Automated invoice processing with AI, Snowflake and CocoIndex - with incremental processing


I recently worked with a clothing manufacturer who wanted to simplify their invoice process. Every day, they receive around 20–22 supplier invoices in PDF format. All these invoices are stored in Azure Blob Storage. The finance team used to open each PDF manually and copy the details into their system. This took a lot of time and effort. On top of that, they already had a backlog of 8,000 old invoices waiting to be processed.
At first, I built a flow using n8n. This solution read the invoices from Azure Blob Storage, used Mistral AI to pull out the fields from each PDF, and then loaded the results into Snowflake. The setup worked fine for a while. But as the number of invoices grew, the workflow started to break. Debugging errors inside a no-code tool like n8n became harder and harder. That’s when I decided to switch to a coding solution.
I came across CocoIndex, an open-source ETL framework designed to transform data for AI, with support for real-time incremental processing. It allowed me to build a pipeline that was both reliable and scalable for this use case.
In this blog, I will walk you through how I built the pipeline using the CocoIndex framework.
What is CocoIndex?
CocoIndex is an open-source tool that helps move data from one place to another in a smart and structured way. In technical terms, this is called ETL (Extract, Transform, Load). But in simple words, you can think of it as a smart conveyor belt in a factory.
- On one end of the belt, you place the raw material (PDF invoices).
- As the belt moves, the items pass through different stations (transformations). Some stations clean the data, others format it, and some even use AI as inspectors to read and label information.
- At the end of the belt, the finished product is neatly packed into boxes (your Snowflake database).
And here’s the best part: CocoIndex is smart. It remembers what it has already processed. That means if you add a new invoice tomorrow, it won’t redo all the old ones. It will just pick up the new files and process only those. This is called incremental processing, and it saves a huge amount of time and cost.
How CocoIndex works with AI
CocoIndex isn’t just about moving data, it works with AI models during the transformation step.
Here’s how:
- It reads the text from your PDF or file.
