CocoIndex Changelog 0.2.21 - 0.3.10


CocoIndex is moving at insane speed! 🚀 This release is packed with some of our biggest upgrades yet — from automatic batching, to robust async execution, schema and type-system upgrades, and the long-awaited launch of Custom Sources.
CocoIndex is rapidly becoming the best framework for persistent-state–driven data processing, where it continuously transform and update the target data (e.g. AI context, feature stores, knowledge graphs and beyond) upon source change with zero manual orchestration.
We’re incredibly excited to keep building in the open with our community. Together, we’re redefining how AI systems maintain, evolve, and reason over long-lived state. Onward! 🎉
Core capability
Batching support for CocoIndex functions
CocoIndex now supports automatic batching for all CocoIndex functions. When embedding the CocoIndex codebase with sentence-transformers/all-MiniLM-L6-v2, batching delivered ~5× higher throughput (≈80% lower runtime) compared to processing items one-by-one.
Why it’s fast
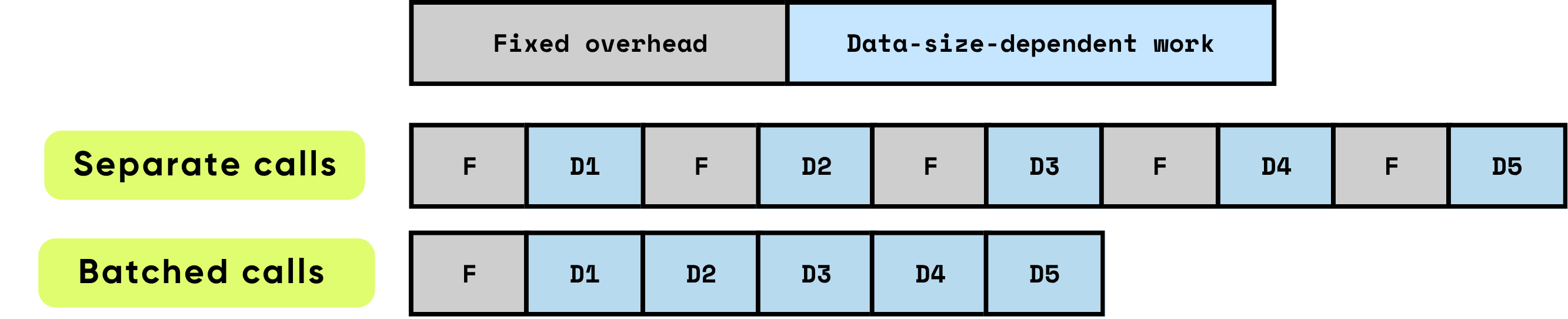
Each call normally pays:
- Fixed overhead (GPU kernel launches, Python↔C transitions, memory allocator work)
- Data-dependent compute (FLOPs, bytes moved, tokens processed)
Batching amortizes the fixed cost and lets GPUs run larger, denser GEMMs with fewer data transfers — dramatically increasing utilization.
What’s new
CocoIndex introduces adaptive, knob-free batching:
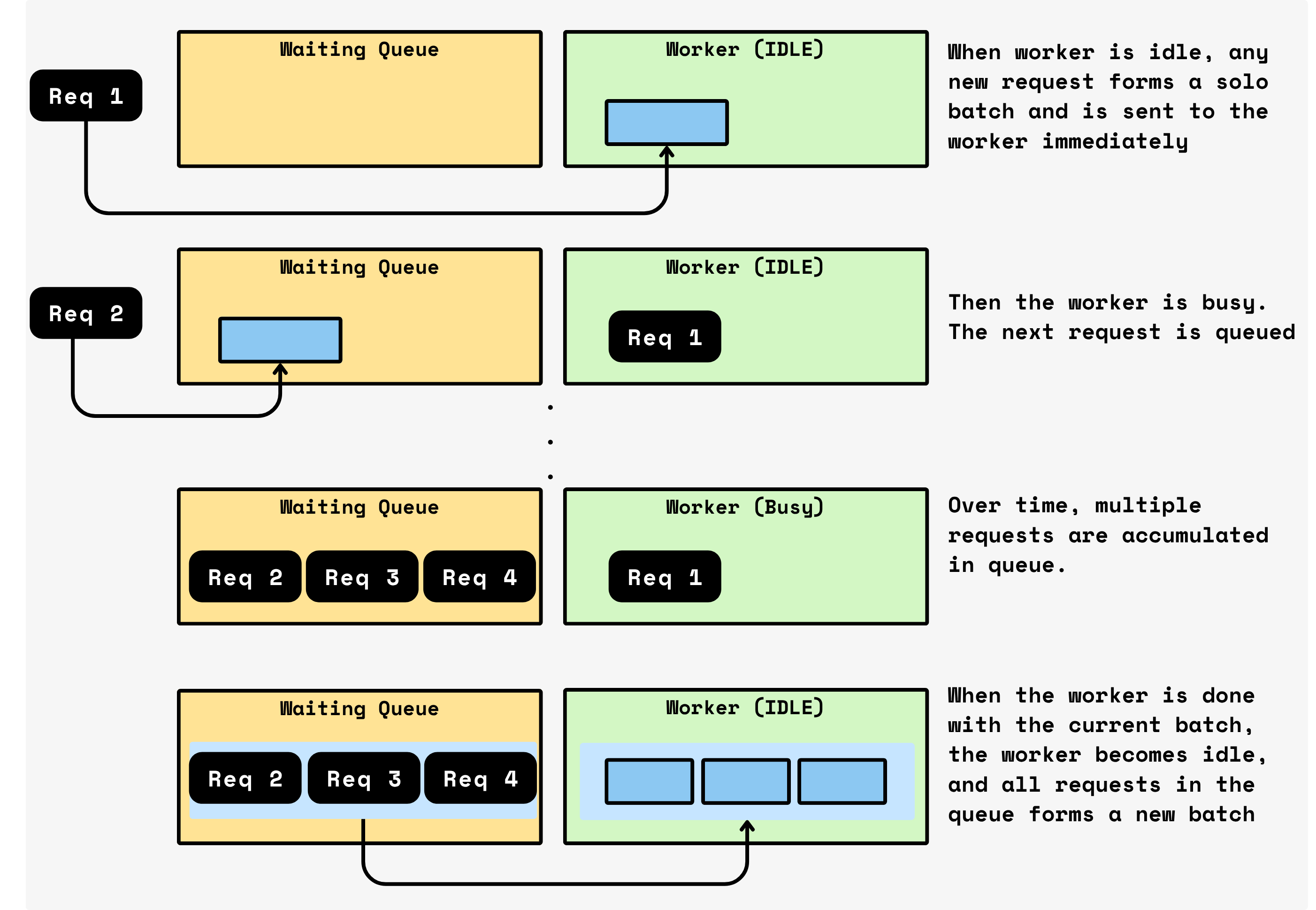
- Requests queue while the GPU is busy
- As soon as a batch completes, all queued requests are flushed as the next batch
- No timers, no target batch sizes, no tuning — batching automatically adapts to workload traffic
Batching significantly enhances processing speed by amortizing fixed overhead across multiple items, enabling more efficient GPU operations, and reducing data transfer.
CocoIndex simplifies this by offering automatic batching for several built-in functions and an easy batching=True parameter for custom function.
You can read more about batching and the benchmark in the blog post.
