AI-Native Data Pipeline - Why We Made It


There’s more need for open data infrastructure for AI, than ever.
Data for humans → to data for AI
Traditionally, people build data frameworks heavily in this space to prepare data for humans. Over the years, we’ve seen massive progress in analytics-focused data infrastructure. Platforms like Spark and Flink fundamentally changed how the world processes and transforms data, at scale.
But with the rise of AI, entirely new needs — and new capabilities — have emerged. A new generation of data transformations is now required to support AI-native workloads.
So, what has changed?
- AI could process new types of data, e.g., by running models to process unstructured data.
- AI could handle high data throughput, and AI agents need rich, high-quality, fresh data to make effective decisions.
- Data preparation for AI must happen dynamically, with flexible schemas and constantly evolving sources.
- Developers need a faster iteration cycle than ever, quickly iterating data transformation heuristics, e.g., dynamically adding new computations and new columns without waiting hours or days.
New capabilities require new infrastructure
The new patterns require capabilities to
- Process data beyond tabular formats - videos, images, PDFs, complex nested data structures - where fan-outs become the norm.
- Process data within data pipelines with AI workloads. Running on your own GPUs, massive calls to remote LLMs expose new challenges for data infrastructure, such as scheduling heterogeneous computing workloads across both CPU and GPU, and also respecting remote rate limits and backpressure.
- Be able to understand what AI is doing with the data - explainable AI.
- Work well with various changes – data changes, schema changes, logic changes.
On top of all this, we need to think about:
- How to do it at scale, with all the things and best practices we’ve learned from building scalable data pipelines in the past.
- How to democratize it, and make it accessible to anyone beyond data engineers.
Why patching existing data pipelines is not enough
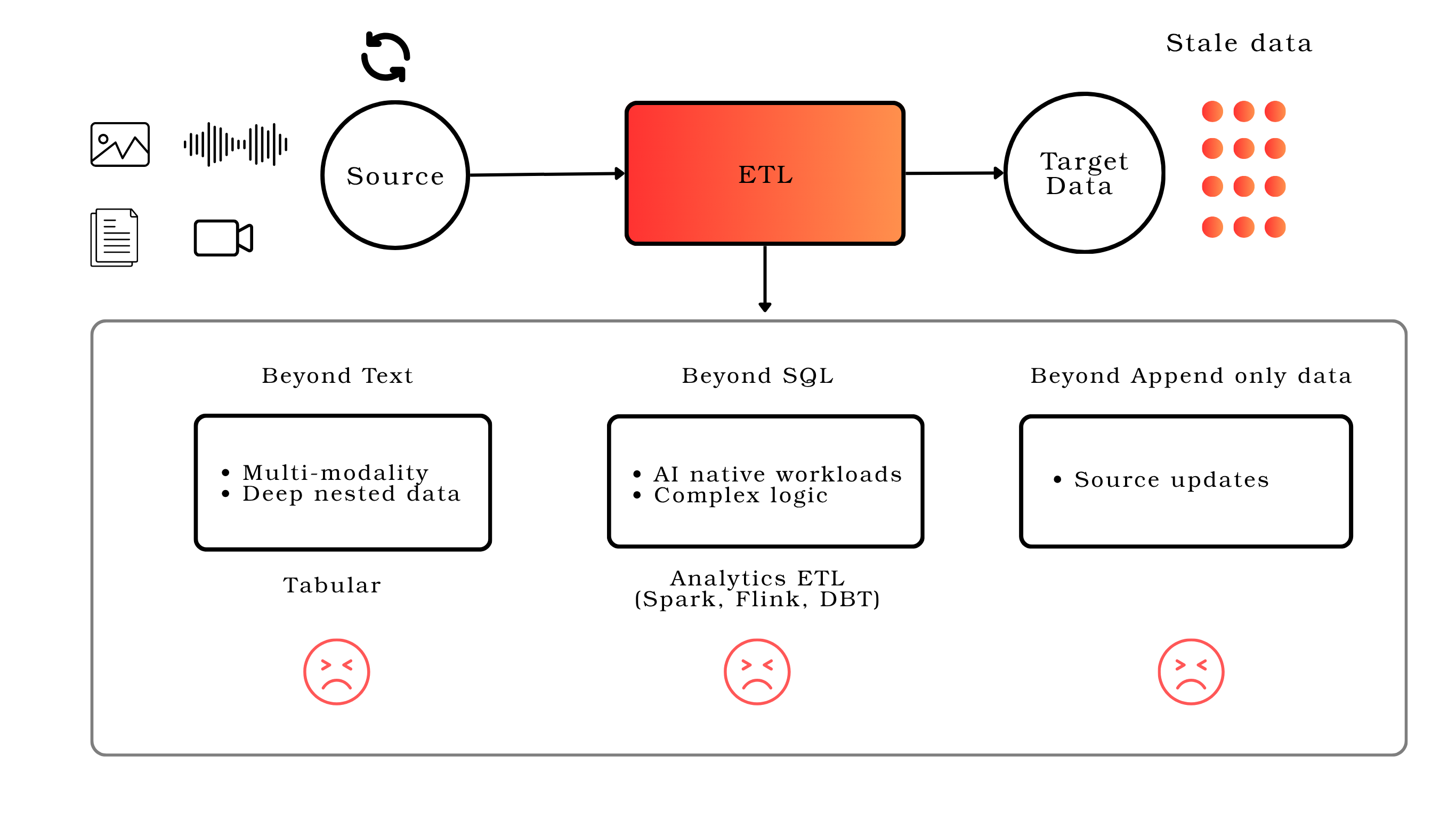 It’s not something that can be fixed with small patches to existing data pipelines. Many traditional frameworks fall short in several key ways:
It’s not something that can be fixed with small patches to existing data pipelines. Many traditional frameworks fall short in several key ways:
- Limited to tabular data models, which is a stretch for data with hierarchical/nested structures.