- It sends the text to an AI model with clear instructions: “Pull out the invoice number, date, totals, customer name, and items.”
- The AI acts like a smart inspector, turning unstructured text into neat rows and columns.
- CocoIndex then loads that structured output into Snowflake.
- Thanks to incremental updates, only new files trigger AI calls, saving cost and avoiding duplicate work.
Why choose CocoIndex?
- Open-source: Free to use and supported by a growing community.
- AI-friendly: Works smoothly with large language models (LLMs).
- Incremental: Only processes new or changed data, not everything every time.
- Transparent: Lets you trace how each piece of data was transformed.
- Fast & Reliable: Built with Rust under the hood for high performance.
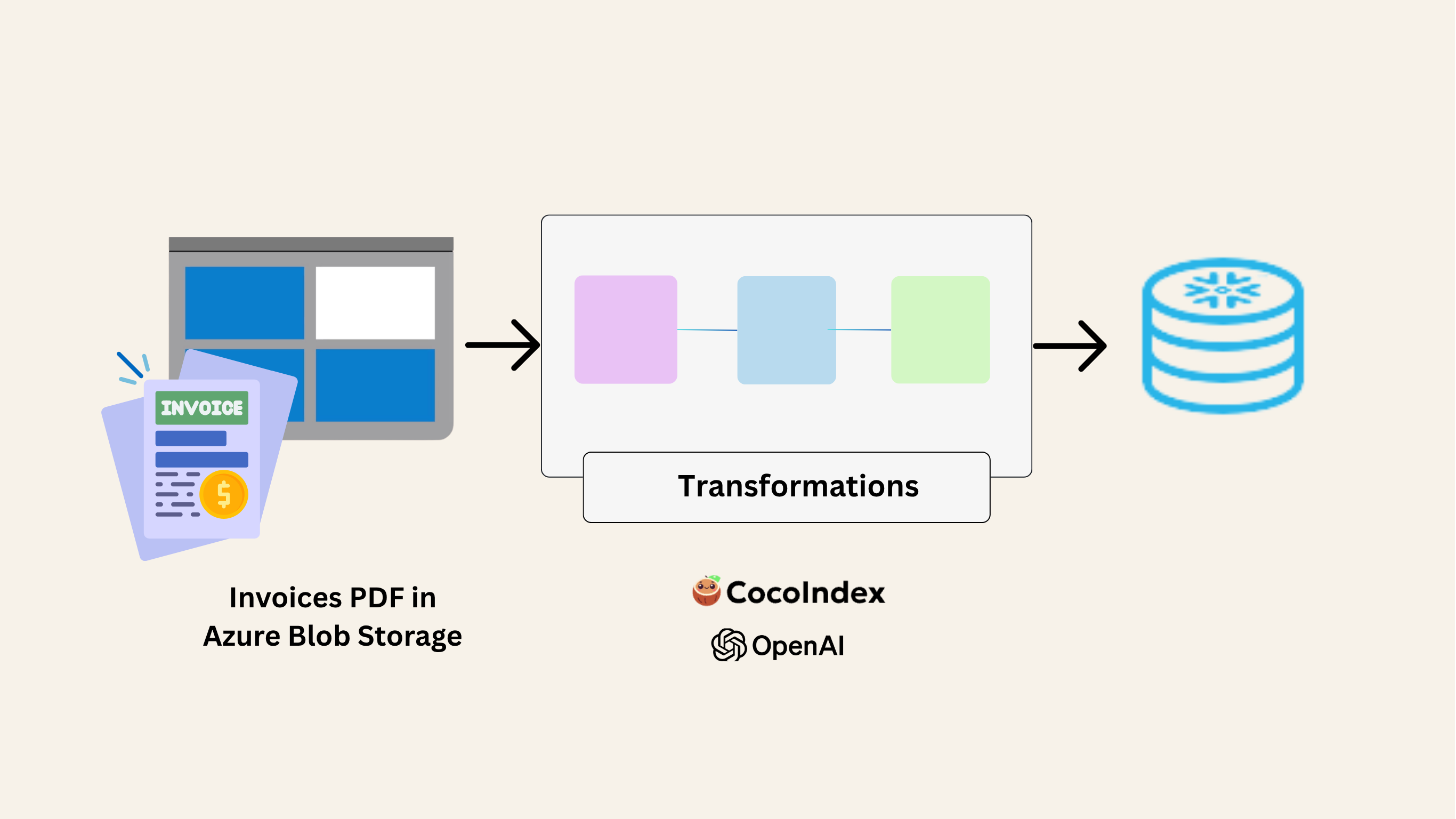
In my client project, suppliers uploaded about 20 to 22 invoices every day into Azure Blob Storage. We first did a full load of around 8,000 old invoices, and after that, the pipeline ran in incremental mode, only picking up the new daily invoices. The setup worked efficiently, and since CocoIndex is open source, we deployed the pipeline with Azure Functions to automate the process.
For this blog, I found a GitHub repository that contains sample invoice PDFs, and I used those files to build and test this use case. Used local machine to run this use case.
Building the pipeline
For this use case, I followed the ELT approach (Extract, Load, Transform). This means:
- Extract invoices from Azure Blob Storage,
- Load them into Snowflake, and
- Later perform the Transformations inside Snowflake.
In this blog, focussed only on the Extract and Load steps, getting the invoice data out of Blob Storage and into Snowflake.
All the PDF invoices are loaded into Azure Blob Storage, then CocoIndex uses an LLM to extract the data from the PDFs and load it into Snowflake.
Before writing a code, we need to setup a Postgres database, CocoIndex needs a small database in the background to keep track of what has already been processed (Incremental processing). This database acts like a logbook, it remembers which invoices were read, what data was extracted, and whether something has changed. Basically it keeps saving the metadata.
You can install Postgres in different ways: directly on your computer, with Docker, or through VS Code extensions. For this use case, I set it up directly inside VS Code.
- Open VS Code.
- Install the PostgreSQL extension from the marketplace.
