Adaptive Batching - 5x throughput on your data pipelines


CocoIndex just launched batching support to CocoIndex functions. With batching, throughput increased to ~5X the non-batched baseline (≈80% lower runtime) when embedding the CocoIndex codebase using sentence-transformers/all-MiniLM-L6-v2 model.
Why batching makes processing fast
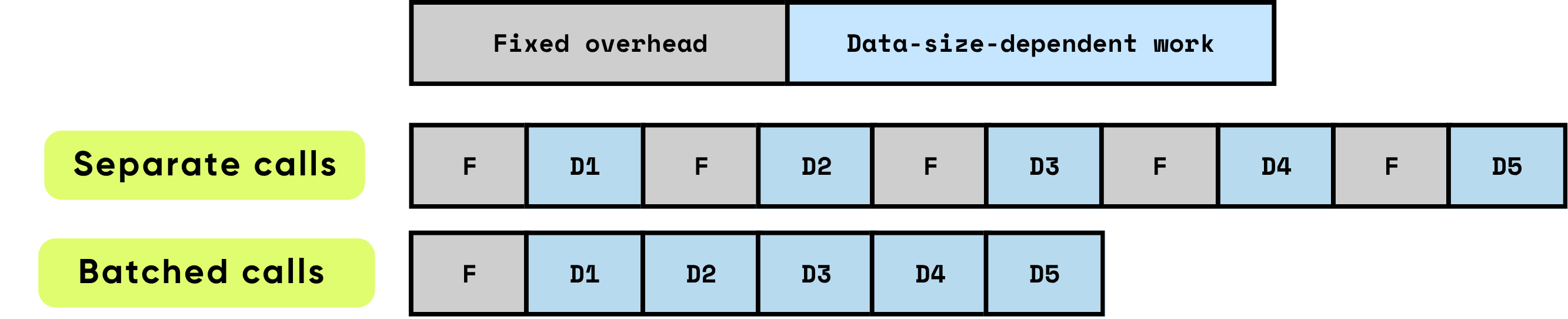
When we call a function or remote API, every call has:
-
Fixed overhead you pay once per call: GPU kernel launch setup, Python/C transition, scheduling, memory allocator work, framework bookkeeping, etc.
-
Data-size-dependent work that scales with input: floating-point operations (FLOPs) for the model, bytes copied, tokens processed.
Doing 1,000 items one by one pays the fixed overhead 1,000 times. Doing them in batches pays that overhead once per batch, and the hardware can run the size-dependent work more efficiently (fewer launches, better cache use, fuller pipelines).
Batching helps because it:
-
Spreads one-time overhead across many items. You do fewer GPU kernel launches and fewer Python-to-C boundary crossings etc.
-
Lets the GPU run bigger, more efficient matrix math. Larger batches map to dense matrix multiplies (General Matrix–Matrix Multiplication, a.k.a. GEMM), which use the hardware more effectively (higher utilization).
-
Cuts down on data copies. You reduce transfers between CPU memory and GPU memory — H2D (Host-to-Device) and D2H (Device-to-Host) — so more time is spent computing, not moving bytes.
