From Pickle to Type-Guided Deserialization: How We Made Python Serialization Safe and Automatic

CocoIndex is a framework for building incremental data pipelines. It has a Rust core for performance and exposes a Python SDK for users to define their pipelines. Under the hood, the engine needs to serialize and deserialize Python objects constantly — caching function results, persisting pipeline state, tracking records for change detection — with the serialized data crossing the Rust/Python boundary and stored by the Rust core.
In CocoIndex v0, we had a closed type system: a fixed set of supported data types, with serialization handled entirely in Rust. Safe and fast, but too rigid. Users couldn't use their own data types without converting them into our type system first.
When we started building v1, we wanted to natively support any Python data type. Pickle was the obvious first choice.
Pickle: Fast to Prototype, Painful to Live With
Pickle is Python's built-in serialization. It handles virtually any Python object out of the box — dataclasses, NamedTuples, Pydantic models, nested containers, custom classes. For early prototyping under prerelease, it was perfect: one line of code, and everything just worked.
But pickle has two fundamental problems that make it unsuitable for production.
Security. Pickle executes arbitrary code during deserialization. A crafted payload can run any Python code on your machine. In CocoIndex's case, the serialized data lives in internal storage (a database managed by the framework), so the risk requires an attacker to have access to that storage — which is unlikely for most deployments. Still, defense in depth matters: if the storage is ever exposed through a misconfiguration or a compromised database, pickle becomes an escalation path from data access to code execution. We didn't want that risk in the foundation of our persistence layer.
Overhead. Pickle encodes type information into every value — each value is a sequence of opcodes that tells the deserializer what type to reconstruct and how. This makes pickle self-describing, but at a cost. The integer 1024 takes 15 bytes in pickle, while msgpack encodes it in just 3. Msgpack can be this compact because it relies on the deserializer already knowing the expected type:
| Value | pickle | msgpack | Ratio |
|---|---|---|---|
"" (empty string) | 15 bytes | 1 byte | 15x |
1024 | 15 bytes | 3 bytes | 5x |
"hello" | 20 bytes | 6 bytes | 3.3x |
{"key": [1,2,3]} | 31 bytes | 9 bytes | 3.4x |
Point(42, "origin") | 63 bytes | 16 bytes | 3.9x |
For a pipeline that caches thousands of intermediate results, this overhead adds up.
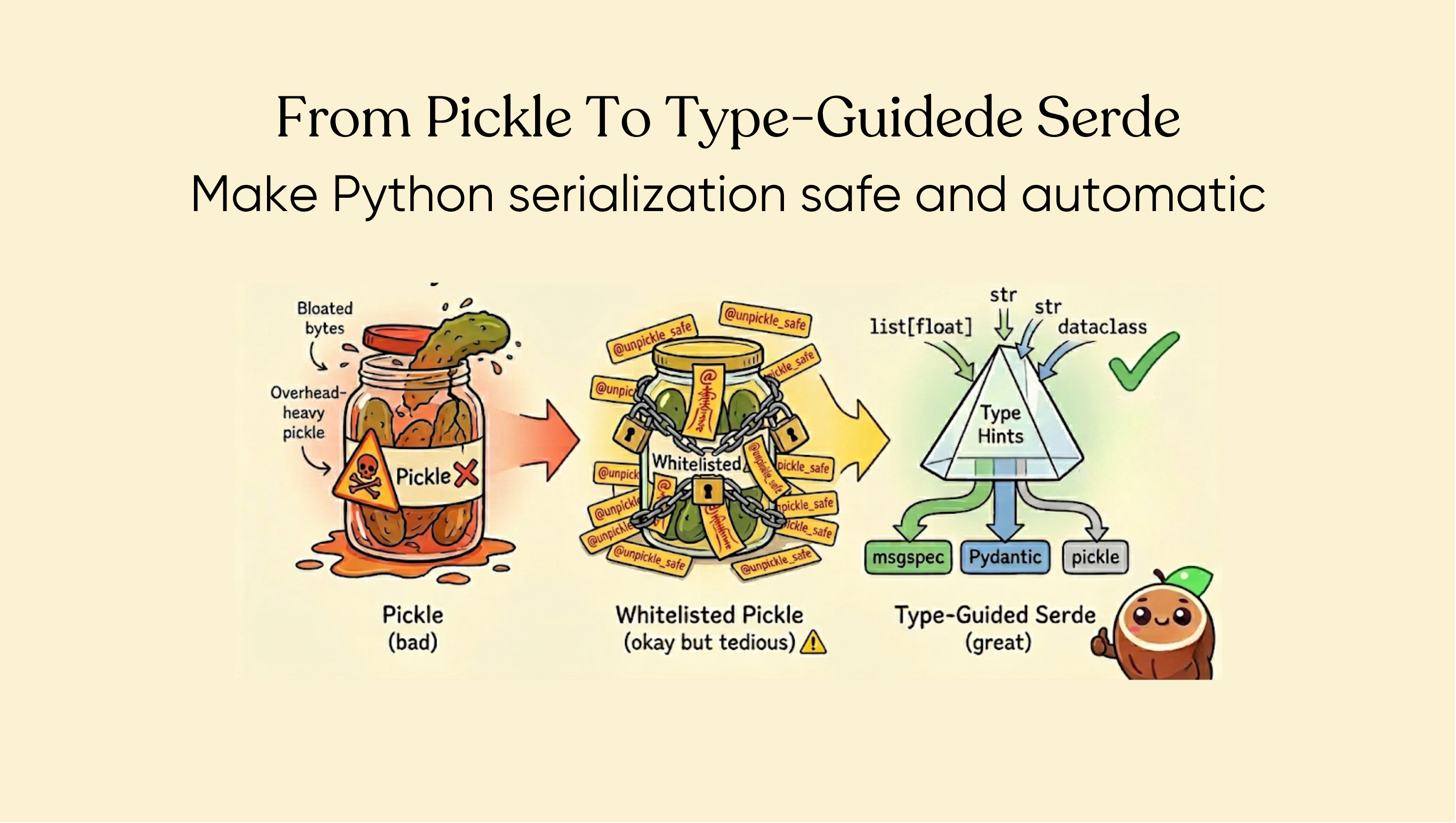
Whitelisted Pickle: Secure but Tedious