- Add a new connection with these details:
Host: localhost
Port: 5432
Database: cocoindex
User: cocoindex
Password: cocoindex
This lets you browse and query the database inside VS Code.
Connecting to Azure Blob storage
The next step is to integrate Azure Blob Storage, since our invoices are uploaded there by suppliers. To connect, we use the Azure CLI (Command Line Interface).
First, check if Azure CLI is installed:
az --version
If not installed, install it:
az login
Now you can list all the invoices in your container by providing the account name and container name:
az storage blob list \
--account-name your_account_name \
--container-name invoice \
--auth-mode login
This will prompt you to log in and then show all the blobs (files) inside the invoice container.
Setting up the .env File
We first create a .env file to store the credentials for OpenAI, Postgres, Snowflake, and Azure Blob Storage. This keeps all secrets in one place and out of the main code.
# OpenAI
OPENAI_API_KEY=sk-*********************
# CocoIndex engine (Postgres)
COCOINDEX_DATABASE_URL=postgresql://user:password@localhost:5432/cocoindex
# Azure Blob
AZURE_ACCOUNT_NAME=your_account_name
AZURE_CONTAINER=invoice
AZURE_SAS_TOKEN=sv=**************************
AZURE_PREFIX=
# Snowflake
SNOWFLAKE_USER=your_username
SNOWFLAKE_PASSWORD=***************
SNOWFLAKE_ACCOUNT=your_account_id
SNOWFLAKE_WAREHOUSE=COMPUTE_WH
SNOWFLAKE_DATABASE=INVOICE
SNOWFLAKE_SCHEMA=DBO
SNOWFLAKE_TABLE=INVOICES
Creating main.py
We start by importing the necessary libraries.
import os
import dataclasses
import tempfile
import warnings
import json
from typing import Optional, List
from dotenv import load_dotenv
import cocoindex
from markitdown import MarkItDown
import snowflake.connector
dataclasses is used to create structured “blueprints” for invoices and their line items, so all data follows the same format. MarkItDown converts PDF files into Markdown (plain text with structure). This makes it easier for AI to read invoices, since tables and headings are kept in order.
We now load all the secrets (API keys, database credentials, etc.) from the .env file.
# Load environment variables
load_dotenv()
print(”DEBUG: .env loaded”)
# Azure
AZURE_ACCOUNT_NAME = os.getenv(”AZURE_ACCOUNT_NAME”) # e.g. trucktechbi
AZURE_CONTAINER = os.getenv(”AZURE_CONTAINER”) # e.g. invoice
# OpenAI
os.environ[”OPENAI_API_KEY”] = os.getenv(”OPENAI_API_KEY”)
# CocoIndex internal DB (Postgres)
os.environ[”COCOINDEX_DATABASE_URL”] = os.getenv(”COCOINDEX_DATABASE_URL”)
# Snowflake
SF_USER = os.getenv(”SNOWFLAKE_USER”)
SF_PASSWORD = os.getenv(”SNOWFLAKE_PASSWORD”)
SF_ACCOUNT = os.getenv(”SNOWFLAKE_ACCOUNT”)
SF_WAREHOUSE = os.getenv(”SNOWFLAKE_WAREHOUSE”)
SF_DATABASE = os.getenv(”SNOWFLAKE_DATABASE”)
SF_SCHEMA = os.getenv(”SNOWFLAKE_SCHEMA”)
SF_TABLE = os.getenv(”SNOWFLAKE_TABLE”)
The line load_dotenv() reads all values from the .env file. os.getenv(”...”) fetches each secret (like account names, passwords, API keys).
We are extracting the following fields from each invoice. Below is a sample invoice (from the GitHub repo) showing the data mapping. Each highlighted area represents a field we want to capture and store in Snowflake: Invoice Number, Date, Customer Name, Bill To, Ship To, Subtotal, Discount, Shipping, Total, Balance Due, Order ID, Ship Mode, Notes, Terms, Line Items (Product Name, Quantity, Rate, Amount, SKU, Category)
This mapping ensures that every important piece of information from the invoice PDF is extracted in a structured format.