What batching looks like for normal Python code
Non-batching code – simple but less efficient
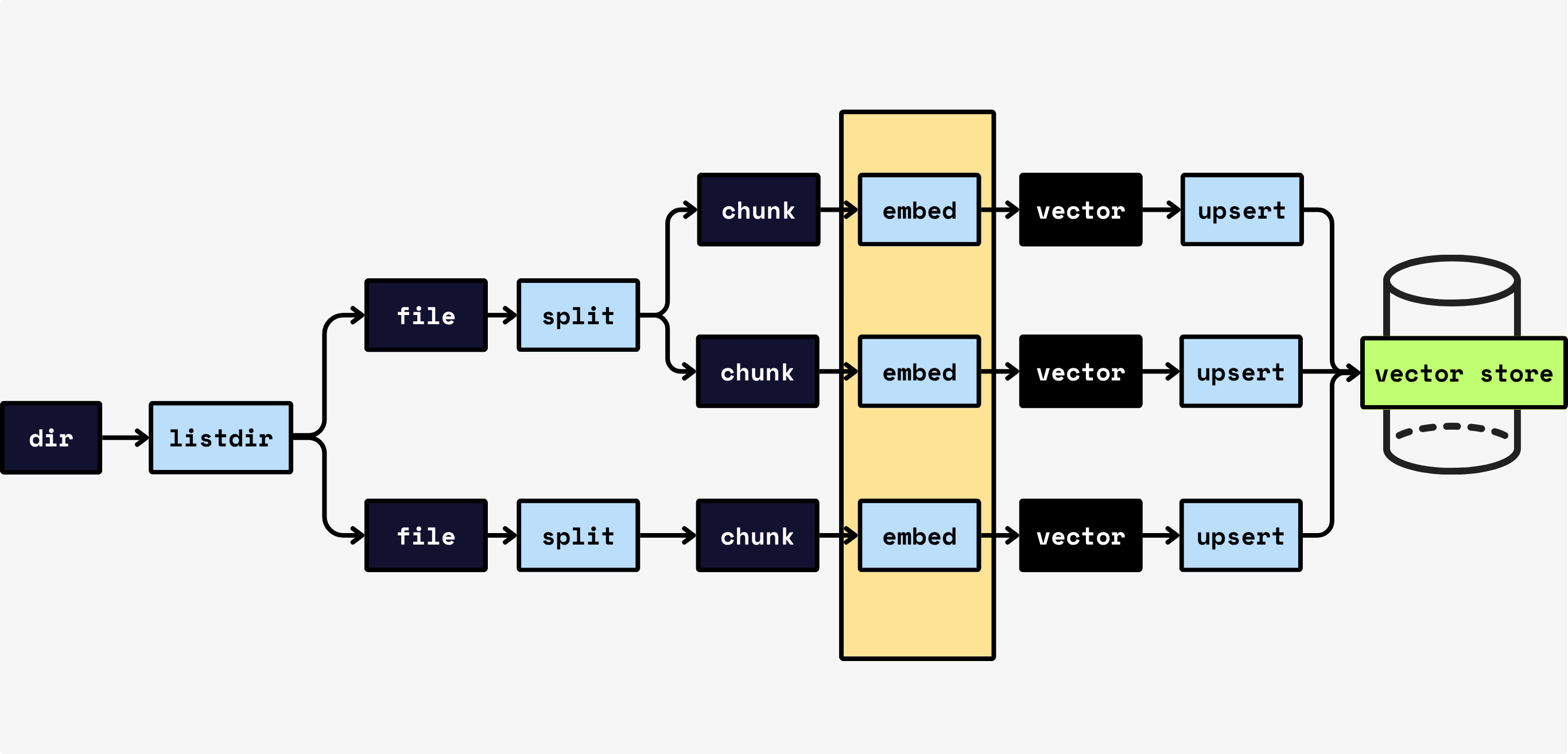
The most natural way to organize a pipeline is to process data piece-by-piece. For example, a two-layer loop like this:
for file in os.listdir(directory):
content = file.read()
chunks = split_into_chunks(content)
for chunk in chunks:
vector = model.encode([chunk.text]) # one item at a time
index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
This is easy to read and reason about: each chunk flows straight through multiple steps.
Batching manually – more efficient but complicated
You can speed it up by batching, but even the simplest “just batch everything once” version makes the code significantly more complicated:
# 1) Collect payloads and remember where each came from
batch_texts = []
metadata = [] # (file_id, chunk_id)
for file in os.listdir(directory):
content = file.read()
chunks = split_into_chunks(content)
for chunk in chunks:
batch_texts.append(chunk.text)
metadata.append((file.name, chunk.offset))
# 2) One batched call (library will still mini-batch internally)
vectors = model.encode(batch_texts)
# 3) Zip results back to their sources
for (file_name, chunk_offset), vector in zip(metadata, vectors):
index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
Moreover, batching everything at once is usually not ideal, e.g., the next steps can only start after this step is done for all data.