Changes: #1229, #1230, #1232, #1233, #1236, #1238, #1261
Custom source support
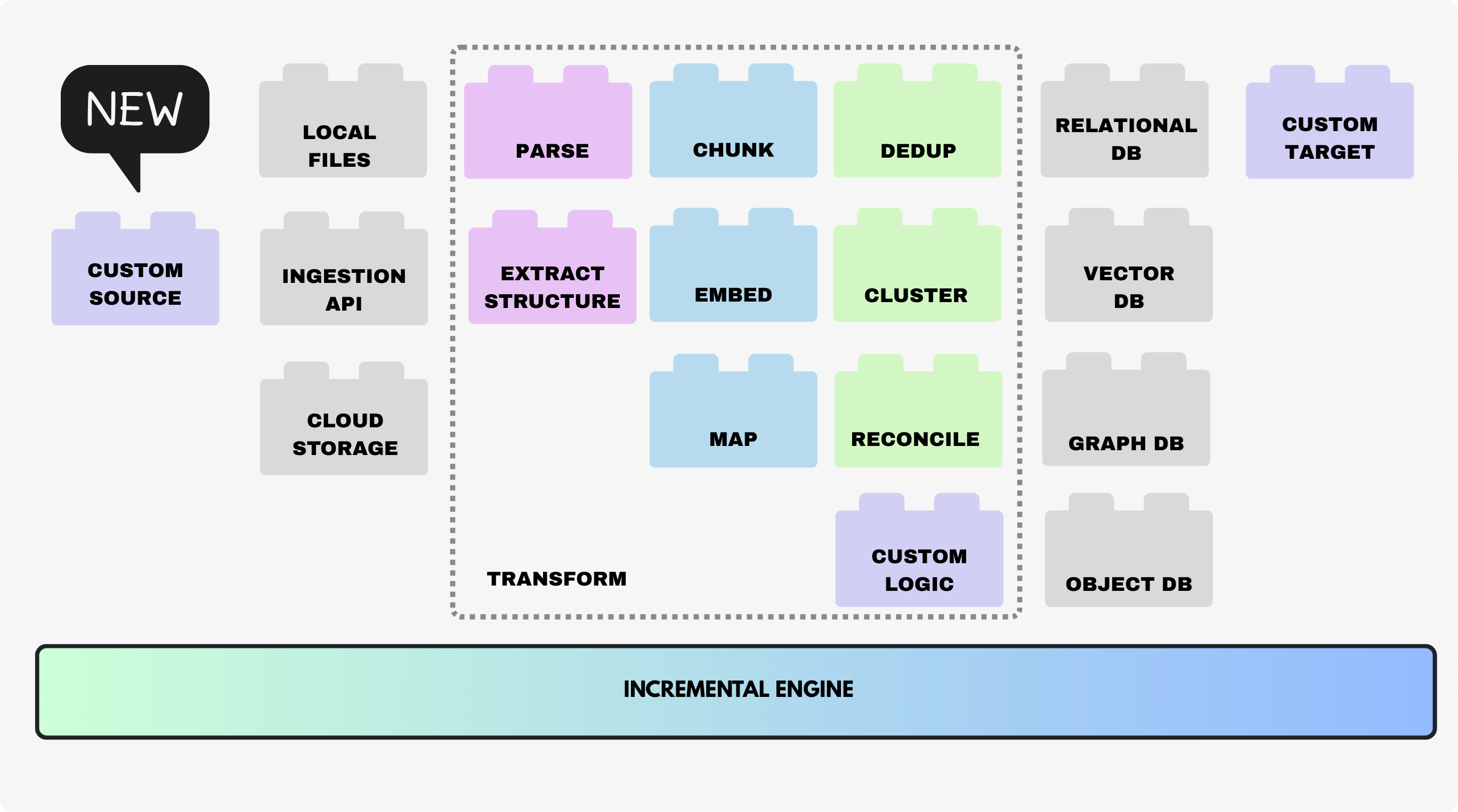
We're thrilled to introduce Custom Sources in CocoIndex — a feature that lets you pull data from any system: APIs, databases, file systems, cloud storage, or other services. CocoIndex now ingests data incrementally, tracks changes efficiently, and integrates seamlessly into your workflows.
With Custom Sources, you're no longer limited by prebuilt connectors or targets. Use CocoIndex for anything, leveraging its robust incremental computing to continuously build fresh knowledge for AI.
A custom source defines how CocoIndex reads data from an external system.
Custom sources are defined by two components:
- A source spec that configures the behavior and connection parameters for the source.
class CustomSource(cocoindex.op.SourceSpec):
"""
Custom source for my external system.
"""
param1: str
param2: int | None = None
- A source connector that handles the actual data reading operations. It provides the following required methods:
create(): Create a connector instance from the source spec.list(): List all available data items. Return keys.get_value(): Get the full content for a specific data item by given key.
@cocoindex.op.source_connector(
spec_cls=CustomSource,
key_type=DataKeyType,
value_type=DataValueType
)
class CustomSourceConnector:
@staticmethod
async def create(spec: CustomSource) -> "CustomSourceConnector":
"""Initialize connection, authenticate, and return connector instance."""
...
async def list(self, options: SourceReadOptions) -> AsyncIterator[PartialSourceRow[DataKeyType, DataValueType]]:
"""List available data items with optional metadata (ordinal, content)."""
