How to build index with text embeddings

In this blog, we will build index with text embeddings and query it with natural language. We try to keep it minimalistic and focus on the gist of the indexing flow.
🚀 You can find the full code of this project here or play it on Colab.
It'd mean a lot to us if you could drop a star at CocoIndex on Github, if this tutorial is helpful.

Prerequisites
- Install Postgres. CocoIndex uses Postgres to keep track of data lineage for incremental processing.
Define indexing flow
Flow design
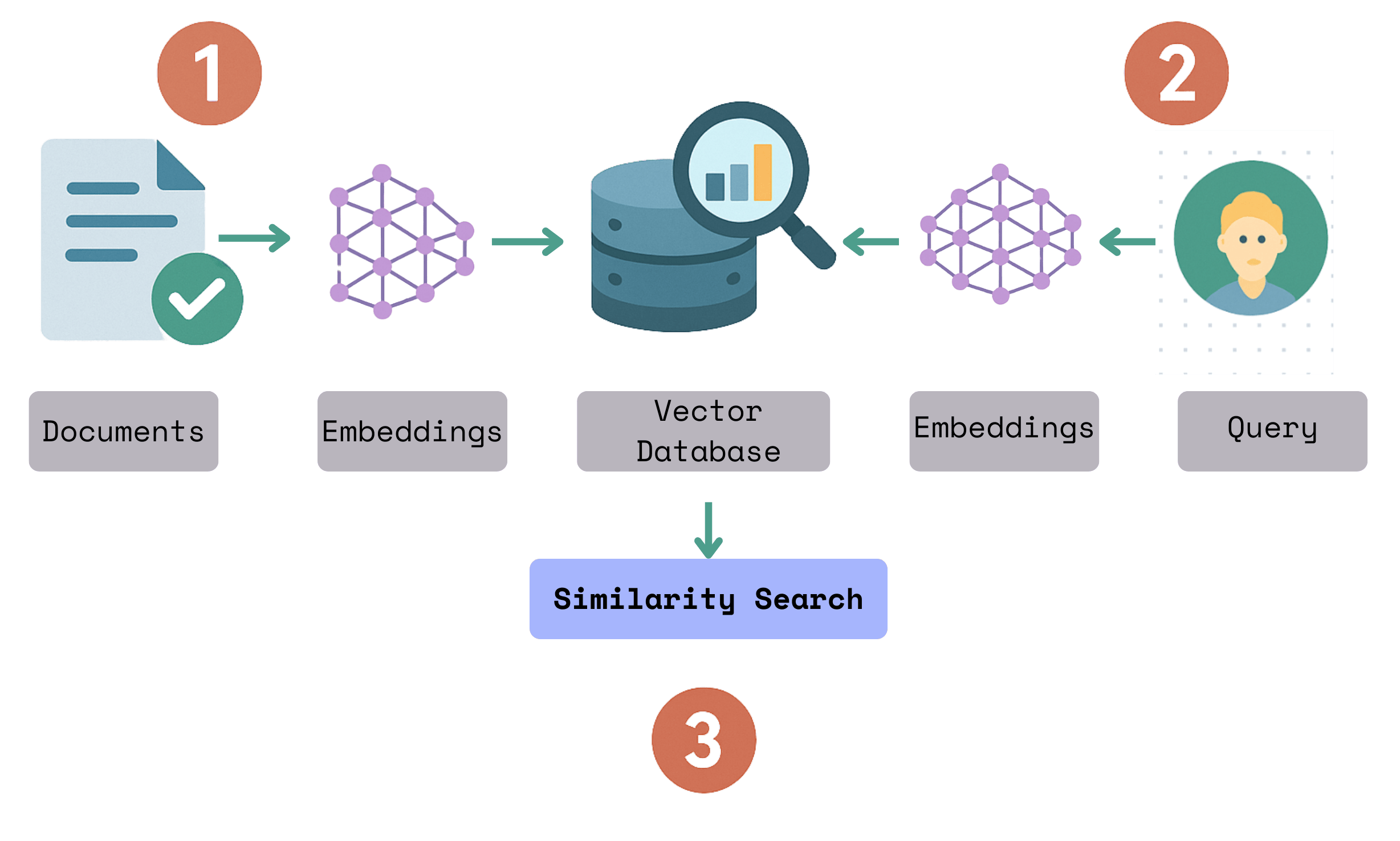
The flow diagram illustrates how we'll process our codebase:
- Read text files from the local filesystem
- Chunk each document
- For each chunk, embed it with a text embedding model
- Store the embeddings in a vector database for retrieval
1. Ingest the files
@cocoindex.flow_def(name="TextEmbedding")
def text_embedding_flow(flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope):
"""
Define an example flow that embeds text into a vector database.
