Turn Podcasts into a Knowledge Graph with LLM and CocoIndex


Podcasts are one of the richest sources of expert knowledge on the internet. A single Lex Fridman or Dwarkesh Patel episode can contain dozens of substantive claims about people, technologies, and organizations — but it's all locked inside hours of audio. You can't query any of it. You can't cross-reference what two different guests said about the same topic.
In this post, we'll build a CocoIndex pipeline that turns YouTube podcast episodes into a queryable knowledge graph. The pipeline downloads audio, transcribes with speaker diarization, uses an LLM to extract structured statements and entities, resolves duplicates across episodes, and stores everything in SurrealDB as a graph.
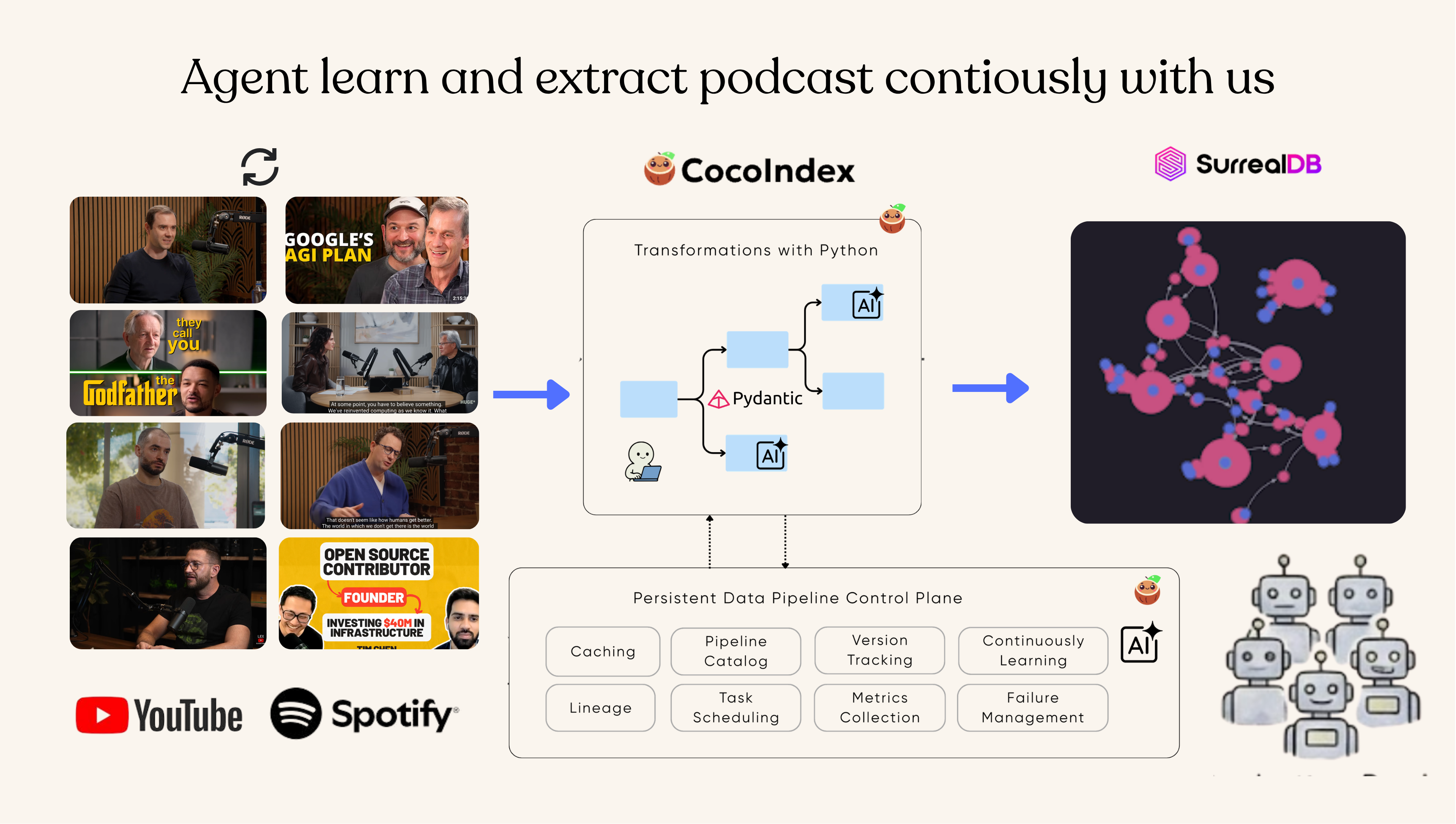
We use CocoIndex to build the pipeline. CocoIndex is a data indexing framework for building incremental data transformation pipelines — it tracks what's been processed, so re-running the pipeline only processes new or changed episodes. It also made it simple to take out any unwanted podcast content that gets merged into the knowledge graph.
The full source code is available at CocoIndex Examples — podcast_to_knowledge.
What We're Building
Here's the knowledge graph schema — five node types connected by four relationship types:

A session is one podcast episode. A statement is a thematic claim extracted from the conversation — e.g., "Scaling laws suggest that larger models will continue to improve." Each statement is linked to who said it and what entities it mentions.
Person, tech, and org are named entities. The tricky part is that the same entity can appear under different names across episodes ("GPT-4", "GPT4", "OpenAI's GPT-4"). We handle this with entity resolution — more on that later.
Pipeline Overview
The pipeline runs in three phases:

Phase 1 processes each episode independently: download audio, transcribe, and use an LLM to extract metadata, speakers, and statements. Sessions and statements are written to the database immediately since they don't need cross-episode deduplication.
Phase 2 collects all raw entity names (persons, techs, orgs) from every episode and deduplicates them using embedding similarity + LLM confirmation.
Phase 3 writes the deduplicated entities and all relationships to the database.

Phase 1: Per-Session Processing

Each session goes through a multi-step pipeline, starting from a YouTube URL.
Fetch Transcript
We download the audio with yt-dlp and transcribe it with AssemblyAI, which gives us speaker-diarized utterances (labeled "Speaker A", "Speaker B", etc.) along with YouTube metadata (channel name, title, description, upload date):
@coco.fn(memo=True)
async def fetch_transcript(youtube_id: str) -> SessionTranscript:
"""Download audio via yt-dlp, transcribe with speaker diarization via AssemblyAI."""
url = f"https://www.youtube.com/watch?v={youtube_id}"
with tempfile.TemporaryDirectory() as tmpdir:
# 1. Download audio via yt-dlp, convert to mp3
audio_path = os.path.join(tmpdir, "audio.mp3")
ydl_opts = {"format": "bestaudio/best", "outtmpl": audio_path, "quiet": True,
"postprocessors": [{"key": "FFmpegExtractAudio",
"preferredcodec": "mp3"}]}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info = ydl.extract_info(url, download=True)
# 2. Transcribe with AssemblyAI (speaker diarization)
config = aai.TranscriptionConfig(speaker_labels=True)
transcript = aai.Transcriber().transcribe(audio_path, config)
# 3. Convert diarized output to structured utterances
utterances = [Utterance(speaker=u.speaker, text=u.text)
for u in transcript.utterances]
return SessionTranscript(
utterances=utterances,
yt_channel=info["channel"],
yt_title=info["title"],
yt_description=info.get("description"),
yt_upload_date=info.get("upload_date"),
)
The @coco.fn(memo=True) decorator is a CocoIndex feature that memoizes the function — if you've already fetched and transcribed a video, re-running the pipeline skips it entirely. This is essential when you're iterating on the downstream extraction logic and don't want to re-download hours of audio every time.
Two-Step LLM Extraction