- Strict requirement for determinism. Many smart operations are not perfectly deterministic, e.g., running LLMs or operations with upgradable dependencies (e.g., an OCR service).
- Require more than a single general-purpose language (like Python), e.g., many use SQL. Users not only face a steeper learning curve, but also need to switch between two languages — e.g., for advanced transformations not supported by SQL, they still need to fall back to Python for UDFs. Ideally, a single language should handle all transformations. Many frameworks force users to switch between two languages, often with overlapping functionality, adding unnecessary complexity.
- Focus on CPU-intensive workloads, and don’t achieve the best throughput when there are GPU and remote API calls.
- Don’t deal with changes. Any schema change, data change, or logic change usually requires rebuilding the output from scratch.
With so many limitations, developers start to handle AI-native data “natively”, with hand-writing Python, and wrap in orchestrations. Begin from a demo, then start to worry about scale, tolerating backend failures, picking up from where it left off when pipelines break, rate limiting and backpressure, building tons of manual integrations when data freshness is needed, making sure stale input data is purged from output, and all of the issues are hard to handle when it runs at scale, and things start to break.
There are so many things to “fix”, and patching existing systems doesn’t work anymore. A new way of thinking about it, from the ground up, is needed.
So what are some of the design choices for CocoIndex?
Declarative data pipeline
Users declare "what", we take care of "how". Once the data flow is declared, you have a production-ready pipeline - infrastructure setup (like creating target tables with the right schema, and schema upgrades), data processing and refresh, fault tolerance, rate limiting and backpressure, batching requests to backends for efficiency, etc.
Persistent computing model
Most traditional data pipelines treat data processing as transient things – they terminate as long as all data have been processed. If anything changes (data or code), you process it again from scratch. We treat pipelines as live things with memory of existing states and only perform necessary reprocessing on data or code change, making the output data continuously reflect the latest input data and code.
This programming model is essential for AI-native data pipelines. It unlocks out-of-the-box incremental processing - the output data to be continuously updated as the input data and code change with minimal computation, and provides the ability to trace the lineage of the data for explainable AI.
Clear data ownership with fine-granular lineage
Output of pipelines is data derived from source data via certain transformation logic, so each row of data created by the pipeline can be traced back to the specific rows or files from the data source, plus certain pieces of logic. This is essential for refreshing the output on data or logic updates, and also makes the output data explainable.
Strong type safety
The schema of data created by each processing step is determined at pipeline declaration time with validation – before running on specific items of data. This catches issues earlier and enables automatic inference of the output data schema for automatic target infrastructure setup.
Open ecosystem
An open system that allows developers to dock their choice of ecosystem as building blocks. AI agents should be tailored to specific domains and there will be different technology choices from source to storage to domain-specific processing. It has to be an open data stack that is easily customizable and brings in the user's own building blocks.
With the rapid growth of the ecosystem - new sources, targets, data formats, transformation building blocks, etc., the system shouldn’t be bound to any specific one. Instead of waiting for specific connectors to be built, anyone should be able to use it to create their own data pipelines — assembling flexible building blocks that can work directly with internal APIs or external systems.
It needs to stay open
We believe this AI-native data stack must be open.
The space is moving too fast — closed systems can’t keep up. Open infrastructure enables:
- Transparent design and rapid iteration
- Building a community, collaboratively solve it for the future
- Composability with other open ecosystems (agents, analytics, compute, real-time, orchestration frameworks)
- No lock-in for developers or companies experimenting at the frontier
It should be something everyone can contribute to, learn from, and build upon.
Build with the ecosystem
CocoIndex fits seamlessly into the broader data ecosystem, working well with orchestration frameworks, agentic systems, and analytical pipelines. As an open, AI-native data infrastructure, it aims to drive the rise of the next generation of applied AI.
The road ahead
We are just getting started. AI is notoriously bad at writing data infrastructure code. The abstractions and data feedback loop, and programming model from CocoIndex is designed delibrately thought from ground up, that is tailored for AI co-pilot.
This unlocks the full potential of CocoIndex on the path of a self-driving data pipeline, with data auditable and controllable along the way.
🚀 To the future of build!
Support us and join the journey
Thank you, everyone, for your support and contributions to CocoIndex. Thank you so much for your suggestions, feedback, stars and for sharing the love for CocoIndex.
We are especially grateful for our beloved community and users. Your passion, continuous feedback, and collaboration as we got started have been invaluable, helping us iterate and improve the project every step of the way.
Looking forward to building the future of data for AI together!
⭐ Star CocoIndex on GitHub here to help us grow!