...
async def get_value(self, key: DataKeyType, options: SourceReadOptions) -> PartialSourceRowData[DataValueType]:
"""Retrieve full content for a specific data item."""
...
def provides_ordinal(self) -> bool:
"""Optional: Return True if the source provides timestamps or version numbers."""
return False
Checkout the article on Bring your own data: Index any data with Custom Sources for more details. Get started and read the documentation now.
Changes: #1195, #1197, #1198, #1199, #1201
Execution robustness / debugability enhancement
Robust async runtime, better error propagation and observability for HTTP calls, function‑level timeouts and contextual execution in CocoIndex.
Runtime and async safety
- The runtime now detects misuse of the sync API from async code and guards it explicitly. Sync entrypoints now safely handle calls from different event loops, avoiding deadlocks.
- Async cancellation is now propagated correctly through CocoIndex's async contexts, so task cancellations (for example, from higher‑level orchestration or timeouts) reliably unwind work instead of silently hanging.
- Async custom functions are fully supported and wired into the runtime so user‑defined async operations behave like first‑class citizens, including proper scheduling and error handling.
HTTP utility improvements
- A new
http::request()utility centralizes HTTP calls, providing:- Better, more actionable error messages for network and protocol failures.
- Built‑in retry behavior so transient errors are handled consistently across integrations.
- This utility is intended as the recommended path for HTTP interactions in sources, functions and sinks, improving both debuggability and resilience.
Changes: #1235
Function timeout support
- User‑configured operations (sources, functions, etc.) now support a function timeout to prevent unbounded or long‑running executions.
- The timeout is fully wired through the batching executor so batched executions respect per‑function limits instead of letting a single slow item stall the entire batch.
- Timeouts integrate with the new cancellation propagation so timed‑out work is properly cancelled and cleaned up, rather than left in an indeterminate state.
Clear context in error messages
CocoIndex now attaches clear context information (like source, function and target names) with error messages.
Changes: #1275
Schema & type system
This set of changes improves how CocoIndex handles JSON Schemas, type metadata, and schema merging, with a focus on configurability, correctness, and compatibility across tools and providers.
Collector schema alignment
- Collectors now automatically merge and align schemas when
collect()is called multiple times with different shapes, producing a unified schema instead of requiring manual pre‑alignment. - The new collector implementation has been simplified in a follow‑up change while preserving the automatic merge‑and‑align behavior for easier maintenance.
Improved schema support
additionalPropertiesis now configurable viasupports_additional_propertiesonToJsonSchemaOptions, so providers that support it (OpenAI, Anthropic, Bedrock, Ollama, etc.) still get strict schemas while Gemini (AI Studio, Vertex) receives schemas without this keyword, removing the previous Gemini‑specific strip workaround.- Forward‑referenced field types are now resolved before export, improving compatibility with BAML and other tooling that expects fully concrete types, and type descriptions are correctly encoded so documentation survives serialization.
- A previously incorrect assertion condition in the type/schema logic has been fixed to avoid spurious failures in valid configurations.
Changes: #1254, #1272, #1294, #1312
More accurate logic change detection
CocoIndex now detects logic changes with much finer granularity, so incremental runs only reprocess data that is truly affected.
- New per‑source
SourceLogicFingerprintand field‑levelFieldDefFingerprinttrack exactly which sources and operations each export/field depends on. - Execution and indexing now use these fingerprints (including target schema IDs) to avoid unnecessary recomputation while still catching real logic changes.
Changes: #1292
Building blocks
Builtin sources
File size management across sources
CocoIndex’s built-in file-based sources now support consistent file size limits to protect pipelines from unexpectedly large inputs.
max_file_sizeis now supported on Azure Blob, Amazon S3, LocalFile, and Google Drive sources.- Files larger than the configured
max_file_sizeare treated as non-existent in bothlist()andget_value()calls, letting you cap resource usage and skip oversized blobs uniformly across all these sources.
Changes: #1257, #1259, #1260, #1269
GoogleDrive source enhancements
GoogleDrive now supports included_patterns and excluded_patterns, using glob-style patterns to decide exactly which Drive files to index. This makes it easy to focus on specific file types or paths (for example, only *.md docs) while excluding noisy locations like temp folders or logs.
Changes: #1263
S3 configuration enhancements
Amazon S3 sources gain a force_path_style configuration flag, improving compatibility with S3-compatible object stores and strict networking setups that require path-style URLs instead of virtual-hosted–style.