Here's where it gets interesting. We can't extract everything in a single LLM call because of a bootstrapping problem: to extract good statements, the LLM needs to know who the speakers are (so it can attribute statements correctly). But the raw transcript only has generic labels like "Speaker A" — we need to figure out who's who first.
So we split extraction into two passes. Both steps use a shared format_transcript() function that replaces raw diarization labels with names — Step 1 passes an empty map (no names known yet, so all speakers show as "Speaker A", "Speaker B"), and Step 2 passes the mapping from Step 1.
Step 1: Identify speakers and extract metadata. We format the transcript with generic labels and give the LLM the YouTube metadata (channel name, title, description) as context. The LLM returns who each speaker is, plus session metadata:
@coco.fn(memo=True)
async def extract_metadata(
reformatted_transcript: str, transcript: SessionTranscript
) -> SessionMetadata:
client = instructor.from_litellm(litellm.acompletion, mode=instructor.Mode.JSON)
return await client.chat.completions.create(
model=coco.use_context(LLM_MODEL),
response_model=SessionMetadata,
messages=[
{"role": "system", "content": METADATA_PROMPT},
{"role": "user", "content":
f"YouTube channel: {transcript.yt_channel}\n"
f"Video title: {transcript.yt_title}\n"
f"Description: {transcript.yt_description or 'N/A'}\n\n"
f"Transcript:\n{reformatted_transcript}"},
],
)
The LLM output is a Pydantic model, enforced by instructor:
class SpeakerIdentification(pydantic.BaseModel):
label: str # e.g. "A", "B"
name: str # e.g. "Lex Fridman" — unidentifiable speakers are excluded
class SessionMetadata(pydantic.BaseModel):
name: str
description: str | None
date: str | None
speakers: list[SpeakerIdentification]
Step 2: Extract statements with real names. Now that we know "Speaker A" is "Lex Fridman", we reformat the transcript with real names and ask the LLM to extract thematic statements:
# Reformat: replace "Speaker A" with "Lex Fridman", etc.
speaker_map = {s.label: s.name for s in metadata.speakers}
step2_text = format_transcript(transcript.utterances, speaker_map)
# Extract statements from the named transcript
stmt_extraction = await extract_statements(step2_text)
Each extracted statement includes the speakers who made it and the entities it mentions:
class RawStatement(pydantic.BaseModel):
statement: str # "Scaling laws suggest larger models will improve"
speakers: list[str] # ["Lex Fridman"]
mentioned_person: list[str] # ["Ilya Sutskever"]
mentioned_tech: list[str] # ["Large language model"]
mentioned_org: list[str] # ["OpenAI"]
All entity names must be self-contained. The extraction prompt explicitly instructs the LLM: "Never use pronouns, speaker labels, or contextual references. Every name must be a clear, unambiguous identifier that stands on its own." This matters because statements from different episodes will later be cross-referenced — an entity name like "he" or "the host" would be meaningless outside its original transcript.
Declaring Results with CocoIndex
After extraction, we declare the session and its statements as records in SurrealDB. CocoIndex uses a declarative model — you describe what the target state should look like, and the framework handles inserts, updates, and deletes.
IDs are generated using CocoIndex's IdGenerator, which produces stable IDs — the same inputs always yield the same ID, so re-running the pipeline doesn't create duplicates. Calling next_id() without arguments generates a sequential ID; calling next_id(content) incorporates the content into the ID so it remains stable even if the order of statements changes:
id_gen = IdGenerator(youtube_id)
session_id = await id_gen.next_id()
session_table.declare_record(row=Session(
id=session_id,
youtube_id=youtube_id,
name=metadata.name,
transcript=step2_text,
# ... description, date
))
for stmt in stmt_extraction.statements:
stmt_id = await id_gen.next_id(stmt.statement)
statement_table.declare_record(row=Statement(id=stmt_id, statement=stmt.statement))
session_statement_rel.declare_relation(from_id=session_id, to_id=stmt_id)
Mounted Components
Each session is processed as an independent mounted component via coco.use_mount(). A mounted component is a self-contained unit of work that CocoIndex tracks independently — each YouTube video ID gets its own component, so adding a new episode only processes that episode:
for youtube_id in video_ids:
raw = await coco.use_mount(
coco.component_subpath("session", youtube_id),
process_session, youtube_id,
session_table, statement_table, session_statement_rel,
)
all_session_raw.append(raw)
Each process_session call returns a SessionRawEntities — the raw entity names and statement linkages that Phase 2 and 3 will need:
@dataclass
class SessionRawEntities:
session_id: int
raw_entities: dict[str, list[str]] # e.g. {"person": ["Lex Fridman", ...]}
statements: list[IdentifiedStatement] # statements with generated IDs
Sessions and statements are already written to SurrealDB at this point. The raw entities are carried forward for cross-session deduplication.
Phase 2: Entity Resolution

