CocoIndex Changelog 2025-08-18


We’ve shipped 20+ releases — packed with production-ready features, scalability upgrades, and runtime improvements. 🚀 Huge thanks to our amazing users for the feedback and for running CocoIndex at scale!
Full changelog: v0.1.58...v0.1.79.
We've made it to Github Rust Trending this week along with some other cool projects like OpenAI Codex, Tree-sitter, Polars, LanceDB, and more!
Performance, scalability, and reliability
CocoIndex is built to be production-ready from day one, empowering teams to process data at scale without compromising performance or reliability. Our continuous improvements to the runtime ensure that CocoIndex can handle large-scale, real-time workloads with ease.
Control processing concurrency in CocoIndex
CocoIndex now has concurrency control to balance maximum throughput with system stability. The default settings work well for most cases, but we also expose layered controls for advanced scenarios.
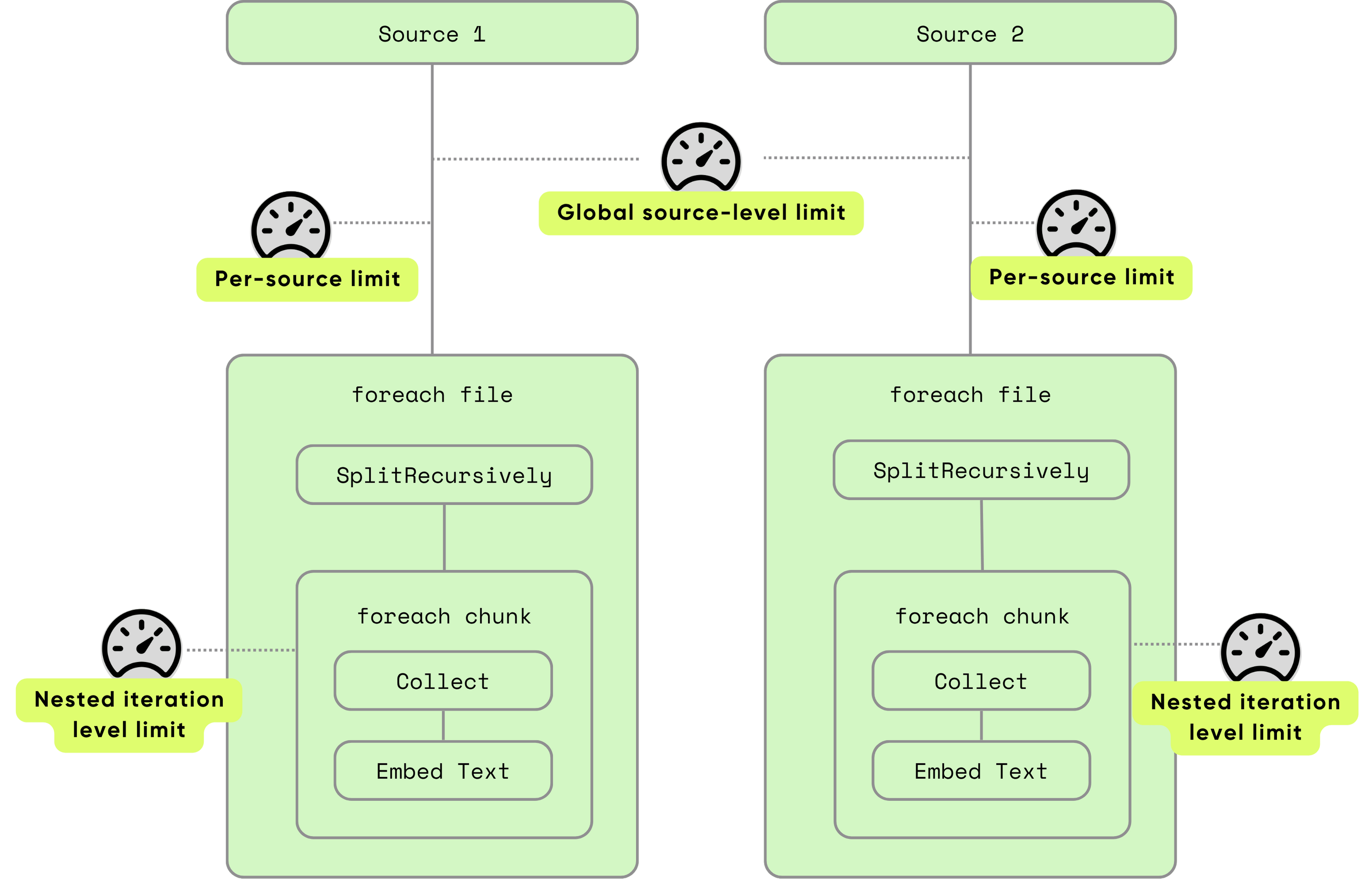
- Global limits — keep total concurrency within safe thresholds
- Per-source limits — tune for different workloads
- Nested iteration limits — control fan-out during chunk/sub-row processing
Read more about the concurrency control in the blog post.