Changes: #1290
S3 event notifications via Redis queue
CocoIndex can now consume S3 event notifications via a Redis queue, enabling push-based, near–real-time updates from S3 buckets into your indexing flows. This reduces the need for frequent full scans or tight polling loops while still keeping downstream indexes fresh.
Changes: #1189
Postgres source stability
- The Postgres source’s change‑listening connection is now more stable, reducing disconnects and flaky behavior when capturing updates via
LISTEN/NOTIFY. - This makes long‑running live update pipelines against Postgres more resilient, especially under network hiccups or database restarts.
Changes: #1264
UTF-16/UTF-32 file support
- File decoding now auto‑detects BOMs and supports UTF‑16 and UTF‑32 in addition to UTF‑8, so mixed‑encoding corpora can be indexed without pre‑normalizing everything.
- The internal
bytes_to_string()helper was optimized to return aCowinstead of always allocating, avoiding unnecessary copies when data is already valid UTF‑8.
Builtin functions
Performance optimization for SentenceTransformerEmbed
SentenceTransformerEmbed now sorts inputs by length before batching, which reduces padding, improves GPU utilization, and lowers per-batch compute cost for sentence-transformer models. This change is transparent to users but can significantly improve throughput for large embedding workloads.
Changes: #1245
Ollama embedding support
The Ollama embedding integration now correctly parses the nested embeddings array returned by the /api/embed endpoint. This fixes shape/format mismatches so multi-input embedding calls against Ollama work reliably in CocoIndex.
Changes: #1227
Operations & monitoring
CocoIndex now exposes basic server health checks and clearer runtime progress reporting.
HTTP server & health checks
- A new
/healthzendpoint on the CocoIndex HTTP server returns a lightweight JSON payload with status and version, making it easy to plug the server into Kubernetes, load balancers, and external monitoring. - Documentation has been added for the HTTP server, including how to start it via CLI or Python and how to wire it up with CocoInsight or custom frontends.
Statistics & progress reporting
- Processing commands now report elapsed time, so you can quickly see how long an update or run took.
- Progress reporting has been reworked: there is a consolidated, clearer progress bar, continuous stats updates during batch operations, and better handling of errors so counts and statuses remain accurate throughout the run.
Changes: #1204, #1223, #1231, #1240, #1247
CLI simplification
CocoIndex simplifies the CLI around flow setup by making setup the default and deprecating the extra flag.
- The
--setupflag oncocoindex updateandcocoindex serveris now enabled by default and marked as deprecated, since these commands will automatically perform any required setup before running. - When
--setupis used explicitly, the CLI shows a deprecation warning, and docs have been updated to remove references to manually passing this flag in common workflows.
Claude skills integration
CocoIndex now ships a dedicated Claude Code skill so developers can work with CocoIndex flows directly from their IDE-like Claude environment.
- A CocoIndex Claude skill has been introduced and moved into its own
cocoindex-clauderepository, giving Claude richer, structured knowledge of CocoIndex concepts, data types, and workflows. - Documentation was added showing how to install and enable the CocoIndex skill in Claude Code, so Claude can help scaffold flows, edit pipelines, and navigate CocoIndex projects more effectively.