Our first attempt to fix the security problem was a restricted unpickler. We maintained an allowlist of types that were safe to deserialize, and rejected everything else. Users could opt their types into the allowlist with a @coco.unpickle_safe decorator:
@coco.unpickle_safe
@dataclass
class DocumentChunk:
text: str
embedding: list[float]
This solved the security problem. But it introduced a new one: annotation burden.
Every type that appeared anywhere in a serialized object graph needed the decorator — not just the top-level type, but every type nested inside it. Miss one, and you get a runtime error.
We experienced this firsthand when building the conversation_to_knowledge example. It needed 9 @coco.unpickle_safe annotations across the codebase. Getting there took 4 rounds of run-fail-annotate-repeat: run the pipeline, hit an error about an unregistered type, add the decorator, run again, hit the next error. Four times.
For our own example. Imagine what this is like for users building real pipelines with dozens of model types.
Type-Guided Deserialization: Letting Type Hints Do the Work
We stepped back and asked: what do we actually have that describes the shape of users' data? The answer was already in their code — type hints.
In CocoIndex, there are three places where data gets serialized and deserialized: memoized function return values (the most common case), memo state values for change detection, and target tracking records. For memoized return values, the type hint is right there in the function signature:
@coco.fn(memo=True)
async def embed_chunk(chunk: str) -> list[float]:
return await embedding_model.embed(chunk)
The return type list[float] tells us exactly how to deserialize the cached result. No extra annotation needed — the type hint that users already write for readability and IDE support doubles as the deserialization schema.
This led us to a type-guided serialization system built on msgspec, a fast msgpack-based serialization library for Python. Msgspec natively handles dataclasses, NamedTuples, and standard types (str, int, list, dict, datetime, UUID, etc.) — and it does so by relying on type information at deserialization time.
The routing byte
Different types need different serialization engines. We use a single routing byte at the start of each payload to select the engine:
| Byte | Engine | Used for |
|---|---|---|
0x01 | msgspec (msgpack) | Dataclasses, NamedTuples, primitives, collections |
0x02 | Pydantic | BaseModel subclasses |
0x80 | Pickle | Opted-in types, legacy data |
Serialization checks types in priority order: explicit pickle opt-in first (the user specifically requested it), then Pydantic models, then msgspec as the default. Deserialization reads the routing byte and dispatches accordingly.