Next, we create two dataclasses (simple templates for storing information in a structured way).
LineItemholds product details such as description, quantity, rate, amount, SKU, and category.Invoiceholds the overall invoice details (number, date, customer, totals, etc.) and also includes a list of line items.
Inside the Invoice dataclass, we also include clear instructions (a “prompt”) that guide the AI on how to extract data consistently. For example:
- Always return numbers without currency symbols (e.g., 58.11, not $58.11).
- If a field is missing, return an empty string (”“).
- Never swap values between fields.
Keep line_items as a structured list of objects.
This built-in prompt acts like documentation for the schema. When the AI processes each invoice, it uses these rules to reliably map the PDF data into the right fields for Snowflake.
# Dataclasses
@dataclasses.dataclass
class LineItem:
description: Optional[str] = None
quantity: Optional[str] = None
rate: Optional[str] = None
amount: Optional[str] = None
sku: Optional[str] = None
category: Optional[str] = None
@dataclasses.dataclass
class Invoice:
“”“
Represents a supplier invoice with extracted fields.
- invoice_number → The invoice number (e.g. “36259”). If not found,
return “”.
- date → Invoice date (e.g. “Mar 06 2012”).
- customer_name → Person or company name under “Bill To”. Do not
include address.
- bill_to → Full “Bill To” block including address if present.
- ship_to → Full “Ship To” block including address if present.
- subtotal → Subtotal amount (numeric, no currency symbols).
- discount → Any discount listed (numeric, no % sign).
- shipping → Shipping/handling amount (numeric).
- total → Total amount (numeric).
- balance_due → Balance Due amount (numeric).
- order_id → Purchase order or Order ID (e.g. “CA-2012-AB10015140-
40974”).
- ship_mode → The shipping method (e.g. “First Class”).
- notes → Free-text notes (e.g. “Thanks for your business!”).
- terms → Payment terms (if present).
- line_items → Extract each invoice table row:
- description → Item/Product name (e.g. “Newell 330”).
- quantity → Numeric quantity.
- rate → Unit price (numeric).
- amount → Line total (numeric).
- sku → Product ID if listed (e.g. “OFF-AR-5309”).
- category → Category/sub-category (e.g. “Art, Office
Supplies”).
Rules:
- Always return numbers as plain numeric text (e.g. “58.11”, not
“$58.11”).
- If a field is missing in the PDF, return “” (empty string).
- Never swap fields between columns.
- Keep line_items as an array of structured objects.
“”“
invoice_number: Optional[str] = None
date: Optional[str] = None
customer_name: Optional[str] = None
bill_to: Optional[str] = None
ship_to: Optional[str] = None
subtotal: Optional[str] = None
discount: Optional[str] = None
shipping: Optional[str] = None
total: Optional[str] = None
balance_due: Optional[str] = None
order_id: Optional[str] = None
ship_mode: Optional[str] = None
notes: Optional[str] = None
terms: Optional[str] = None
line_items: Optional[List[LineItem]] = None
Next is PDF Markdown. This part of the code converts invoice PDFs into plain text using the MarkItDown library. Since AI models can’t easily read raw PDFs, we first turn them into Markdown, a lightweight text format that keeps structure like headings and tables. The code briefly saves the PDF content into a temporary file, passes it to MarkItDown for conversion, and then deletes the file. The result is clean, structured text that’s ready for AI to extract the invoice fields.
# PDF → Markdown
class ToMarkdown(cocoindex.op.FunctionSpec):
“”“Convert PDF bytes to markdown/text using MarkItDown.”“”
@cocoindex.op.executor_class(gpu=False, cache=True, behavior_version=1)
class ToMarkdownExecutor:
spec: ToMarkdown
_converter: MarkItDown
def prepare(self) -> None:
self._converter = MarkItDown()
def __call__(self, content: bytes, filename: str) -> str:
suffix = os.path.splitext(filename)[1]
with tempfile.NamedTemporaryFile(delete=True, suffix=suffix) as tmp:
tmp.write(content)
tmp.flush()
result = self._converter.convert(tmp.name)
return result.text_content or “”
After converting the invoice into structured data, now needs to get the invoice number. This small function does exactly that:
- It looks inside the
Invoiceobject. - If an invoice_number exists, it returns it.