CocoIndex's batching support
CocoIndex bridges the gap and allows you to get the best out of the two – keep the simplicity of your code by following the natural flow, while getting the efficiency from batching provided by CocoIndex runtime.
We already enabled batching support for the following builtin functions:
- EmbedText
- SentenceTransformerEmbed
- ColPaliEmbedImage
- ColPaliEmbedQuery
It doesn’t change the API. Your existing code will just work without any change – still following the natural flow, while enjoying the efficiency of batching.
For custom functions, enabling batching is as simple as:
- Set
batching=Truein the custom function decorator. - Change the arguments and return type to
list.
For example, if you want to create a custom function that calls an API to build thumbnails for images.
@cocoindex.op.function(batching=True)
def make_image_thumbnail(self, args: list[bytes]) -> list[bytes]:
...
See the batching documentation for more details.
How CocoIndex batches
Common approaches
To batch requests, you first accumulate them in a queue, then decide when to flush that queue as a batch. Two widely used policies are:
-
Time-based (W ms): Flush whatever arrived in the last W milliseconds.
- Pros: predictable wait bound; simple.
- Cons: adds idle latency when traffic is sparse; needs tuning per workload.
-
Size-based (K items): Flush when at least K items are waiting.
- Pros: predictable batch size; easy to reason about memory.
- Cons: under sparse traffic, the head request can wait too long; still needs tuning.
Many systems combine them (“flush when W or K triggers first”), which helps — but you’re still tuning knobs and making trade-offs that shift with traffic.
CocoIndex’s approach
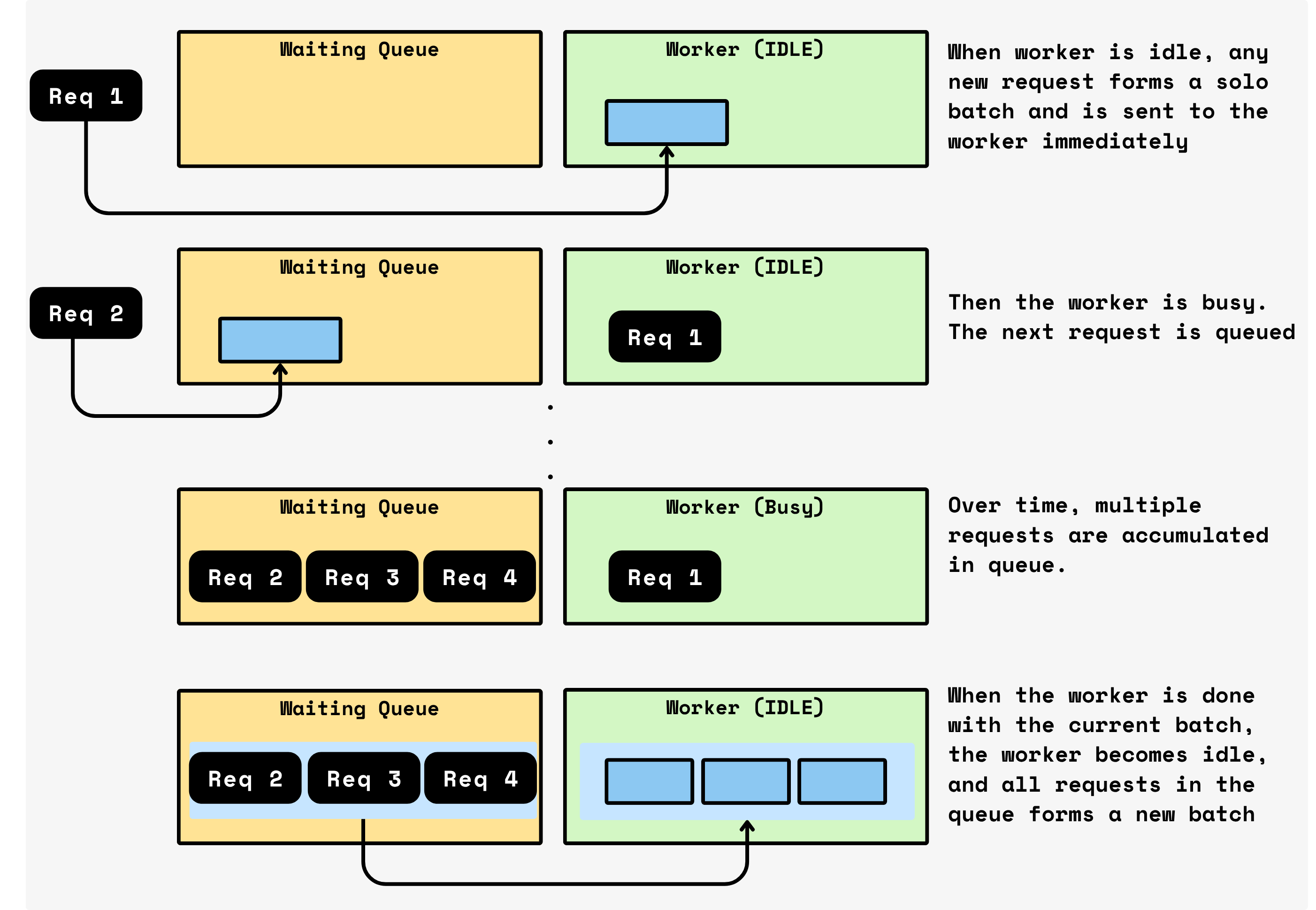
Framework level: adaptive, knob-free
CocoIndex keeps batching simple:
-
While a batch is running on the device, new requests keep queuing.
-
When that batch finishes, CocoIndex ships all currently queued requests as the next batch window and immediately starts processing again.
-
No timers. No target batch size. The batch naturally reflects whatever arrived during the previous service time.
Why is this good?
-
Low latency when sparse: With few requests, batches are tiny (often size 1), so you’re effectively running at near single-call latency.
