

:rocket: Over the 20+ releases, CocoIndex continued to advance its ultra-performant AI-native ETL infrastructure with a series of targeted features and enhancements focused on reliable incremental processing, error resilience, and extensibility.
We are constantly improving CocoIndex to make it easier to use, more powerful, and more reliable. :star: Star us on GitHub to stay updated!
Core capability
Durable execution
CocoIndex is designed for massive, ever-changing datasets. Reliability and efficiency are critical. With durable execution, CocoIndex now automatically captures failures and retries only the affected rows, ensuring progress is never lost and avoiding full reprocessing.
- Automatic recovery on failure: Failed rows are automatically retried in the next update #995, with optional fine-grained control through configurable retry lists #997. CocoIndex also maintains precise processing order tracking to guarantee consistent reprocessing sequences #1001.
- Stable transient authentication: Improved handling of short-lived auth keys ensures reliability and prevents drift across retries #1002.
These enhancements make incremental processing more fault-tolerant, efficient, and self-healing, allowing CocoIndex to continuously move forward - no wasted computation, no data left behind.
Avoid unnecessary reprocessing
In CocoIndex, reprocessing can be triggered by changes in either source data or flow definitions. We improved our flow change detection mechanism, significantly reducing false positives and avoiding unnecessary reprocessing.
- Improved change detection logic: Refined how CocoIndex evaluates flow and dependency changes, cutting down false positives and ensuring reprocessing only happens when it’s truly needed. This leads to faster, more predictable runs and reduced compute costs. #1182
- Stable transient auth keys: Enhanced retry behavior now keeps authentication keys consistent across transient failures, preventing drift and improving reliability for long-running flows. #1002
Together, these updates make CocoIndex’s incremental engine more deterministic, efficient, and resilient. So your flows stay lean even as your data and logic evolve.
Enhanced build & update target data
We’ve expanded how CocoIndex builds and updates target data, giving users more control over replication and recovery workflows.
Supported Modes
- One-time update: Builds or updates target data based on the current state of the source.
- Live update: Starts with a one-time update, then continuously captures source changes to keep targets up to date.
New Option: Reexport Targets with --reexport
We’ve added a new --reexport option that can be applied to both modes. When enabled, CocoIndex ignores the previous state of the target and rebuilds it entirely — even if neither the source data nor the flow definition has changed.