For Pydantic models, we serialize via model_dump(mode="json") into msgpack, and deserialize via TypeAdapter.validate_python(). This avoids pickle entirely while preserving Pydantic's validation semantics.
For types that msgspec can't handle natively — like numpy arrays or pathlib paths — users can opt in to pickle serialization with @coco.serialize_by_pickle. These types get the pickle routing byte (0x80), still through a restricted unpickler for safety.
What changed for users
The conversation_to_knowledge example? All 9 @coco.unpickle_safe annotations — gone. Users define their data types with standard Python type hints, and serialization just works:
@dataclass
class DocumentChunk:
text: str
embedding: list[float]
metadata: dict[str, str]
No decorators. No registration. No run-fail-annotate-repeat cycle. The framework reads the type hint and picks the right serializer and deserializer automatically.
The Edge Cases: When Round-Trip Isn't Perfect
We'd be lying if we said this approach is perfect for every type. There are edge cases with union types that users should be aware of — and these aren't specific to CocoIndex. They're fundamental to how msgspec and Pydantic handle ambiguous types.
msgspec: loud failure
msgspec rejects ambiguous unions at construction time:
import msgspec.msgpack
# These all raise TypeError immediately:
msgspec.msgpack.Decoder(str | datetime.date) # two str-like types
msgspec.msgpack.Decoder(list[int] | tuple[int, ...]) # two array-like types
msgspec.msgpack.Decoder(bytes | bytearray) # two bytes-like types
This is actually a feature. msgspec tells you upfront that these types can't be distinguished on the wire, rather than silently corrupting your data.
Pydantic: silent surprise
Pydantic is more permissive — it accepts date | str — but the behavior after a serialization-deserialization round-trip can be surprising.
Consider a Pydantic model with a date | str field:
class Event(BaseModel):
ts: datetime.date | str
e = Event(ts=datetime.date(2024, 1, 15))
If you serialize this to JSON (or msgpack), date becomes the string "2024-01-15". On deserialization, Pydantic sees a string input and needs to decide: is it a str or a date?
With Pydantic v2's default smart mode, the answer is always str. Smart mode scores candidates by exactness: a string input is an exact match for str but only a lax match (requires coercion) for date. Exact wins. Ordering doesn't matter — date | str and str | date both produce str.
Left-to-right mode behaves differently. With date | str ordering, Pydantic tries date first, the lax coercion from "2024-01-15" succeeds, and you get your date back:
from pydantic import Field
from typing import Annotated
class Event(BaseModel):
# Left-to-right mode: more specific type first
ts: Annotated[datetime.date | str, Field(union_mode='left_to_right')]
But this requires users to explicitly opt in to left-to-right mode AND put the more specific type first.
The fundamental issue
This isn't a bug in any library. It's inherent to the wire format. Msgpack (like JSON) has no date type — dates are serialized as strings. Once the type information is erased on the wire, no amount of clever decoding can reliably recover it when multiple types map to the same wire representation.
The practical advice: avoid union types where members share a wire representation in data objects that go through serialization. Use unambiguous types, or use Pydantic's discriminated unions with a literal tag field.
What We Learned
Type hints are an underutilized source of truth. Python developers already annotate their data types. Using those annotations for serialization is a natural extension — no new concepts, no new decorators, no new registration APIs.
Make ambiguity loud, not silent. msgspec's approach of rejecting ambiguous unions at construction time is better than silently producing wrong results. When building a serialization layer, fail early and clearly.
Don't fight the wire format. If the wire format can't distinguish two types, your serialization layer can't either. Design your data types around what the serialization format can express, not the other way around.
Start simple, but have a plan. Pickle was right for prototyping. The whitelisted pickle was right for the security fix. The type-guided approach was right for production. Each step taught us what the next step needed to be.
Learn More
- CocoIndex on GitHub — the open-source data indexing framework
- CocoIndex v1 Documentation — getting started guides and API reference
- Building an Invisible Daemon — how we built the local daemon architecture behind CocoIndex
Support us
⭐ Star CocoIndex on GitHub and share with your community if you find it useful!