-
High throughput when busy: When traffic spikes, more requests accumulate during the in-flight batch, so the next batch is larger — utilization rises automatically.
-
No tuning: You don’t need to tune W or K. The system adapts to your traffic pattern by design.
Function level: pack the batch intelligently
Each function receives the batch window (all queued requests at that moment) and decides how to process it efficiently and safely for its model/library.
Using SentenceTransformerEmbed function as an example. The underlying sentence-transformer library accepts batches with arbitrary length, but splits them into micro-batches (default size: 32) so that each can fit into the device memory and keep kernels in the model's sweet spot. We use the default micro-batch size.
Besides, transformer runtimes pad every sequence in a batch to the length of the longest one so the GPU can run uniform, fast kernels — short texts pay the cost of the longest text in the batch (e.g., mixing 64-token with 256-token items makes the 64-token ones ~4X more expensive). We sort by token count and form micro-batches of similar lengths to keep padding minimal and throughput high.
Other functions can simply ship the entire batch to the backend, or apply their own packing (e.g., SIMD tiles, merge-writes). The framework is agnostic. It just delivers the batch window promptly.
Performance evaluation
We ran all benchmarks on a MacBook Pro (Apple M1 Pro, 16 GB unified memory, 2022). For each configuration:
-
We run on two different versions, batching on (cocoindex v0.3.1) and batch off (cocoindex v0.2.23).
-
We report two timings: (1) end-to-end benchmark wall-clock time, and (2) the cumulative time inside the embedding function (where batching happens).
-
We executed each test 5 times, discarded the fastest and slowest run to dampen outliers, and reported the mean of the remaining three runs (a 20% trimmed mean).
text_embedding and code_embedding
We run on the 2 basic examples from cocoindex:
-
text_embedding: with 3 input files, 106 chunks in total.
-
code_embedding: with 273 input files, 3383 chunks in total.
Both are using the SentenceTransformerEmbed function, using the all-MiniLM-L6-v2 embedding model (with 22.7M parameters).