This is especially useful for data recovery, corrections, or full target refreshes after data loss. In live update mode, reexport applies only to the initial build phase.
Example:
cocoindex update --reexport mainThis enhancement broadens pipeline flexibility and improves data reliability in recovery or replay scenarios.
Read more in Build and update data.
New option: --reset for setup, update, and server commands
We’ve added a new --reset flag that makes it easier to start fresh by automatically clearing existing setups before running key commands.
When you use --reset, CocoIndex will drop the existing setup or state before performing the new operation — equivalent to running cocoindex drop first.
Example:
cocoindex setup --reset mainThis ensures a clean environment for rebuilds, testing, or reinitializing workflows — without needing to manually clear prior state.
Incremental engine optimizations with fast fingerprint collapsing
CocoIndex has smart incremental processing out of the box, that only processes what’s changed. In the latest version, we’ve included more engine-level optimizations to improve efficiency for large datasets:
- Source content fingerprinting — the engine tracks a lightweight “fingerprint” of each source row or file, allowing it to detect when content hasn’t changed. #892
- Fast collapse — unchanged data can be skipped without reading the full source, significantly reducing processing time and resource usage. #895
This optimization is particularly useful for sources that provide a content hash, version tag, or fingerprint (e.g., GitHub files, S3 objects, or custom sources). CocoIndex can save a large number of external API calls in addition to compute costs, making workflows faster and more cost-efficient.
While primarily designed for versioned sources like GitHub, this approach can benefit any source that exposes change indicators, improving incremental processing across diverse pipelines.
None handling
CocoIndex supports None values. A None value represents the absence of data or an unknown value, distinct from empty strings, zero numbers, or false boolean values. None input values passed to required arguments of CocoIndex functions will short-circuit the function and result in None output value. See the documentation for more details.
In this release, None value handling in transformations was improved to better manage required and nullable fields, increasing robustness.
Robustness
Isolate GPU workloads in subprocess
Added full subprocess support for GPU workloads, improving stability and isolation while removing the need for global locks. These enhancements mark a strong step forward in robustness and performance for GPU‐driven workloads within CocoIndex. They reduce risk of GPU jobs hanging, and provide better tolerance to GPU failures. For users leveraging GPU processing, the update is highly recommended and should bring a smoother, more resilient operational experience.
What to expect for users / developers