Auto-retry for remote LLM requests
CocoIndex now automatically backoff and retry rate-limited requests (HTTP 429) to remote LLMs, ensuring smoother and more resilient data processing. More optimizations are coming soon.
Automatically combined update operations
CocoIndex now automatically combines multiple update calls into a single operation when it's safe to do so. This optimization allows users to blindly call the update API whenever an update is potentially needed, without worrying about too frequent or conflict updates.
Enhanced PostgreSQL connection pooling
The latest update introduces configurable minimum and maximum connection limits for PostgreSQL connections.
Check out DatabaseConnectionSpec in the docs.
This enhancement allows fine-tuning connection pool settings to better match your workload requirements,
improving resource utilization and performance.
API updates
Custom targets
CocoIndex envisions building pipelines like assemble building blocks by standardizing the interfaces. It should be composable, interchangeable, and fun to build. We provide a rich set of default components to help you build vector indexes, knowledge graphs, and your own custom building block creations, with a standard interface.
Now, we’re introducing custom targets, further pushing the boundaries of what you can build with CocoIndex. You define two things:
- Target Spec – how to configure the target (such as setting a file path or API key).
- Target Connector – how to write data to that target (the logic).
You can think of this as plugging in your own target with a few lines of Python.
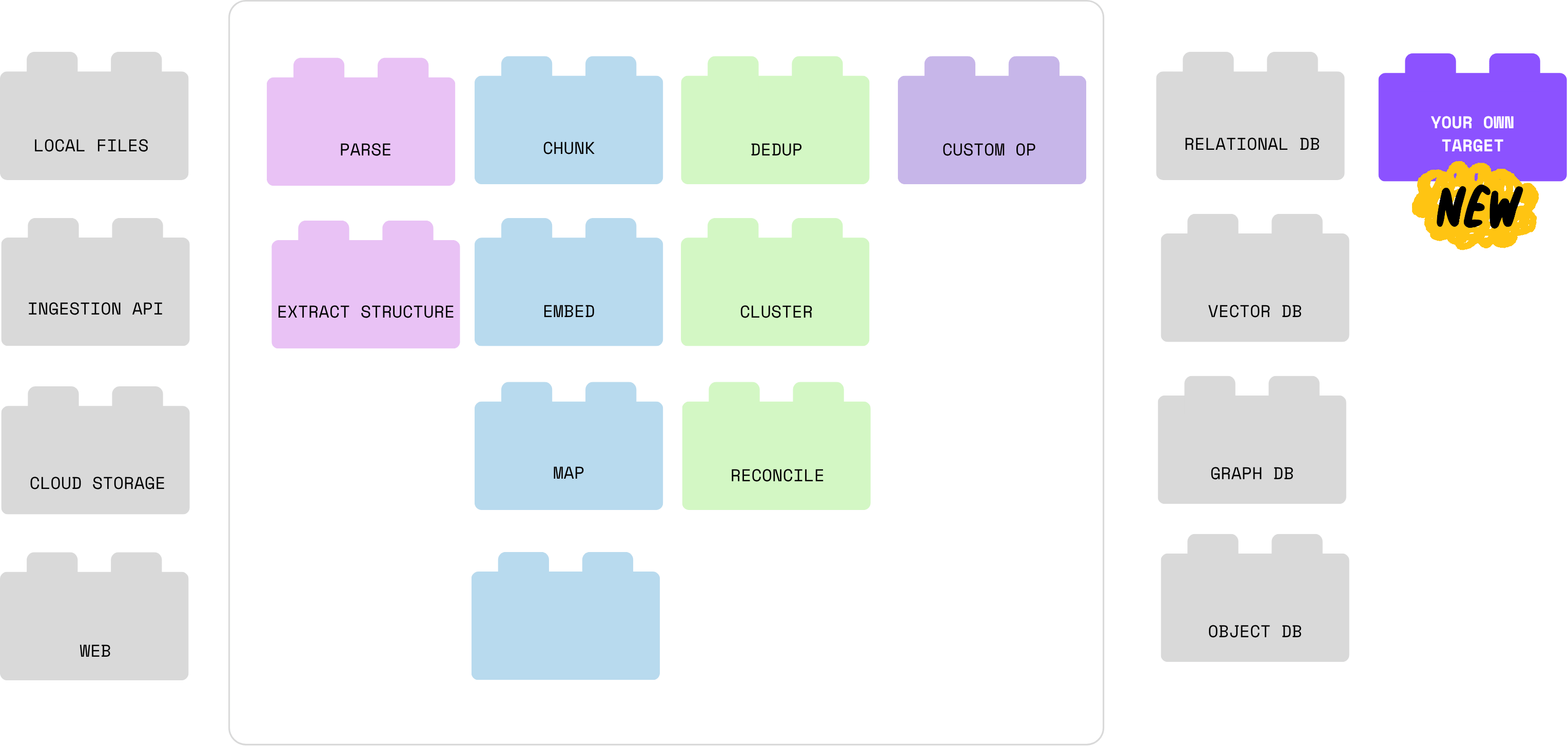
Read more about custom targets with an example in the blog post. Read the documentation for more details.