"""
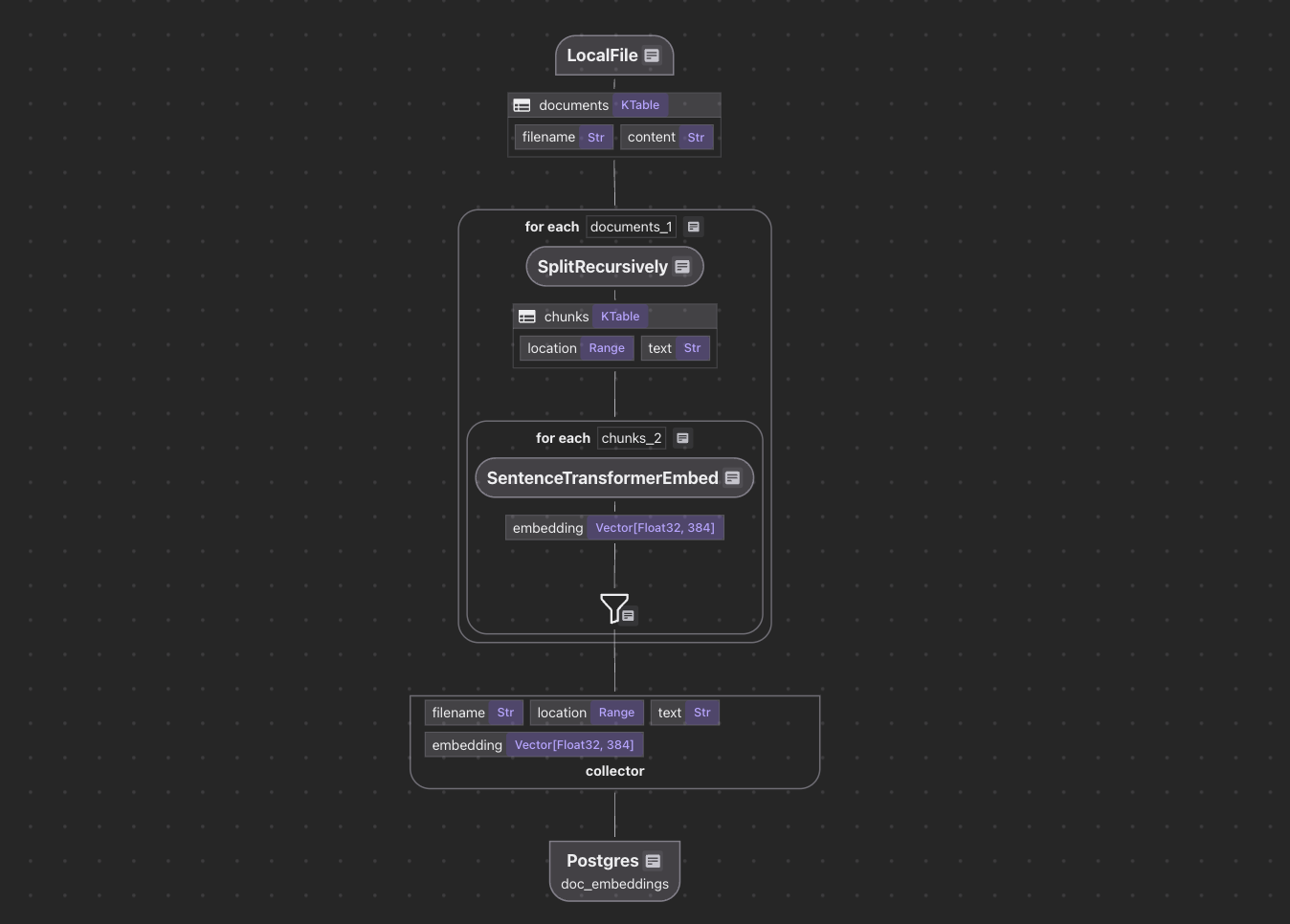
data_scope["documents"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="markdown_files"))
doc_embeddings = data_scope.add_collector()
flow_builder.add_source will create a table with sub fields (filename, content), we can refer to the documentation for more details.
