1.30…v0.1.44.
Amazon S3 and Amazon Simple Queue Service (SQS) as native data source
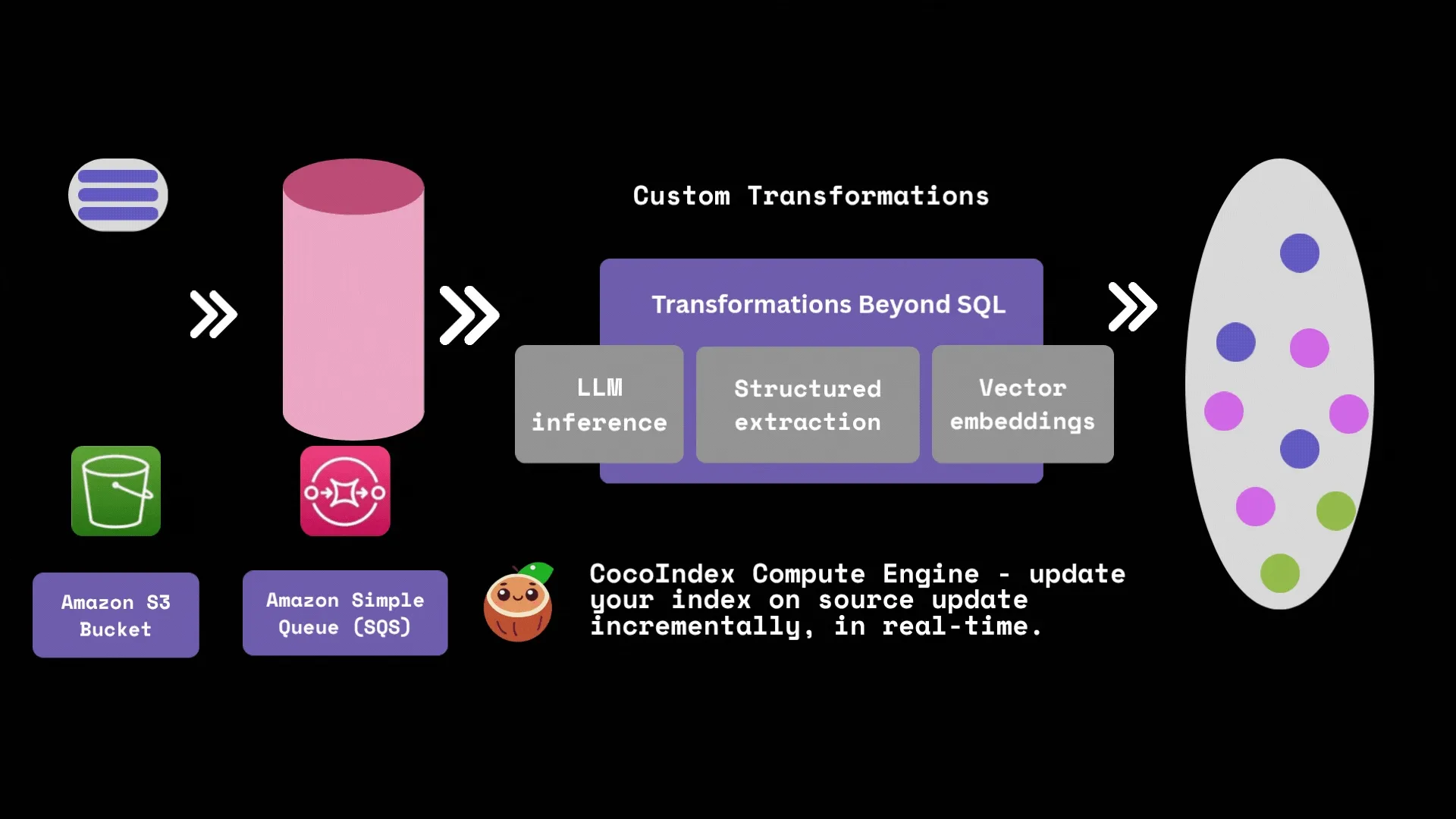
CocoIndex now natively supports Amazon S3 as a data source, allowing seamless integration with your storage. Combined with support for AWS Simple Queue Service (SQS), CocoIndex enables true real-time, incremental processing of data as it’s updated in S3.
CocoIndex processes only S3 files that have been newly added or updated, reducing unnecessary compute cycles and improving overall system efficiency. Incremental processing focuses on handling only new or modified data since previous run, rather than reprocessing entire dataset every time. It becomes essential when working with large-scale data or when up-to-date information is critical.