New transform method in FlowBuilder
The new FlowBuilder.transform() method provides an alternative to the chained-style transformation, and makes the flow more clear when the CocoIndex function takes more than one arguments.
e.g. in the multi_format_indexing example, instead of writing this:
doc["pages"] = doc["filename"].transform(file_to_pages, content=doc["content"])
Now you can write:
doc["pages"] = flow_builder.transform(
file_to_pages, filename=doc["filename"], content=doc["content"]
)
Status update polling API
We introduced capabilities for tracking and polling the status of long-running data flows.
A new next_status_updates() method has been added for the FlowLiveUpdater class.
This API enables users to programmatically poll for status changes and receive updates during live flow execution.
This allows you to react to updates in your application, for example, by notifying users or triggering downstream processes, like an agentic workflow.
while True:
updates = my_updater.next_status_updates()
for source in updates.updated_sources:
# Perform downstream operations on the target of the source.
run_your_downstream_operations_for(source)
# Break the loop if there's no more active sources.
if not updates.active_sources:
break
Read the documentation here.
Flow identifier naming validation
This validation standardizes name patterns for CocoIndex flow and field names, ensures relevant backend resources (e.g. tables) can be named directly based on these names.
Flow identifiers are now enforced to match the pattern [a-zA-Z_][a-zA-Z0-9_]* and no more than 64 characters.
You’ll experience improved reliability and more predictable behavior when defining and referencing flows, reducing risks of unexpected bugs or collisions.
Typing
Multi-dimensional vector
CocoIndex now provides robust and flexible support for typed vector data — from simple numeric arrays to deeply nested multi-dimensional vectors. This support is designed for seamless integration with high-performance vector databases such as Qdrant, and enables advanced indexing, embedding, and retrieval workflows across diverse data modalities.
CocoIndex automatically infers types, so when defining a flow, you don’t need to explicitly specify any types. You only need to specify types explicitly for return types of custom functions, etc.
In CocoIndex, we represent multi-dimensional vector using Vector[Vector[T, N], M], meaning M vectors, each of dimension N. M and N are optional - CocoIndex doesn't require them to be fixed, while some targets have requirements, e.g. a multi-vector exported to Qdrant needs to have a fixed inner dimension, i.e. Vector[Vector[T, N]].
If you are building multimodal search engine with Qdrant, this is the mapping you need to know:
| CocoIndex Python Type | Qdrant Type |
|---|---|
Vector[Float32, Literal[N]] | Dense Vector |
Vector[Vector[Float32, Literal[N]]] | MultiVector |
| Other types | Stored in Qdrant’s JSON payload |
Read more about multi-dimensional vector support in the blog post.
None propagation behavior
A function may specify whether each input argument is optional or not. Non-optional argument means the function needs a known value for the argument to work.
However, it doesn't forbid the argument to be None at runtime. When a non-optional argument receives a None value, the function execution is skipped and the result is None.
For your custom function, this none-propagation is also automatic whenever you annotate your argument with a non-optional type (e.g. T instead of T | None / Optional[T]).
For example, for SplitRecursively function, the text and chunk_size arguments are not optional. If the input value of either of them is None, the function will return None.
Read more about None values and None propagation here.
Support unannotated type bindings on Rust->Python path
Now you don't have to provide explicit type annotations for Python variables binding to values coming from the Rust engine (e.g. arguments of custom functions). When it's omitted, we create Python values in the default type according to specific CocoIndex data type. For example, for the custom function in multi_file_indexing example, you can write:
@cocoindex.op.function()
def file_to_pages(filename, content) -> list[Page]:
...
which omits explicit type hints for filename and content arguments.