If you’re using CocoIndex’s GPU-capable workloads, you may notice improved stability. Temporary failure caused by GPU will be isolated in the subprocess, which will be restarted gracefully.
Error tolerance improvements
Fixed live-mode behaviour so that source-level errors are now logged instead of aborting the process. Also improved coverage of retrying for several external APIs, e.g. OpenAI and Vertex AI. This reduces failures and improves stability.
Query handler and CocoInsight support
Query handler
Query handlers let you expose a simple function that takes a query string and returns structured results. They are discoverable by tools like CocoInsight so you can query your indexes without writing extra glue code.
@my_flow.query_handler(name="run_query") # Name is optional, use the function name by default
def run_query(query: str) -> cocoindex.QueryOutput:
# 1) Perform your query against the input `query`
...
# 2) Return structured results
return cocoindex.QueryOutput(results=[{"filename": "...", "text": "..."}])CocoInsight
We are launching a major feature in both CocoIndex and CocoInsight to help users iterate quickly on the indexing strategy, and trace back all the way to the data.
:tada: Announcement: https://cocoindex.io/blogs/query-support
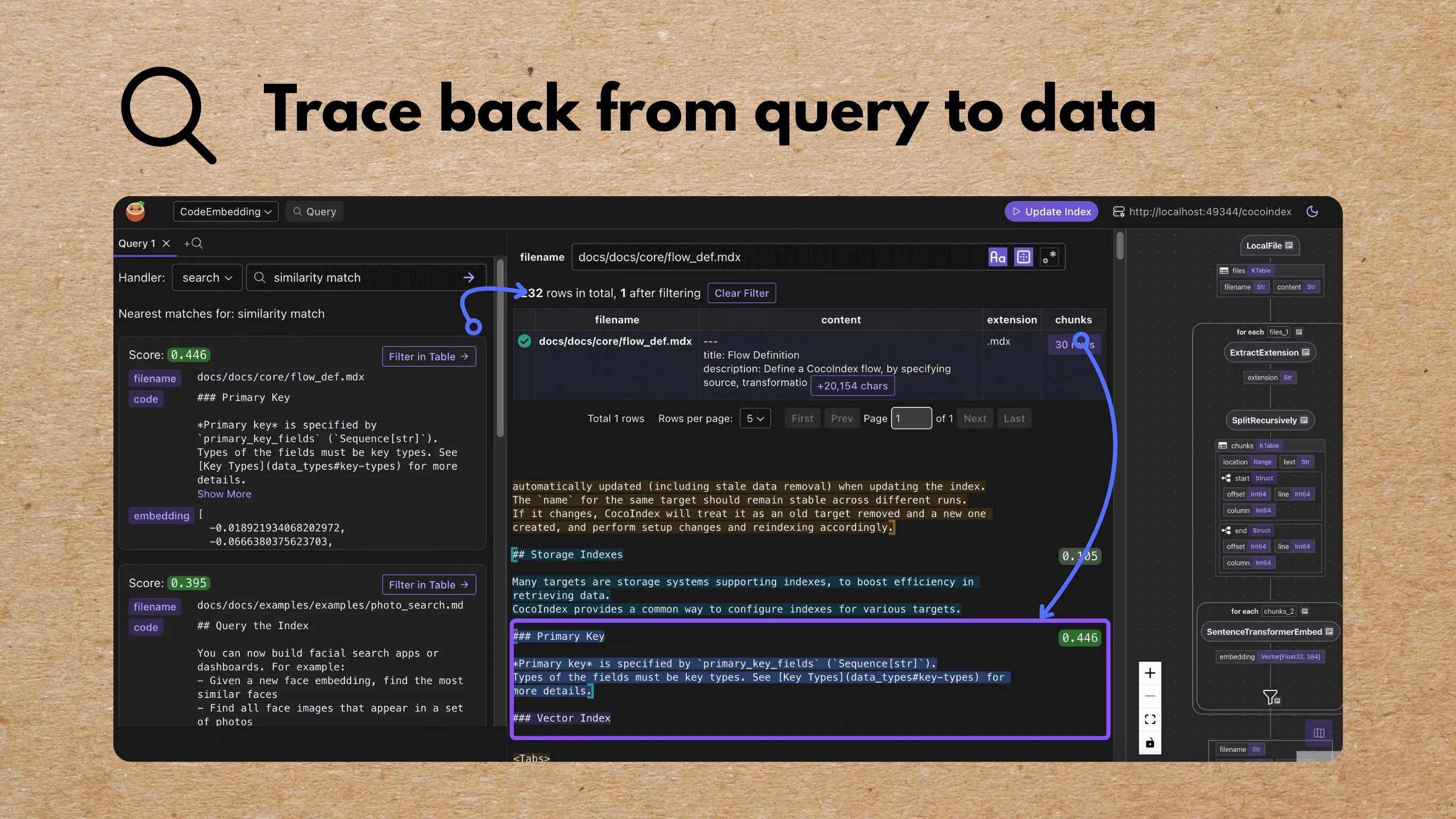
Demo:
https://www.youtube.com/watch?v=crV7odEVYTE
Python SDK
Support pydantic with field-level description for structured extraction
ExtractByLlm is one of the native building blocks in CocoIndex to make it easier to extract structured information from unstructured documents with LLM.
This change allows users to directly define the description at the field level when doing structured extraction.
For example, a user could define the following class:
class ProductTaxonomyInfo(BaseModel):
"""
Taxonomy information for the product.
"""
taxonomies: list[ProductTaxonomy] = Field(
...,
description="Taxonomies for the current product."
)
complementary_taxonomies: list[ProductTaxonomy] = Field(
...,
description="Think about when customers buy this product, what else they might need as complementary products. Put labels for these complentary products."
)And you can plug it into any ExtractByLlm transformation.
taxonomy = data["detail"].transform(
cocoindex.functions.ExtractByLlm(
llm_spec=cocoindex.LlmSpec(
api_type=cocoindex.LlmApiType.OPENAI, model="gpt-4.1"
),
output_type=ProductTaxonomyInfo,
)
)support @cocoindex.settings and make init() optional
A more flexible approach is to provide a setting function that returns a cocoindex.Settings dataclass object. The setting function can have any name, and needs to be decorated with the @cocoindex.settings decorator, for example:
@cocoindex.settings
def cocoindex_settings() -> cocoindex.Settings:
return cocoindex.Settings(
database=cocoindex.DatabaseConnectionSpec(
url="postgres://cocoindex:cocoindex@localhost/cocoindex"
)