New tutorials
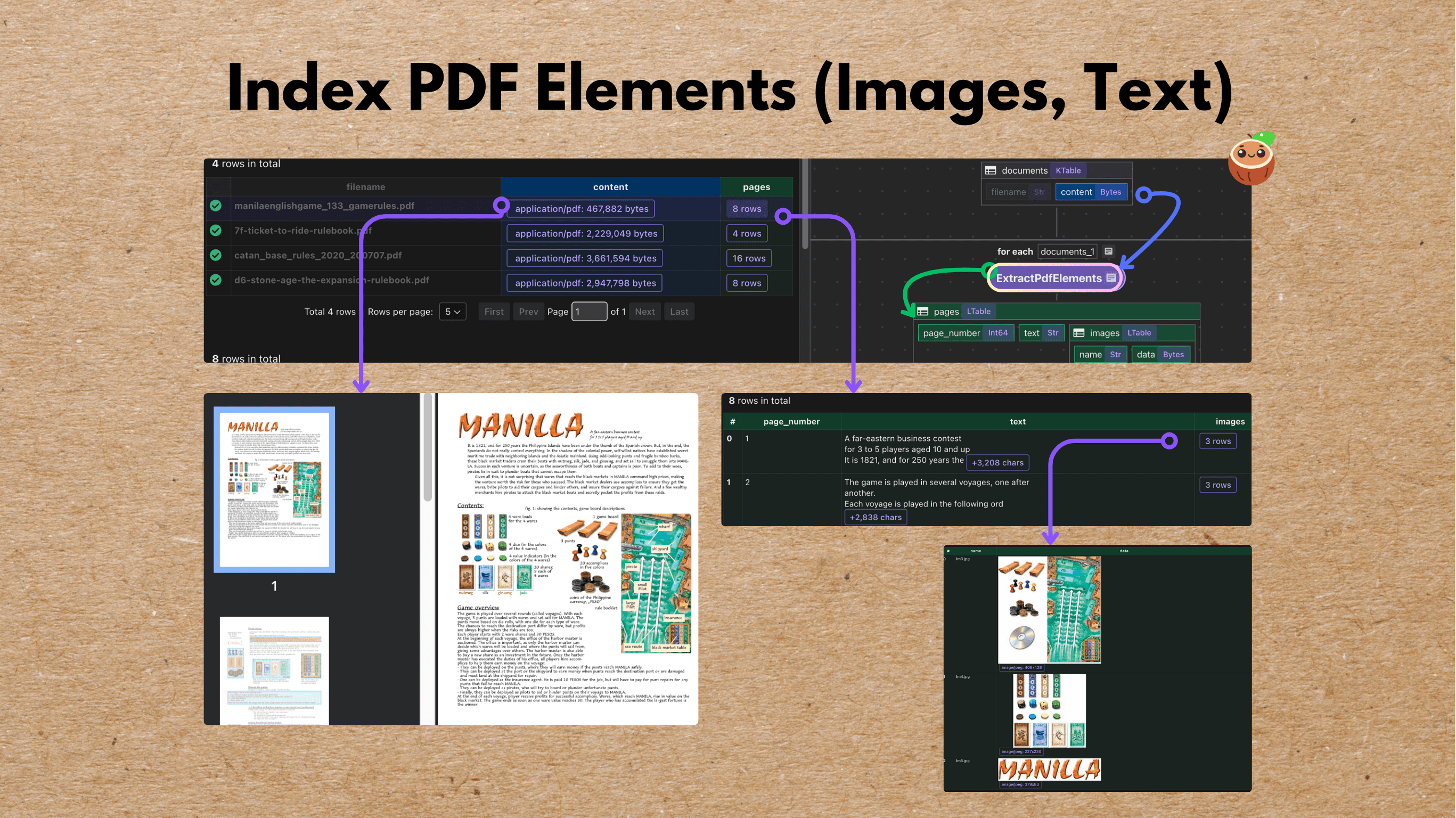
Index PDF elements
PDFs are rich with both text and visual content — from descriptive paragraphs to illustrations and tables. This example builds an end-to-end flow that parses, embeds, and indexes both, with full traceability to the original page.
Checkout the blog for more details.