- Read more about this integration in the blog post.
- Get started now with the example.
- Documentation: Amazon S3 as a data source
Query stack
On the query side, CocoIndex has removed support for SimpleQueryHandler.
We made this decision because:
- Flexibility - users directly talk to the database to have maximum control. Users often have specific requirements for query handling, such as custom filtering and search logic.
- Many databases already have optimized query implementations with their own best practices
- The query space has excellent solutions for querying, reranking, and other search-related functionality.
And we’re doubling down on what we do best: real-time indexing + transformation.
Here are some examples with query server:
Transform flow
When building vector indexes and querying against them, you often need to share transformation logic between indexing and querying operations. For instance, the embedding computation must remain consistent across both processes.
In this case, you can
-
Extract a sub-flow with the shared transformation logic into a standalone function. E.g.,
def text_to_embedding(text: cocoindex.DataSlice[str]) -> cocoindex.DataSlice[list[float]]: return text.transform( cocoindex.functions.SentenceTransformerEmbed( model="sentence-transformers/all-MiniLM-L6-v2")) -
When you’re defining your indexing flow, you can directly call the function. E.g.,
with doc["chunks"].row() as chunk: chunk["embedding"] = text_to_embedding(chunk["text"]) -
At query time, you usually want to directly run the function with specific input data, instead of letting it called as part of a long-lived indexing flow. To do this, declare the function as a transform flow, by decorating it with
@cocoindex.transform_flow().@cocoindex.transform_flow() def text_to_embedding(text: cocoindex.DataSlice[str]) -> cocoindex.DataSlice[list[float]]: return text.transform( cocoindex.functions.SentenceTransformerEmbed( model="sentence-transformers/all-MiniLM-L6-v2"))So that you can directly call it with specific input data.
print(text_to_embedding.eval("Hello, world!"))
Learn more about transform flow in the documentation.
New standalone CLI
CocoIndex now supports standalone CLI, with cleaner CLI commands and tons of improvements.
You have two ways to launch CocoIndex, see the Documentation to launch CocoIndex for more details.
-
Use Cocoindex CLI. It’s handy for most routine indexing building and management tasks. It will load settings from environment variables, either already set in your environment, or specified in
.envfile. Check out the CLI documentation for more details.For example:
cocoindex setup maincocoindex update main -
Call CocoIndex functionality from your own Python application or library. For example:
from dotenv import load_dotenv import cocoindex load_dotenv() cocoindex.init()It’s needed when you want to leverage CocoIndex support for query, or have your custom logic to trigger indexing, etc. Check out the full example here.
Support app namespace
CocoIndex now supports application namespaces, making it easier to manage flows across different environments. This feature allows you to prefix flow names with a namespace, helping to organize and separate flows between environments like staging and production.
You can set the namespace using the COCOINDEX_APP_NAMESPACE environment variable.
For example, if you set COCOINDEX_APP_NAMESPACE=Staging and define a flow with @cocoindex.flow_def(name="TextEmbedding"), the final flow name will be Staging.TextEmbedding.
This is particularly useful when:
- Managing flows across different environments
- Sharing flows within a team
- Organizing flows by project or application
You can also programmatically access the current namespace using cocoindex.get_app_namespace() to use it in your own code.
Learn more about this feature in the documentation.
Pretty print flow spec / schema
CocoIndex now supports showing the flow spec and schema in a more readable format with cocoindex show.