)This setting function will be called once when CocoIndex is initialized, whenever you’re running the CLI or your own main script, hence you can provide settings in a single way within your code. Once the settings function is provided, environment variables will be ignored.
Building blocks
Postgres source enhancements
Postgres source allows users to take data from any PostgreSQL table as input. Schema of the imported data is automatically inferred from the source table. It supports change-capture based on LISTEN/NOTIFY.
- Composite-key Postgres source: Auto-detects schema, supports single or multi-column keys, and maps Postgres → CocoIndex types. #910
- Faster small-row performance: Refactored Postgres source and
list()API for high-volume, many-small-rows workloads. #948 - Real-time Postgres updates: New
LISTEN/NOTIFYchange-capture mode with auto channel naming and full source wiring. #952, #953, #954, #955
Postgres target enhancements
- Postgres filtering support: added the ability to apply filters directly on Postgres sources, enabling more efficient data selection and ingestion. #1178
- Half-precision vector (
halfvec) support: addedhalfvecsupport for Postgres targets, reducing storage overhead for embeddings while maintaining compatibility with vector operations. #1171 - Schema support for Postgres targets: users can now specify and write to custom schemas, allowing better organization in multi-schema database setups #1138
Target enhancements - new & improved built-ins
Support for LanceDB target
We are officially supporting LanceDB as a target. Get started with LanceDB target.
Postgres target enhancements
Target Attachment / PostgreSQL SQL Command Attachment — The core engine now supports attachments on targets, including a PostgresSqlCommand type that allows you to execute arbitrary SQL (setup/teardown) on the target side #1131.
Example (create a custom index):
collector.export(
"doc_embeddings",
cocoindex.targets.Postgres(table_name="doc_embeddings"),
primary_key_fields=["id"],
attachments=[
cocoindex.targets.PostgresSqlCommand(
name="fts",
setup_sql=(
"CREATE INDEX IF NOT EXISTS doc_embeddings_text_fts "
"ON doc_embeddings USING GIN (to_tsvector('english', text));"
),
teardown_sql= "DROP INDEX IF EXISTS doc_embeddings_text_fts;",
)
],
)Check the full documentation here.
Neo4j improvements
- Support vector index method and
- Changed the KEY constraint to UNIQUE in Neo4j mappings for compatibility with the Community Edition. #983
New LLM integrations - add AWS Bedrock LLM support
CocoIndex provides builtin functions integrating with various LLM APIs, for various inference tasks. In the new release we’ve added AWS Bedrock LLM Support in addition to all major commercial and open source LLM / API supported. See full documentation here.
Native functions
CocoIndex’s native building blocks for codebase indexing received major upgrades this month, driven by extensive community feedback. We’ve refined language detection, splitting strategies, and parsing robustness for diverse codebases.