2. Process each file and collect the embeddings
2.1 Chunk the file
with data_scope["documents"].row() as doc:
doc["chunks"] = doc["content"].transform(
cocoindex.functions.SplitRecursively(),
language="markdown", chunk_size=2000, chunk_overlap=500)
2.2 Embed each chunk
@cocoindex.transform_flow()
def text_to_embedding(text: cocoindex.DataSlice[str]) -> cocoindex.DataSlice[list[float]]:
"""
Embed the text using a SentenceTransformer model.
This is a shared logic between indexing and querying, so extract it as a function.
"""
return text.transform(
cocoindex.functions.SentenceTransformerEmbed(
model="sentence-transformers/all-MiniLM-L6-v2"))
This code defines a transformation function that converts text into vector embeddings using the SentenceTransformer model.
@cocoindex.transform_flow() is needed to share the transformation across indexing and query.
This decorator marks this as a reusable transformation flow that can be called on specific input data from user code using eval(), as shown in the search function below.
The function uses CocoIndex's built-in SentenceTransformerEmbed function to convert the input text into 384-dimensional embeddings
The MiniLM-L6-v2 model is a good balance of speed and quality for text embeddings, though you can swap in other SentenceTransformer models as needed.
with doc["chunks"].row() as chunk:
chunk["embedding"] = text_to_embedding(chunk["text"])
doc_embeddings.collect(filename=doc["filename"], location=chunk["location"],
text=chunk["text"], embedding=chunk["embedding"])
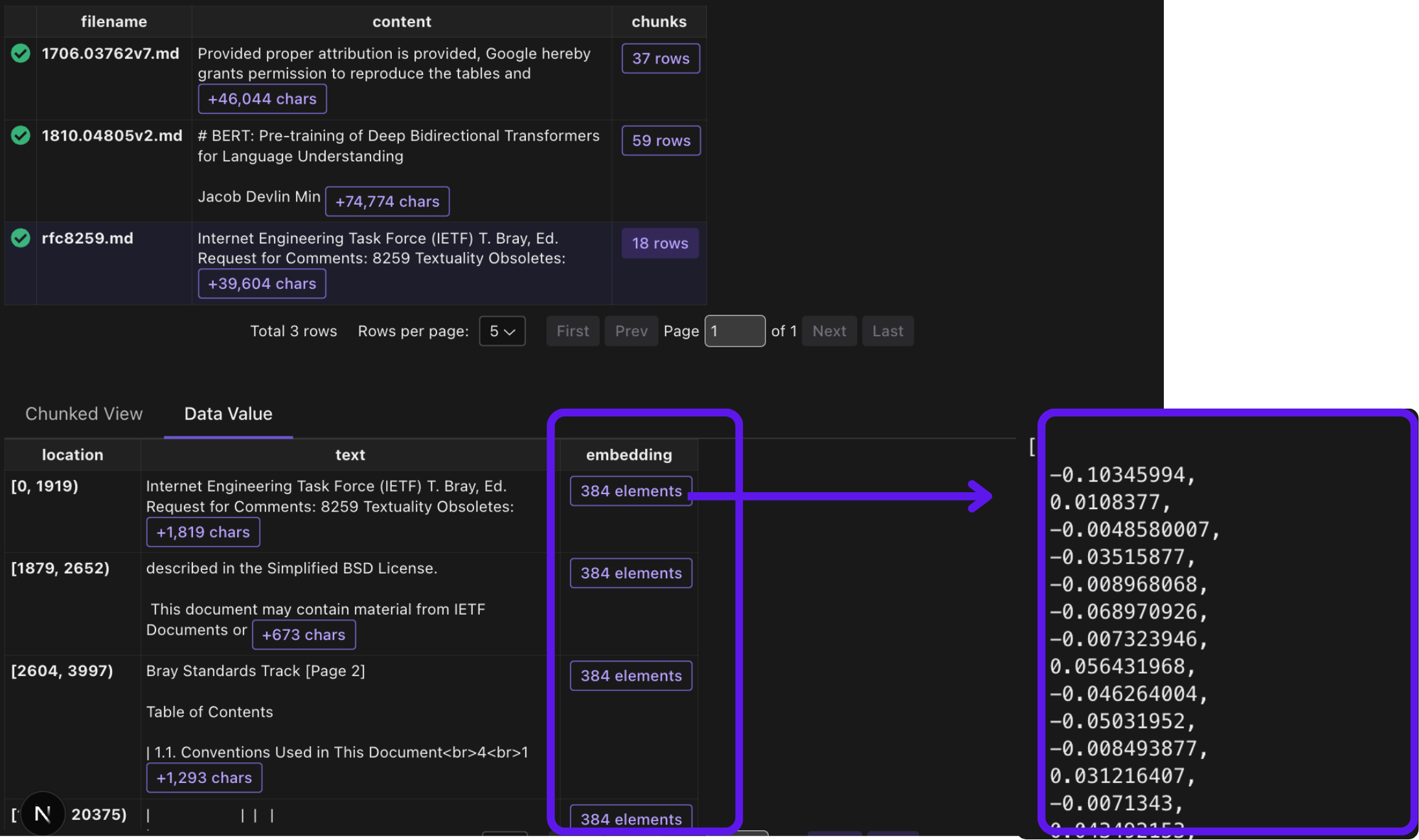
2.3 Export the embeddings
Export the embeddings to a table in Postgres.
doc_embeddings.export(
"doc_embeddings",
cocoindex.storages.Postgres(),
primary_key_fields=["filename", "location"],
vector_indexes=[