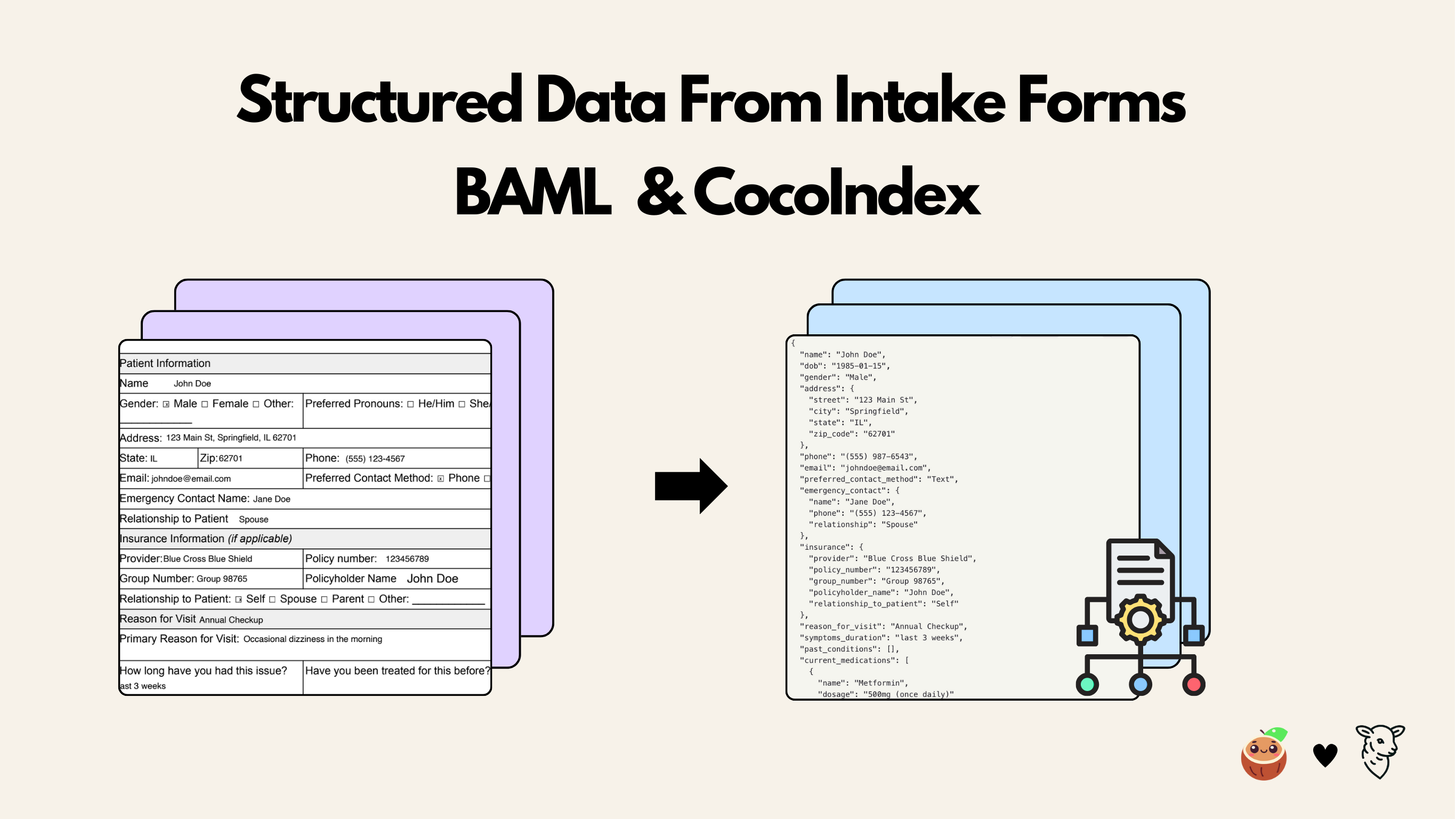
Extracting intake forms with BAML and CocoIndex
This tutorial shows how to use BAML together with CocoIndex to build a data pipeline that extracts structured patient information from PDF intake forms. The BAML definitions describe the desired output schema and prompt logic, while CocoIndex orchestrates file input, transformation, and incremental indexing.
Checkout the blog for more details.
Special edition
CocoIndex recently hit 3K GitHub stars and became the #1 trending Rust repo globally!