DetectProgrammingLanguageautomatically identifies programming languages from file content or extensions, improving indexing precision across mixed-language repositories.- Improved
SplitRecursivelyfunction. Improved itstree-sitterbased chunking method with better markdown handling, richer punctuation handling for plain text, configurable chunk overlap, and supported Solidity. SplitBySeparatorslightweight regex-only splitter for simpler, high-performance text segmentation workflows.
To see how to build customized codebase indexing, you can get started here.
New blogs and examples:
https://cocoindex.io/blogs/etl-to-snowflake
-
Incrementally Transform Structured + Unstructured Data from Postgres with AI
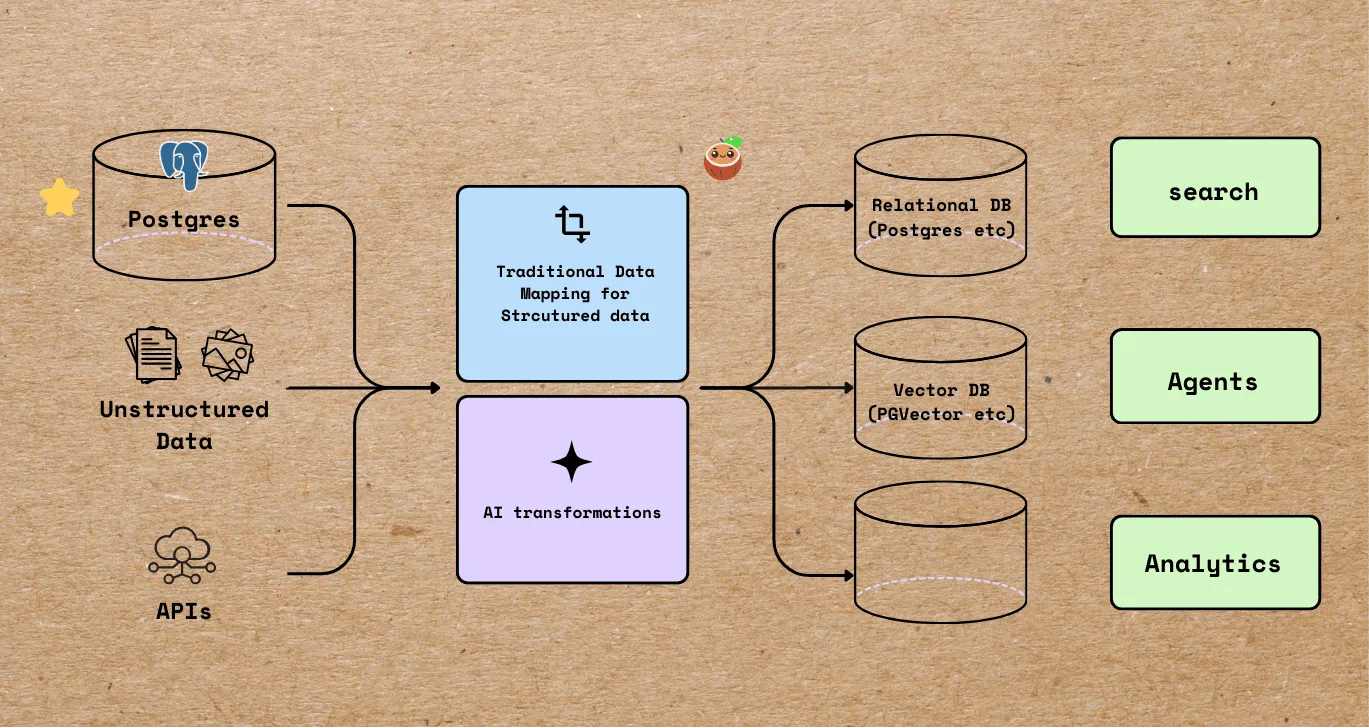 This blog introduces the new PostgreSQL source and shows how to take data from PostgreSQL table as source, transform with both AI models and non-AI calculations, and write them into a new PostgreSQL table for semantic + structured search.
This blog introduces the new PostgreSQL source and shows how to take data from PostgreSQL table as source, transform with both AI models and non-AI calculations, and write them into a new PostgreSQL table for semantic + structured search. -
Automated invoice processing with AI, Snowflake and CocoIndex - with incremental processing
 This blog shows how to automate invoice processing using CocoIndex, an open-source ETL framework built for AI-powered data transformation. It walks through how to extract supplier invoices from Azure Blob Storage, use LLMs to read and structure the data, and then load everything into Snowflake — all with incremental processing for scalability and data freshness.
This blog shows how to automate invoice processing using CocoIndex, an open-source ETL framework built for AI-powered data transformation. It walks through how to extract supplier invoices from Azure Blob Storage, use LLMs to read and structure the data, and then load everything into Snowflake — all with incremental processing for scalability and data freshness. -
Build a Visual Document Index from multiple formats all at once - PDFs, Images, Slides - with ColPali
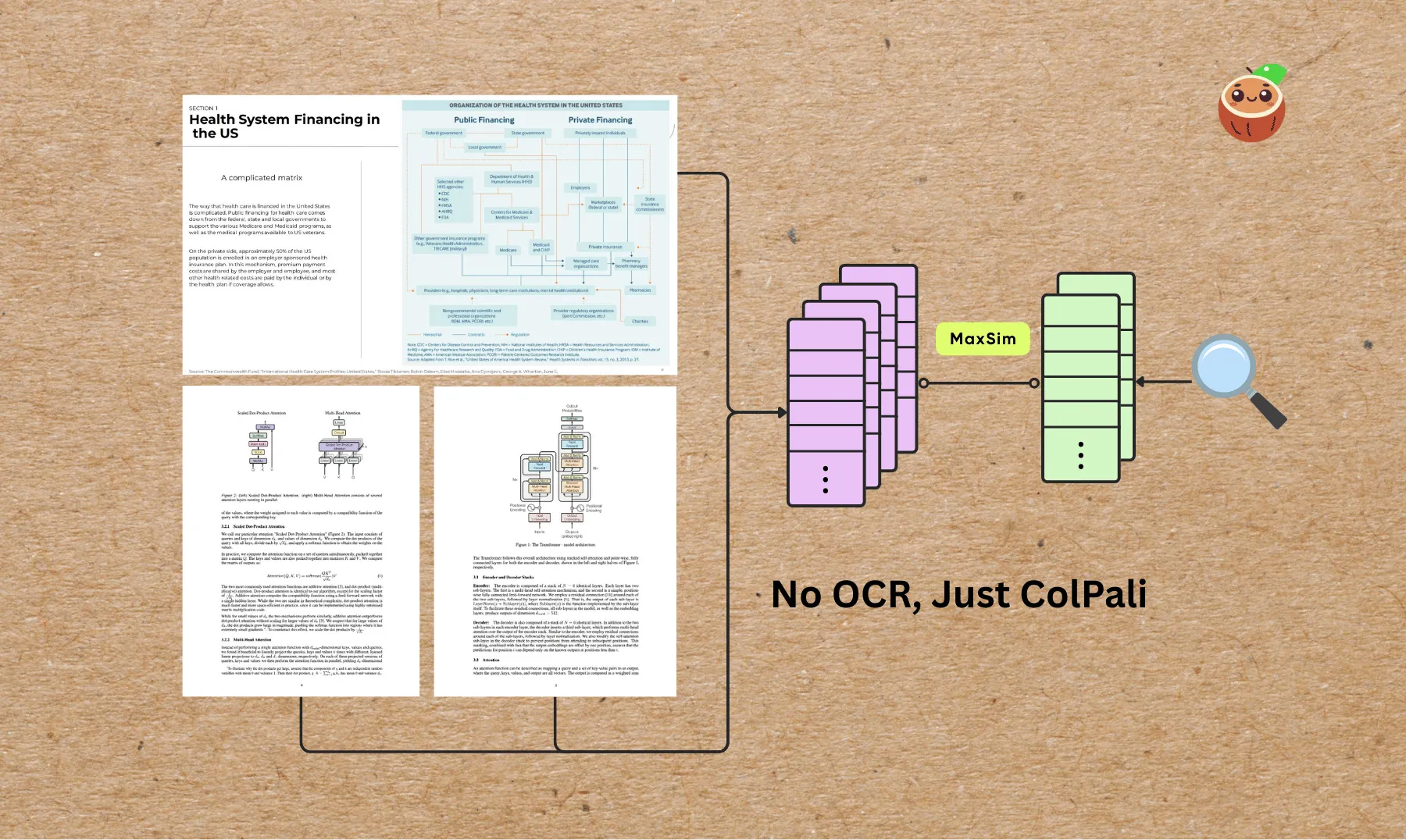 This blog shows how to build a visual document index from multiple formats all at once - PDFs, Images, Slides - with ColPali. It walks through how to use ColPali to extract text from multiple formats, and then use CocoIndex to index the text into a visual document index.
This blog shows how to build a visual document index from multiple formats all at once - PDFs, Images, Slides - with ColPali. It walks through how to use ColPali to extract text from multiple formats, and then use CocoIndex to index the text into a visual document index.
Thanks to the Community 🤗🎉
Welcome new contributors to the CocoIndex community! We are so excited to have you!
@MrAnayDongre