cocoindex.VectorIndexDef(
field_name="embedding",
metric=cocoindex.VectorSimilarityMetric.COSINE_SIMILARITY)])
3. Query the index
CocoIndex doesn't provide additional query interface. We can write SQL or rely on the query engine by the target storage, if any.
def search(pool: ConnectionPool, query: str, top_k: int = 5):
table_name = cocoindex.utils.get_target_storage_default_name(text_embedding_flow, "doc_embeddings")
query_vector = text_to_embedding.eval(query)
with pool.connection() as conn:
with conn.cursor() as cur:
cur.execute(f"""
SELECT filename, text, embedding <=> %s::vector AS distance
FROM {table_name} ORDER BY distance LIMIT %s
""", (query_vector, top_k))
return [
{"filename": row[0], "text": row[1], "score": 1.0 - row[2]}
for row in cur.fetchall()
]
Setup main() for interactive query in terminal.
def _main():
# Initialize the database connection pool.
pool = ConnectionPool(os.getenv("COCOINDEX_DATABASE_URL"))
# Run queries in a loop to demonstrate the query capabilities.
while True:
query = input("Enter search query (or Enter to quit): ")
if query == '':
break
# Run the query function with the database connection pool and the query.
results = search(pool, query)
print("\nSearch results:")
for result in results:
print(f"[{result['score']:.3f}] {result['filename']}")
print(f" {result['text']}")
print("---")
print()
if __name__ == "__main__":
load_dotenv()
cocoindex.init()
_main()
Time to have fun!
-
Run the following command to setup and update the index.
cocoindex update --setup main -
Start the interactive query in terminal.
python main.py
Support us
We are constantly improving, and more features and examples are coming soon. If you love this article, please give us a star ⭐ at GitHub to help us grow.
Thanks for reading!