When come to Struct types, we use dict[str, Any] where the key is the name of each field.
See our data types documentation for more details.
Besides, we also enhanced robustness of value bindings for Union types.
ISO8601 parsing enhancement
The ISO8601 date/time parser now supports fractional values, allowing more precise parsing of timestamps with fractional seconds. This improvement aligns parsing behavior with wider ISO8601 variations that include decimal fractions in time units, enhancing temporal data accuracy and compatibility with external data sources.
Expanded LLM, cloud AI & data source integrations
We integrated with the following LLM APIs:
- vLLM (for text generation)
- Ollama (for text embedding)
- Google Vertex AI (for text generation and embedding)
We support the following types of LLM APIs. Read latest docs.
| API Name | LlmApiType enum | Text Generation | Text Embedding |
|---|---|---|---|
| OpenAI | LlmApiType.OPENAI | ✅ | ✅ |
| Ollama | LlmApiType.OLLAMA | ✅ | ✅ New |
| Google Gemini | LlmApiType.GEMINI | ✅ | ✅ |
| Vertex AI | LlmApiType.VERTEX_AI | ✅ New | ✅ New |
| Anthropic | LlmApiType.ANTHROPIC | ✅ | ❌ |
| Voyage | LlmApiType.VOYAGE | ❌ | ✅ |
| LiteLLM | LlmApiType.LITE_LLM | ✅ | ❌ |
| OpenRouter | LlmApiType.OPEN_ROUTER | ✅ | ❌ |
| vLLM | LlmApiType.VLLM | ✅ New | ❌ |
Example Usage:
cocoindex.LlmSpec(
api_type=cocoindex.LlmApiType.VERTEX_AI,
model="gemini-2.0-flash",
api_config=cocoindex.llm.VertexAiConfig(project="your-project-id"),
)
ColPali embedding
CocoIndex now supports native integration with ColPali — enabling multi-vector, patch-level image indexing using cutting-edge multimodal models. With just a few lines of code, you can now embed and index images with ColPali’s late-interaction architecture, fully integrated into CocoIndex’s composable flow system.
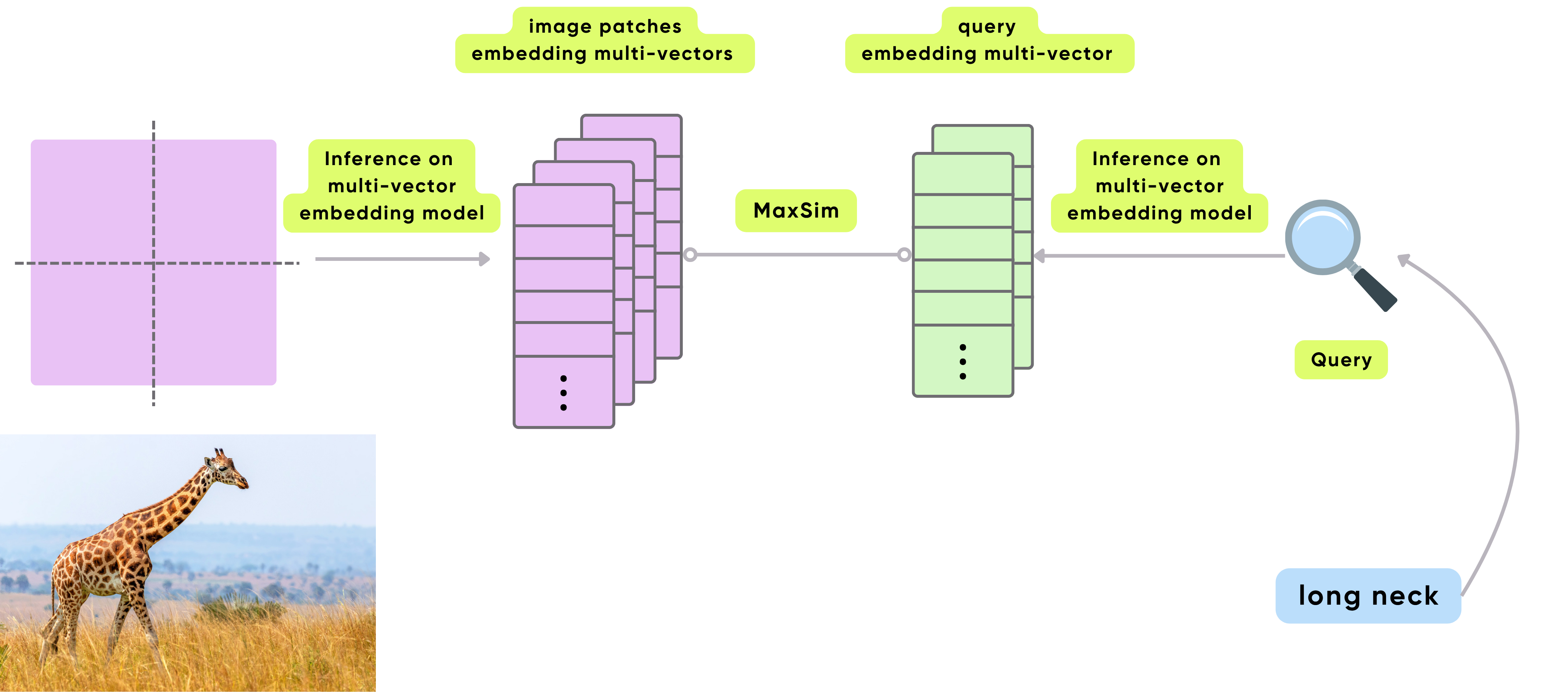
Read more about ColPali integration in the blog post.