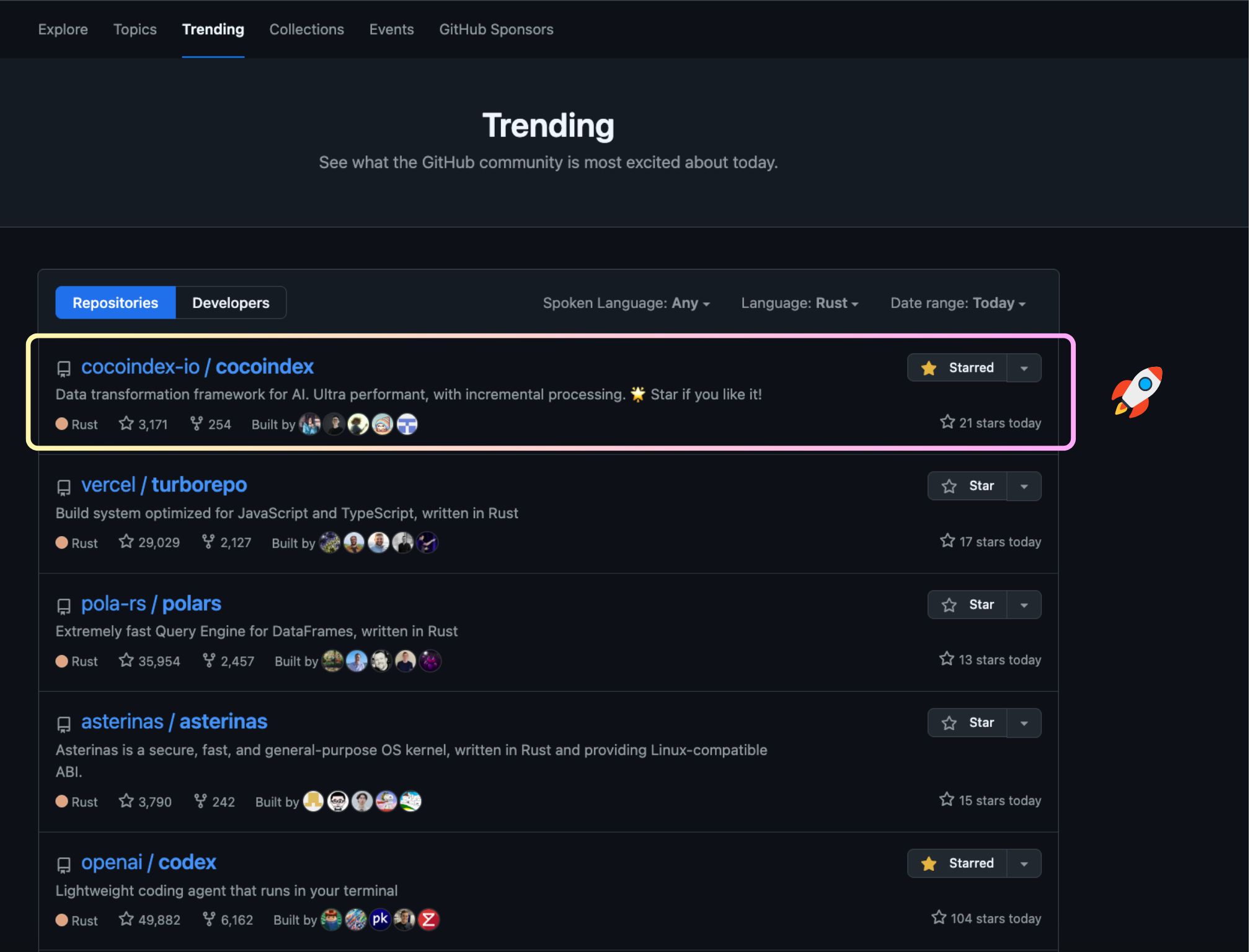
🎉 We shared an article reflecting on why we built CocoIndex, the journey so far, and some fresh thoughts:

For a look back when we reached 1K stars, see:
We're just getting started and can't wait to see what comes next on our way to 5K stars!
Thanks to the community
Welcome new contributors to the CocoIndex community! We are so excited to have you!
@Haleshot

@Gohlub

@dcbark01

@prabhath004

Thanks @prabhath004 for adding max_file_size support to the AzureBlob source in #1259, LocalFile source in #1260, and AmazonS3 source in #1257, making large‑file handling safer and more configurable.
@xuzijan

@AdwitaSingh1711

Thanks @AdwitaSingh1711 for adding function timeout support in #1241, preventing long‑running functions from blocking pipelines.
@skalwaghe-56

Thanks @skalwaghe-56 for teaching the collector to automatically merge and align multiple collect() calls with different schemas in #1153, simplifying complex aggregation flows.
@ansu86d

@samojavo

@CAPsMANyo

Thanks @CAPsMANyo for correctly parsing nested embeddings arrays from the Ollama /api/embed endpoint in #1227, ensuring robust embedding ingestion.
@belloibrahv

Thanks @belloibrahv for adding Redis queue support for S3 event notifications in #1189 and improving CLI --help/Markdown docstring formatting in #1210, making event‑driven updates and CLI usage smoother.
@GooglyBlox

Thanks @GooglyBlox for deprecating the setup flag in #1212, simplifying the CLI surface and guiding users toward the preferred setup flow.