

CocoIndex reached v1.0 at the start of this cycle.
This is the first changelog since the v1 launch, covering seven releases (1.0.1–1.0.7). The focus is on making the engine easier to operate in production pipelines, then connecting it to more of the systems where teams already store data.
CocoIndex builds fresh, structured context for AI from sources such as PDFs, codebases, emails, screenshots, and meeting notes, and keeps it up to date with an incremental engine. The source is on GitHub.
The short version
The engine work is the headline this cycle. If you run long-lived, expensive, or shared pipelines:
- Per-argument memoization keys let you exclude clients, loggers, and debug flags from the cache key, so recomputation depends only on the inputs that matter.
coco.auto_refreshturns “poll this source every few minutes” into a live component with consistent error handling and target-state reconciliation.coco.stats_group(...)breaks theadds/reprocesses/deletescounts down by data slice (per tenant, project, or folder) instead of one aggregate per processor.- New connectors: OCI Object Storage and Apache Iggy as sources; Turbopuffer, Neo4j, and FalkorDB as targets; LanceDB gained background compaction and in-place schema evolution.
- Security and correctness fixes, including SQL identifier injection hardening and a concurrency race that only appeared under real database latency.
Engine
Per-argument memoization control
@coco.fn now accepts a per-argument memo_key, giving you fine-grained control over which arguments participate in the memoization cache key.
Production functions take more than data: clients, handles, config objects, loggers, tracing context, debug flags. Those values change across runs even when the meaningful input is identical, and each change could invalidate the cache and rerun expensive transforms, embeddings, or LLM calls for the wrong reason. memo_key keeps the cache keyed to the semantic input.
The API maps parameter names to either a callable (transform the value before fingerprinting) or None (exclude the parameter entirely):
@coco.fn(memo=True, memo_key={"entry": lambda e: (e.name, e.version), "extra": None})
def transform(entry: SourceDataEntry, extra: str) -> str:
...- Callable → applied to the argument; its return value is fingerprinted in place of the original.
None→ the parameter is excluded from the memo key; changing it never invalidates the cache.- Not listed → fingerprinted normally.

Read more in Memoization keys & states → Override at the call site (#1888, #2000).
coco.auto_refresh for live components
A common live-mode pattern is “run this processor on a fixed schedule.” coco.auto_refresh now makes that pattern first-class.
Without an engine-level primitive, every pipeline hand-rolls the same loop and re-decides how errors propagate and how missing rows get reconciled. coco.auto_refresh wraps any processor function as a live component that re-runs on an interval and routes cycle failures through one error-handling channel.
import datetime
import cocoindex as coco
@coco.fn
async def app_main(db, target) -> None:
await coco.mount(
coco.auto_refresh(sync_users, interval=datetime.timedelta(minutes=5)),
db, target,
)Each cycle reconciles target states against the previous cycle. If sync_users stops declaring a row, CocoIndex deletes the corresponding target automatically. See Live components → periodic refresh (#1995).
Scoped stats reports
By default, CocoIndex already breaks stats down by processor: each entry function (process_doc, process_code, …) reports its own counts: adds, reprocesses, deletes. What it can’t do by default is break those counts down across data slices. coco.stats_group(title) opens a scope where everything mounted inside aggregates into a separate report under title, split out of the parent (no double counting).
Seeing that one tenant did 600 reprocesses while another did 1,150 fresh adds tells you who is churning, who is growing, and where an unexpected reprocess storm came from. One aggregate per processor hides all of that. The natural slice is the data: per tenant, per project, or per source folder.
@coco.fn
async def app_main(tenants, target):
for tenant in tenants:
# same processor, but stats scoped per tenant
with coco.stats_group(f"tenant:{tenant.id}", report_to_stdout=True):
files = localfs.walk_dir(tenant.docs_dir, ...)
await coco.mount_each(process_doc, files.items(), target)
The block also yields a handle with the same stats() and watch() methods as UpdateHandle, so you can stream a single slice’s counts to a dashboard. See Progress monitoring → Scoped reports (#2042).
Other engine improvements
- Configurable logging: set the Python logger level directly via the
COCOINDEX_LOG_LEVELenvironment variable (#2035). - Cleaner Rust internals: the workspace was unified and the core SDK isolated from PyO3, separating the engine from its Python bindings and laying the groundwork for native Rust consumers of the engine (#1973).
Built-in operations
LiteLLM speech-to-text
CocoIndex added speech-to-text (STT) support through LiteLLM (#1889), so audio sources can be transcribed inside a pipeline using any LiteLLM-backed STT provider. A LiteLLMTranscriber wraps the transcription API:
from cocoindex.ops.litellm import LiteLLMTranscriber
transcriber = LiteLLMTranscriber("whisper-1")
transcript = await transcriber.transcribe(audio_file)Code splitter: eight new languages
The RecursiveSplitter gained tree-sitter support for eight new languages this cycle, so syntax-aware chunking now covers a much wider slice of real codebases and config:
- Svelte and Vue: component-aware chunking for frontend code (#1937)
- Julia: for scientific and numerical codebases (#1942)
- Elm (#1955) and Astro (#1984)
- Bash, CMake, and HCL: shell scripts, build files, and Terraform/infra configs (#1954)
Pass the language name to language= (or let detect_code_language() infer it from a filename):
from cocoindex.ops.text import RecursiveSplitter
splitter = RecursiveSplitter()
chunks = splitter.split(source_code, chunk_size=2000, chunk_overlap=200, language="svelte")Entity resolution: parallel by default
Entity resolution (dedup-and-canonicalize a set of extracted entity names) now resolves independent connected components of the candidate graph in parallel, speeding up LLM-backed deduplication on large entity sets (#2006).
Connectors
Source: OCI Object Storage with live bucket watching
A new Oracle Cloud Infrastructure (OCI) Object Storage source mirrors the S3 source’s API for scanning a bucket, and adds an optional live mode.
It’s a good illustration of the stream–state duality in CocoIndex’s source model. A bucket is state: list_objects() scans it and establishes the full set of objects. A change feed is a stream: when you supply a live_stream, CocoIndex does the initial scan once and then keeps watching, applying createobject / updateobject / deleteobject events incrementally instead of rescanning. For OCI those events flow through OCI Streaming, consumed over the Kafka protocol; an event-time cutoff with a 5-second clock-skew tolerance decides which streamed events predate the scan. Under the hood it’s built on a new lower-level LiveStream abstraction, a keyless stream of messages with in-memory watermark tracking and ack-on-completion (#1905).