For example, to print out the flow spec in this document to knowledge graph project, you can run:
cocoindex show main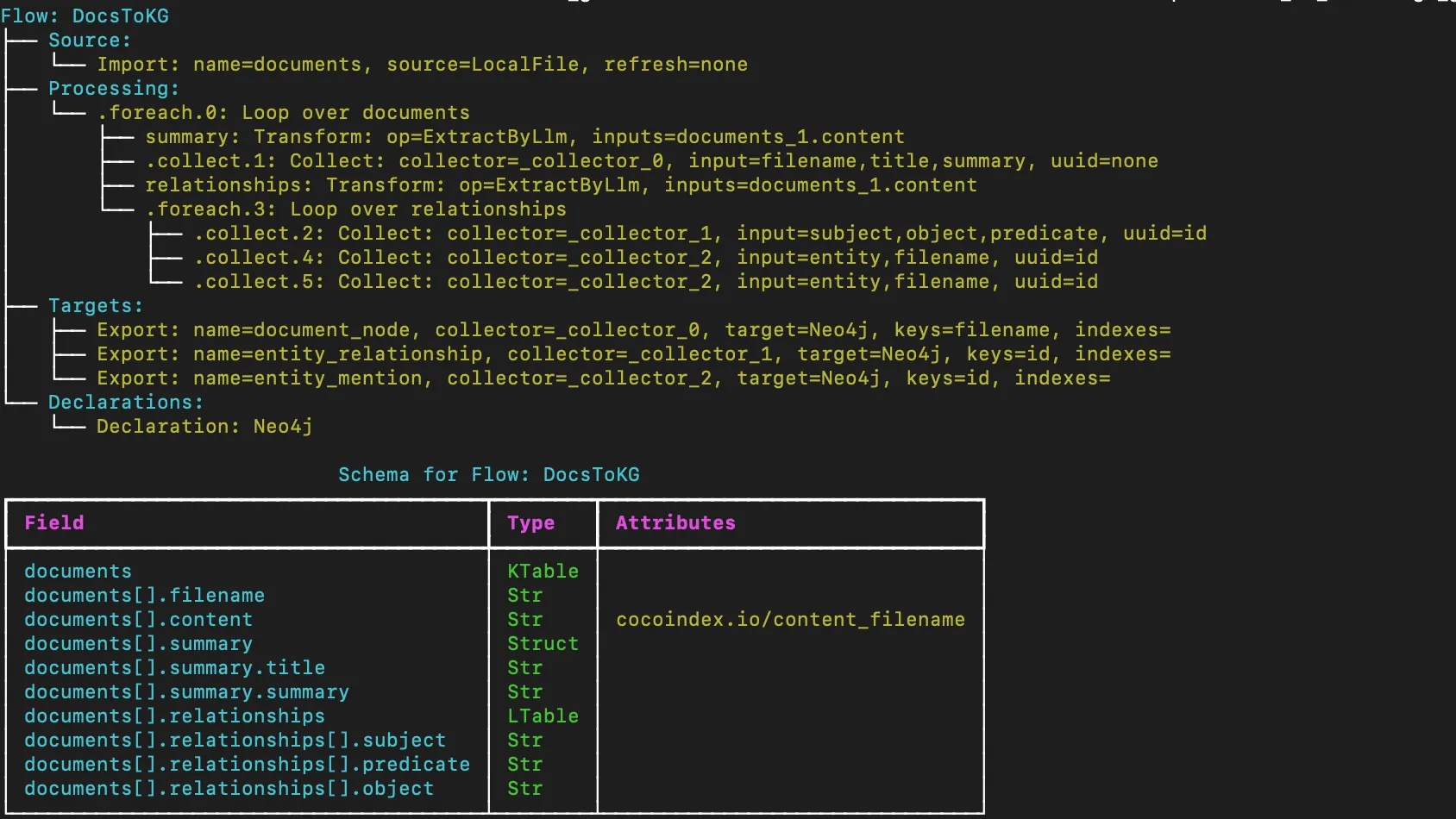
It prints out
- the lineage of the flow from data source to the final output.
- the global data schema of the flow
Type system updates
TimeDelta type
CocoIndex now supports the TimeDelta type, which is a duration of time.
Learn more about the type system in the documentation.
Examples and tutorials
Real-time semantic search from files in S3
- Tutorial: Real-time semantic search from files in S3
- Code example: Amazon S3 Embedding
Image search with vision model
- Tutorial: Image search with Vision model
- Code example: Image Search
Text search with FastAPI server on Docker Compose
- Code example: Docker Compose for fast api server
Thanks to the community!
Welcome new contributors to the CocoIndex community! We are so excited to have you!
@lemorage

Thanks to @lemorage for the contributions! CocoIndex has received a list of high quality PR from him, and we really appreciate his work.
CLI:
- feat: create standalone CLI for CocoIndex #485
- feat(pyo3): implement flow spec pretty print and add verbose mode #442
- feat(cli): enhance flow display with schema rendering support#427
- feat(cli): make flow name retrieval efficient #414
DataTypes
- feat: add support for TimeDelta type in Python and Rust #497
- feat: support namedtuple for struct types #462
- feat(yaml): store variant name in tuple and struct variants#444
@AbdelRahmanYaghi

Created an example of docker compose which runs pg17 along with a simple fastapi endpoint for querying text embeddings. 432
@par4m

Created an example of image search with Vision model 447
Full changelog
Review the detailed changelog here.
We are constantly improving CocoIndex, more features are coming soon! Stay tuned and follow us by starring our GitHub repo.
About the author.

Posts from the CocoIndex team — product launches, release notes, and announcements.