- If it’s missing or something goes wrong, it safely returns an empty string instead of breaking the pipeline.
This code block is important because the invoice number acts like a unique ID, so we later use it as the primary key in Snowflake to avoid duplicates.
#Extract invoice_number from Invoice object
class GetInvoiceNumber(cocoindex.op.FunctionSpec):
@cocoindex.op.executor_class(gpu=False, cache=True, behavior_version=1)
class GetInvoiceNumberExecutor:
spec: GetInvoiceNumber
def __call__(self, inv: Invoice) -> str:
try:
return inv.invoice_number or “”
except Exception:
return “”
The next step is to load the extracted invoice data into Snowflake. For this, I created a target table called INVOICES in Snowflake.
Since this is just the raw load step (no transformations yet), all columns are stored as VARCHAR. This way, the data goes in exactly as it is extracted, and we can do the transformation inside the Snowflake.
CREATE OR REPLACE TABLE INVOICES (
INVOICE_NUMBER VARCHAR(50),
CUSTOMER_NAME VARCHAR(255),
BILL_TO VARCHAR(500),
SHIP_TO VARCHAR(500),
SUBTOTAL VARCHAR(50),
DISCOUNT VARCHAR(50),
SHIPPING VARCHAR(50),
TOTAL VARCHAR(50),
BALANCE_DUE VARCHAR(50),
ORDER_ID VARCHAR(50),
SHIP_MODE VARCHAR(100),
NOTES VARCHAR(1000),
TERMS VARCHAR(500),
LINE_ITEMS VARCHAR(2000),
CREATED_AT VARCHAR(50),
FILENAME VARCHAR(255),
DATE VARCHAR(50)
);
the below code blocks uses the credentials (user, password, account, warehouse, database, schema, table) from the .env file.
It then uses a MERGE command. This is important because:
- If an invoice already exists (with the same invoice number), the row is updated with the latest data.
- If it’s a new invoice, the row is inserted as a new record.
- Line items are stored as a JSON array, so each invoice can contain multiple products.
CREATED_ATtimestamp is also added, so we know when the data was last loaded.
This ensures the Snowflake table is always clean, no duplicates, and always up to date with the latest invoices.
# Snowflake Target
class SnowflakeTarget(cocoindex.op.TargetSpec):
user: str
password: str
account: str
warehouse: str
database: str
schema: str
table: str
@cocoindex.op.target_connector(spec_cls=SnowflakeTarget)
class SnowflakeTargetConnector:
@staticmethod
def get_persistent_key(spec: SnowflakeTarget, target_name: str) -> str:
return f”{spec.account}/{spec.database}/{spec.schema}/{spec.table}”
@staticmethod
def describe(key: str) -> str:
return f”Snowflake table {key}”
@staticmethod
def apply_setup_change(key, previous, current) -> None:
return
@staticmethod
def mutate(*all_mutations: tuple[SnowflakeTarget, dict[str, dict | None]]) -> None:
for spec, mutations in all_mutations:
if not mutations:
continue
fqn = f’{spec.database}.{spec.schema}.{spec.table}’
conn = snowflake.connector.connect(
user=spec.user,
password=spec.password,
account=spec.account,
warehouse=spec.warehouse,
database=spec.database,
schema=spec.schema,
)
try:
cur = conn.cursor()
cur.execute(f’USE WAREHOUSE “{spec.warehouse}”’)
for filename_key, value in mutations.items():
if value is None:
continue
filename = value.get(”filename”, filename_key)
inv_data = value[”invoice”]
if isinstance(inv_data, dict):
inv_dict = inv_data
line_items = inv_dict.get(”line_items”, []) or []
else:
inv_dict = dataclasses.asdict(inv_data)
line_items = inv_data.line_items or []
inv_num = value.get(”invoice_number”) or inv_dict.get(”invoice_number”) or filename
line_items_json = json.dumps(
[dataclasses.asdict(li) if not isinstance(li, dict) else li for li in line_items],
ensure_ascii=False
)
cur.execute(f”“”
MERGE INTO {fqn} t
USING (
SELECT
%s AS INVOICE_NUMBER, %s AS DATE, %s AS
CUSTOMER_NAME, %s AS BILL_TO, %s AS
SHIP_TO, %s AS SUBTOTAL, %s AS DISCOUNT,
%s AS SHIPPING, %s AS TOTAL, %s AS
BALANCE_DUE, %s AS ORDER_ID, %s AS
SHIP_MODE, %s AS NOTES, %s AS TERMS,
PARSE_JSON(%s) AS LINE_ITEMS, %s AS
FILENAME, CURRENT_TIMESTAMP AS
CREATED_AT ) s
ON t.INVOICE_NUMBER = s.INVOICE_NUMBER
WHEN MATCHED THEN UPDATE SET
DATE=s.DATE, CUSTOMER_NAME=s.CUSTOMER_NAME,
BILL_TO=s.BILL_TO, SHIP_TO=s.SHIP_TO,
SUBTOTAL=s.SUBTOTAL, DISCOUNT=s.DISCOUNT,
SHIPPING=s.SHIPPING, TOTAL=s.TOTAL,
BALANCE_DUE=s.BALANCE_DUE, ORDER_ID=s.ORDER_ID,
SHIP_MODE=s.SHIP_MODE, NOTES=s.NOTES,
TERMS=s.TERMS, LINE_ITEMS=s.LINE_ITEMS,
FILENAME=s.FILENAME,CREATED_AT=CURRENT_TIMESTAMP
WHEN NOT MATCHED THEN INSERT (
INVOICE_NUMBER, DATE, CUSTOMER_NAME, BILL_TO,
SHIP_TO,SUBTOTAL, DISCOUNT, SHIPPING, TOTAL,
BALANCE_DUE,ORDER_ID, SHIP_MODE, NOTES, TERMS,
LINE_ITEMS, FILENAME
) VALUES (
s.INVOICE_NUMBER, s.DATE, s.CUSTOMER_NAME,
s.BILL_TO, s.SHIP_TO, s.SUBTOTAL,
s.DISCOUNT, s.SHIPPING, s.TOTAL,
s.BALANCE_DUE, s.ORDER_ID, s.SHIP_MODE,
s.NOTES, s.TERMS, s.LINE_ITEMS, s.FILENAME
)
“”“, (
inv_num,
inv_dict.get(”date”),
inv_dict.get(”customer_name”),
inv_dict.get(”bill_to”),
inv_dict.get(”ship_to”),
inv_dict.get(”subtotal”),
inv_dict.get(”discount”),
inv_dict.get(”shipping”),
inv_dict.get(”total”),
inv_dict.get(”balance_due”),
inv_dict.get(”order_id”),
inv_dict.get(”ship_mode”),
inv_dict.get(”notes”),
inv_dict.get(”terms”),
line_items_json,
filename,
))
finally:
try: cur.close()
except: pass
conn.close()
Building the flow
Now we build the flow, this defines how invoices move from Azure Blob Storage all the way into Snowflake.
1. Source (Input)
The flow starts by connecting to Azure Blob Storage and reading all the invoice PDFs from the container.
2. Convert PDFs to Text
Each PDF is run through the ToMarkdown step, which converts it into structured text that the AI can understand.
3. AI Extraction (with schema prompt)
The extracted text is then processed by OpenAI through CocoIndex. Instead of hardcoding all the rules here, the AI now follows the Invoice dataclass docstring, which contains clear instructions for how to map fields (like invoice number, date, totals, and line items). This built-in schema acts like a guide, ensuring the AI always:
- Extracts fields in the correct format.
- Returns numbers without symbols.
- Leaves fields empty (”“) if data is missing.
- Keeps line items structured.
This way, the AI outputs consistent, clean data that fits directly into Snowflake.