This is the evaluation outcome:
| example name | end-to-end execution time | runtime in function to batch | ||||
|---|---|---|---|---|---|---|
| off (s) | on (s) | saving | off (s) | on (s) | saving | |
| text_embedding | 1.959 | 0.630 | 67.84% | 1.853 | 0.567 | 69.42% |
| code_embedding | 58.931 | 12.516 | 78.76% | 58.343 | 12.117 | 79.23% |
code_embedding has significantly more chunks, so there are more opportunities for batching, thus the runtime saving is more significant.
code_embedding on different micro-batch size
We experimented with different micro batch sizes on sentence-transformer:
| micro batch size | end-to-end execution time | runtime in function to batch | ||
|---|---|---|---|---|
| runtime (s) | saving | runtime (s) | saving | |
| batch off | 58.931 | N/A | 58.343 | N/A |
| 4 | 23.254 | 60.54% | 23.083 | 60.44% |
| 8 | 16.522 | 71.96% | 16.210 | 72.22% |
| 16 | 12.812 | 78.26% | 12.640 | 78.34% |
| 32 (default) | 12.516 | 78.76% | 12.117 | 79.23% |
| 64 | 11.925 | 79.76% | 11.577 | 80.16% |
| 128 | 11.939 | 79.74% | 11.597 | 80.12% |
There are significant improvements when we increase the batch size to 4, 8 and 16. As the batch size increases, the improvements become smaller and smaller, since the amortized fixed overhead is already low.
Although we're able to achieve slightly better performance with 128, we keep using the default micro batch size offered by the sentence-transformer library (currently 32), as we trust it will provide and maintain a reasonable default.
code_embedding on nomic-embed-text-v1.5 model
In this experiment, we switch all-MiniLM-L6-v2 to nomic-embed-text-v1.5. nomic-embed-text-v1.5 is a larger model, with 0.1B parameters. We tested it:
| end-to-end execution time | runtime in function to batch | ||||
|---|---|---|---|---|---|
| off (s) | on (s) | saving | off (s) | on (s) | saving |
| 137.170 | 131.442 | 4.18% | 136.607 | 130.377 | 4.56% |
The improvement is much smaller compared to the all-MiniLM-L6-v2 model. This is because once the model is large, the fixed overhead is usually much less than the data-size dependent work.
code_embedding on Ollama with all-minilm model
In this experiment, we switched from SentenceTransformerEmbed to EmbedText function, which offers the functionality to use a remote API to embed text. We picked the all-minilm model, which is the same as the default model we used with SentenceTransformerEmbed above.
For ease of comparison, we copy the data from running SentenceTransformerEmbed on the same model from above:
| function for embedding | end-to-end execution time | ||
|---|---|---|---|
| off (s) | on (s) | saving | |
| SentenceTransormerEmbed | 58.931 | 12.516 | 78.76% |
| EmbedText with Ollama | 44.248 | 38.343 | 13.35% |
Here we can see that when there's no batching when calling Ollama, the execution time is better than using SentenceTransformerEmbed without batching. But when there's batching, the savings are quite small, so it's much slower than using SentenceTransformerEmbed.
After digging deeper, we noticed that Ollama computes embeddings for different inputs separately (Ollama code), even if the inputs come from the same request. So batching doesn't save much for Ollama – it still saves a little bit, likely because of the reduced HTTP API calls.
Conclusion
In conclusion, batching significantly enhances processing speed by amortizing fixed overhead across multiple items, enabling more efficient GPU operations, and reducing data transfer.
CocoIndex simplifies this by offering automatic batching for several built-in functions and an easy batching=True decorator for custom functions.
The greatest impact of batching is seen when fixed overhead constitutes a larger portion of the total work, such as with smaller models. It's also most effective when the underlying API or library fully supports batched operations, as demonstrated by the limited gains observed with Ollama.
Support us
⭐ Star CocoIndex on GitHub and share with your community if you find it useful!