Thanks @MrAnayDongre for the work on SplitBySeparators regex-only splitter #1010, enabling simpler and high-performance text segmentation workflows.
@lemorage

@banrovegrie

Thanks @banrovegrie for fixing the Gemini embedding configuration and exposing Postgres index tuning #1050, improving integration reliability.
@thisisharsh7

Thanks @thisisharsh7 for the work on:
- adding the
—resetflag for setup, update, and server commands #1106 - improving Postgres schema support #1138
- enhancing error messages when no flows are registered #1070
- making example paths OS-friendly #1066
These updates improve usability, reliability, and cross-platform compatibility, making workflows smoother and more robust for all users.
@Davda-James

Thanks @Davda-James for the work on:
- binding Pydantic models to CocoIndex Struct #1072
- reorganizing the Python SDK package structure #1081, #1082
- generating full CLI docs and adding them to pre-commit hooks #1096
- collecting additional row processing counters for stats #1105
- and splitting
convert.pyinto modular components #1120
These updates improve developer productivity, maintainability, and observability, making the Python SDK and CLI easier to use, extend, and monitor for large-scale workflows.
@princyballabh

Thanks @princyballabh for auto-applying safe defaults for missing fields in load_engine_object #1104,
improving reliability and reducing errors when loading engine objects.
@shresthashim

Thanks @shresthashim for implementing str and repr methods for Python schema classes #1095,
enhancing developer experience when working with schema objects.
@belloibrahv

Thanks @belloibrahv for the work on:
- Adding AWS Bedrock LLM #1173
- Neo4j vector index methods #1111
- Field-level descriptions to
FieldSchema#1087
These updates expand integration capabilities, improve graph database support, and enhance schema clarity.
@mensonones

Thanks @mensonones for updating documentation to use cocoindex update —setup main #1093,
making setup instructions clearer.
@esther-anierobi

Thanks @esther-anierobi for improving documentation navigation #1136.
@TheVijayVignesh

Thanks @TheVijayVignesh for moving built-in sources to top-level navigation in the docs #1119, improving documentation structure.
@aryasoni98

Thanks @aryasoni98 for adding tests for json_schema.rs #1133,
improving code reliability.
@skalwaghe-56

Thanks @skalwaghe-56 for adding the legacy-states-v0 Cargo feature for backward compatibility #1135,
making it easier to maintain legacy state logic.
@siddharthbaleja7

Thanks @siddharthbaleja7 for flattening recursion in SplitRecursively to prevent stack overflow #1127,
improving stability.
Support us
We are constantly improving CocoIndex, more features are coming soon! Stay tuned and follow us by starring our GitHub repo.

CocoIndex
An incremental engine for long-horizon agents — always-fresh, explainable data, one Python file.
About the author.

Maintainer of CocoIndex, Ex-Google Infra Lead. Writes about incremental data infrastructure, Rust internals, and the engineering decisions behind the engine.