4. Invoice Number Check
A helper function (GetInvoiceNumber) ensures each invoice has a proper ID. This ID is used as the primary key to keep data unique.
5. Collector
All invoices are grouped together and prepared for export.
6. Export to Snowflake
Finally, the invoices are loaded into the Snowflake table (INVOICES). If an invoice already exists, it’s updated; if it’s new, it’s inserted.
@cocoindex.flow_def(name=”InvoiceExtraction”)
def invoice_flow(flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope) -> None:
azure_source_params = {
“account_name”: AZURE_ACCOUNT_NAME,
“container_name”: AZURE_CONTAINER,
“binary”: True,
“included_patterns”: [”*.pdf”],
}
data_scope[”documents”] = flow_builder.add_source(
cocoindex.sources.AzureBlob(**azure_source_params)
)
invoices = data_scope.add_collector()
with data_scope[”documents”].row() as doc:
doc[”markdown”] = doc[”content”].transform(ToMarkdown(), filename=doc[”filename”])
doc[”invoice”] = doc[”markdown”].transform(
cocoindex.functions.ExtractByLlm(
llm_spec=cocoindex.LlmSpec(api_type=cocoindex.LlmApiType.OPENAI, model=”gpt-4o”),
output_type=Invoice,
instruction=”Extract the invoice into the Invoice schema as documented.”
)
)
doc[”invoice_number”] = doc[”invoice”].transform(GetInvoiceNumber())
invoices.collect(filename=doc[”filename”], invoice=doc[”invoice”], invoice_number=doc[”invoice_number”])
invoices.export(
“SnowflakeInvoices”,
SnowflakeTarget(
user=SF_USER,
password=SF_PASSWORD,
account=SF_ACCOUNT,
warehouse=SF_WAREHOUSE,
database=SF_DATABASE,
schema=SF_SCHEMA,
table=SF_TABLE,
),
primary_key_fields=[”invoice_number”],
)
Running the pipeline
The last code block to run the flow
- It prints which Azure Blob container is being used.
invoice_flow.setup()prepares the pipeline — checking sources (Azure), the target (Snowflake), and making sure everything is ready.invoice_flow.update()runs the flow. It reads new invoices from Azure, extracts the fields with AI, and loads them into Snowflake.- Finally, it prints a summary (
Update stats) showing how many records were inserted or updated.
if __name__ == “__main__”:
print(f”Reading directly from Azure Blob container:
{AZURE_CONTAINER}”)
invoice_flow.setup(report_to_stdout=True)
stats = invoice_flow.update(reexport_targets=False)
print(”Update stats:”, stats)
Best thing about CocoIndex is it supports real-time incremental processing, it only processes and exports new or changed files since the last run.
if reexport_targets = False (the default)
- Only new or updated invoices are exported to Snowflake. Old ones are skipped.
if reexport_targets = True
- It forces all invoices (new + old) to be re-exported into Snowflake, even if they haven’t changed.
So you use True if you want a full refresh, and False if you just want the incremental updates.
Now the pipeline loads all invoices from Azure Blob Storage into the INVOICES table in Snowflake without doing any transformations. This blog focuses only on the Extract and Load steps. Transformations can be done inside the Snowflake.
Challenges
Since this pipeline uses AI to extract data from invoices, it’s not always perfect. Evaluation is a real challenge. When I tested with original client data, many fields were mismatched at first. By refining the prompt, I was able to improve accuracy. For this blog’s demo data the results were more reliable, but with messy or inconsistent invoices, AI can still make mistakes or “hallucinate.” Structured PDFs are usually easier to handle.
It’s important to note that CocoIndex itself is not a parser. It’s a framework and incremental engine that allows you to plug in any AI model or custom logic. For parsing invoices, you can choose the tool that works best for your use case. For example, I used OpenAI here, but tools like Google Document AI or other specialized invoice parsers could also be a good fit. In some cases, fine-tuning a model for your own domain may give the best results.
For more information on CocoIndex, please check the documentation.
Thanks for reading