We are constantly adding new to support your use case, please contact us if you need any support. You can also use custom ops to bring any of your custom logic for LLM inference.
Azure Blob Storage as data source
CocoIndex now supports Azure Blob Storage as a data source. Read more about the integration here.
cocoindex.StorageSpec(
api_type=cocoindex.StorageApiType.AZURE_BLOB_STORAGE,
account_name="your-account-name",
container_name="your-container-name",
)
CLI clarity improvements & vector storage notes
- CocoIndex now shows clear notes when vectors are stored as JSON in either Postgres or Qdrant. In some deployments, vectors may be stored as JSON instead of native vector column types — affecting performance, indexing, and retrieval methods. The new note alerts users so they can locate potential bugs earlier (e.g. forget to specify vector length in type annotation).
- Improved the clarity of CLI output messages and added more detailed error messages during interactive and automated runs.
- Added context-sensitive hints with more actionable guidance when running in live mode.
Tutorials
We're expanding the documentation with more in-depth tutorials!
Live updates
CocoIndex is designed to keep your indexes synchronized with your data sources. This is achieved through a feature called live updates, which automatically detects changes in your sources and updates your indexes accordingly. This tutorial walk you through deep tech details of how live updates work, and how to use it in your own projects.
Checkout the tutorial.
Manage flow dynamically
You write a function, a.k.a. flow definition, to define indexing logic. Sometimes you want to reuse the same flow definition for multiple flow instances (a.k.a. flow), e.g. each takes input from different sources, exports to different targets, and even with slightly different parameters for transformation logic.
Checkout the tutorial.
ColPali - multi-modal search engine
In this tutorial, we’ll walk through how to build a multi-modal search engine with CocoIndex and ColPali. We’ll show how to embed and index images with ColPali’s late-interaction architecture, fully integrated into CocoIndex’s composable flow system.
Checkout the blog and source code.
Custom targets
In this tutorial, we'll explain how custom targets work and a simple example to continuously convert JSON from local files to HTML and export them as custom targets.
Checkout the blog and source code.
Face Detection - build your own Google Photos search
In this blog, we’ll walk through a comprehensive example of building a scalable face recognition pipeline using CocoIndex. We’ll show how to extract and embed faces from images, structure the data relationally, and export everything into a vector database for real-time querying.
Checkout the blog and source code.
Rust ownership access
Open source is about knowledge sharing! In this blog, we are proposing a mental model to help you understand Rust ownership and memory safety models. By clearly separating and defining ownership and exclusive versus shared access, Rust's complexity transforms into logical clarity. Moves, borrows, Send, Sync, and runtime checks become intuitive and predictable tools in your programming toolbox.
Checkout the blog.
Academic papers indexing
In this tutorial, we will walk through a comprehensive example of indexing research papers with extracting different metadata — beyond full text chunking and embedding.
Checkout the blog and source code.
Thanks to the community 🤗🎉
Welcome new contributors to the CocoIndex community! We are so excited to have you!
@lemorage

@vumichien

Thanks to @vumichien for contributions around data type conversion and for making the data type environment more robust between Rust and Python.
@kingkushal16

Thanks to @kingkushal16 for the contributions! We appreciate the work on adding default values for field decoding #788.
@theparthgupta

Thanks to @theparthgupta for the contributions! We appreciate the work on adding naming validation for flow identifiers #779 to make the system more robust.
@par4m

@wykrrr

Support us
We are constantly improving CocoIndex, more features are coming soon! Stay tuned and follow us by starring our GitHub repo.