After processing all sessions, we have a pile of raw entity names from every episode. The same entity often appears under different names: "GPT-4" vs "GPT4", "Google" vs "Google LLC", "Sam Altman" vs "Samuel Altman". We need to collapse these into canonical names.
The approach uses embedding similarity to find candidates, then an LLM to confirm:
- Compute an embedding for each entity name (using a small sentence transformer model).
- For each entity, search a FAISS index for the most similar names already processed.
- If any are close enough (cosine distance < 0.3, i.e. similarity > 0.7), ask an LLM: "Is
GPT4the same thing asGPT-4?" - The LLM picks the canonical name. Build a deduplication map.
async def resolve_entities(all_raw_entities: set[str]) -> dict[str, str | None]:
index = faiss.IndexFlatIP(dim)
for entity in entity_list:
vec = embeddings[entity].reshape(1, -1).copy()
faiss.normalize_L2(vec)
# Find similar entities already in the index
candidates = []
if index.ntotal > 0:
sims, idxs = index.search(vec, k=min(TOP_N, index.ntotal))
for sim, idx in zip(sims[0], idxs[0]):
if sim >= 1.0 - MAX_DISTANCE and idx >= 0:
canonical = resolve_canonical(index_names[idx], dedup)
if canonical != entity:
candidates.append(canonical)
# Deduplicate candidate list
unique_candidates = list(dict.fromkeys(candidates))
if unique_candidates:
resolution = await resolve_entity_pair(entity, unique_candidates)
# Update dedup map based on LLM decision
...
index.add(vec)
index_names.append(entity)
return dedup # e.g. {"Apple Inc.": None, "Apple": "Apple Inc.", "AAPL": "Apple Inc."}
The embedding step is fast and cheap — it filters out the vast majority of entity pairs that are obviously different. The LLM call only happens for the small set of near-matches, keeping the cost down. We use a smaller, cheaper model for these resolution calls since the task is simple (configurable via the RESOLUTION_LLM_MODEL environment variable).
Entity resolution runs independently per entity type (person, tech, org), so CocoIndex processes them concurrently:
entity_dedup = dict(zip(
[cfg.name for cfg in ENTITY_TYPES],
await asyncio.gather(*(
coco.use_mount(
coco.component_subpath("resolve", cfg.name),
resolve_entities,
collect_all_raw(all_session_raw, cfg.name),
)
for cfg in ENTITY_TYPES
)),
))
Phase 3: Knowledge Base Creation
With the deduplication maps ready, we write the final knowledge graph. Canonical entities become nodes, and all relationships use the resolved canonical names. A helper resolve_canonical(name, dedup) chases the dedup chain to find the root — e.g., resolve_canonical("AAPL", dedup) → "Apple Inc.":
@coco.fn
async def create_knowledge_base(all_session_raw, entity_dedup, ...):
# Declare canonical entity nodes (name IS the id)
for cfg in ENTITY_TYPES:
dedup = entity_dedup[cfg.name]
table = entity_tables[cfg.name]
for name, upstream in dedup.items():
if upstream is None: # this name is canonical
table.declare_record(row=Entity(id=name, name=name))
# Declare relationships using canonical names
person_dedup = entity_dedup["person"]
for session_raw in all_session_raw:
for person_name in session_raw.raw_entities.get("person", []):
canonical = resolve_canonical(person_name, person_dedup)
person_session_rel.declare_relation(from_id=canonical, to_id=session_raw.session_id)
for stmt in session_raw.statements:
# person_statement: who made the statement
for speaker in stmt.raw.speakers:
canonical = resolve_canonical(speaker, person_dedup)
person_statement_rel.declare_relation(from_id=canonical, to_id=stmt.id)
# statement_mentions: what the statement is about (polymorphic)
for cfg in ENTITY_TYPES:
dedup = entity_dedup[cfg.name]
for entity_name in getattr(stmt.raw, f"mentioned_{cfg.name}"):
canonical = resolve_canonical(entity_name, dedup)
statement_mentions_rel.declare_relation(
from_id=stmt.id, to_id=canonical,
to_table=entity_tables[cfg.name]) # polymorphic target
The statement_mentions relationship is polymorphic — the target can be a person, tech, or org table. The to_table parameter tells CocoIndex which table the target ID belongs to.
Incremental Updates
A pipeline like this isn't a one-shot job. You'll add new podcast episodes over time, and you'll want to evolve the schema — maybe adding Product, Event, or Place as new entity types, or refining the extraction prompts. CocoIndex's memoization and component model make both scenarios efficient.
Adding new episodes
When you add a new YouTube URL and re-run the pipeline, only the new episode is processed. Existing episodes are untouched:
- Fetch transcript: Skipped for existing episodes (
memo=Trueonfetch_transcript). - LLM extraction (Step 1 + Step 2): Skipped for existing episodes (both are memoized).
- Entity resolution: Re-runs to incorporate new entity names, but
compute_entity_embeddingandresolve_entity_pairare memoized — existing entities' embeddings and resolution decisions are reused. Only the new names trigger fresh LLM calls. - Knowledge base: CocoIndex's declarative targets handle the diff — new records are inserted, removed episodes are cleaned up.
Removing an episode works the same way — its mounted component is gone, so CocoIndex deletes its session, statements, and relationships from SurrealDB.
Evolving the schema
Say you want to add a new entity type, like Product. You'd add it to ENTITY_TYPES, update the extraction prompt, and re-run. Here's what happens:
| Pipeline step | What happens | Why |
|---|---|---|
| Fetch transcript | Reused for all episodes | Memoized, no input changed |
| Step 1: Speaker identification | Reused for all episodes | Memoized, prompt unchanged |
| Step 2: Statement extraction | Re-runs for all episodes | Extraction prompt changed (new entity type) |
| Entity resolution (person, tech, org) | Reused | Raw entities unchanged, memoized |
| Entity resolution (product) | Runs fresh | New entity type |
| Knowledge base creation | Re-declared | New entities and relationships added |
The expensive operations — downloading audio, transcribing, and identifying speakers — are fully reused. Only the statement extraction LLM calls re-run (because the prompt changed), plus entity resolution for the new type. If you have 50 episodes and add one entity type, you save most of the compute cost.
This is the payoff of CocoIndex's memo and use_mount design: each function is memoized by its inputs, and each session is an independent component. Changes propagate only to what's actually affected.
Running the Pipeline
Prerequisites
- Python 3.11+, FFmpeg, Docker
- An AssemblyAI API key (for transcription)
- An OpenAI API key (for LLM extraction)
Setup
Start SurrealDB:
docker run -d --name surrealdb --user root -p 8787:8000 \
-v surrealdb-data:/data surrealdb/surrealdb:latest \
start --user root --pass root surrealkv:/data/database
Set environment variables and install:
export ASSEMBLYAI_API_KEY="..."
export OPENAI_API_KEY="sk-..."
pip install -e .
Add YouTube URLs to input/sample.txt:
# AI podcasts
https://www.youtube.com/watch?v=VIDEO_ID_1
https://www.youtube.com/watch?v=VIDEO_ID_2
Build the Knowledge Graph
cocoindex update podcast_knowledge.app
This is incremental — re-running skips episodes that have already been processed.
Exploring the Results
Once the pipeline completes, you can explore the knowledge graph in SurrealDB's built-in explorer (Surrealist). Connect to ws://localhost:8787, namespace cocoindex, database yt_conversations.
The graph view shows the relationships between persons and statements — each pink node is a statement, each blue node is a person:

You can also run analytical queries. For example, finding which technologies are mentioned by the most people across all episodes:
SELECT
name,
array::distinct(
<-statement_mentions<-statement<-person_statement<-person.name
) AS persons,
array::len(array::distinct(
<-statement_mentions<-statement<-person_statement<-person.id
)) AS person_count
FROM tech
ORDER BY person_count DESC
LIMIT 15;

Other useful queries:
-- All statements a person made
SELECT <-person_statement<-person.name AS speaker, statement FROM statement;
-- Full graph around a person
SELECT name,
->person_session->session.name AS sessions,
->person_statement->statement.statement AS statements
FROM person;
-- All entities involved in statements
SELECT statement,
->statement_mentions->person.name AS persons,
->statement_mentions->tech.name AS techs,
->statement_mentions->org.name AS orgs
FROM statement;
Summary
We built a pipeline that turns YouTube podcasts into a queryable knowledge graph:
- Fetch: Download audio and transcribe with speaker diarization.
- Extract (two-step): First identify speakers using YouTube metadata, then extract statements with real names — solving the bootstrapping problem of needing to know who's speaking before you can attribute what they said.
- Resolve: Deduplicate entities across episodes using embedding similarity + LLM confirmation — cheap embeddings filter candidates, expensive LLM calls only happen for near-matches.
- Store: Write the knowledge graph to SurrealDB with CocoIndex's declarative target model.
Because every expensive step is memoized and each session is an independent component, the pipeline is fully incremental — whether you're adding episodes or evolving the schema. See Incremental Updates for details.
The full source code is at CocoIndex Examples — podcast_to_knowledge. To stay updated on CocoIndex, star us on GitHub.