This is the same model CocoIndex already uses for the local file system, where the change stream comes from OS file-system events rather than Kafka. More sources, such as S3, will gain live mode over time.
Source: Apache Iggy
CocoIndex now reads from Apache Iggy, a persistent message-streaming platform (#1969).
Target: Turbopuffer
A new Turbopuffer target connector landed, along with a runnable text-embedding example (#1934).
Target: Neo4j
A native Neo4j property-graph target landed alongside a meeting_notes_graph_neo4j example, mapping nodes and relationships into Neo4j without writing Cypher by hand (#1932).
Target: FalkorDB
The FalkorDB property-graph target was brought forward into the v1 connector set, with support for nodes, relationships, and vector/FTS indexes (#1908).
Target: LanceDB
LanceDB got two upgrades for production workloads:
- The v1 target now optimizes (compacts) tables periodically in the background, keeping query performance steady as data churns (#2008, with a scheduling fix in #2013).
- Table targets can add new columns in place, so schema evolution doesn’t require a rebuild (#1951).
Bug fixes
Postgres correctness
halfvecop classes are now used for indexes on half-precision vectors (#2029).U+0000(NUL) bytes are stripped when writingtext/jsonb, so Postgres no longer rejects otherwise-valid payloads (#2032).- The
pgvectorextension now installs into the default schema, avoidingsearch_pathsurprises (#1979).
Other fixes
- SQL identifier validation: the Postgres and SQLite connectors now validate table and column identifiers before interpolating them into statements, closing a class of SQL-injection vectors at the connector boundary (#1947, #1965).
- Ownership-transfer race: a pending-state protocol closes a preempt race so target-state ownership transfer stays correct under Postgres I/O latency, not just on microsecond-fast LMDB (#1994).
- Clean cancellation: cancellation propagates through task spawn boundaries, tearing work down cleanly instead of leaking orphaned tasks (#1902).
on_errorcascade: errors cascade through the Build-mode GC sweep (#1999).- numpy serde:
_frombufferis registered under both numpy 1.x and 2.x paths (#2012). - Responsive progress display: the PTY reader moved onto a dedicated OS thread, keeping the async runtime responsive under heavy logging (#2033, #2040).
Build with CocoIndex
Meeting notes → knowledge graph, now on Neo4j
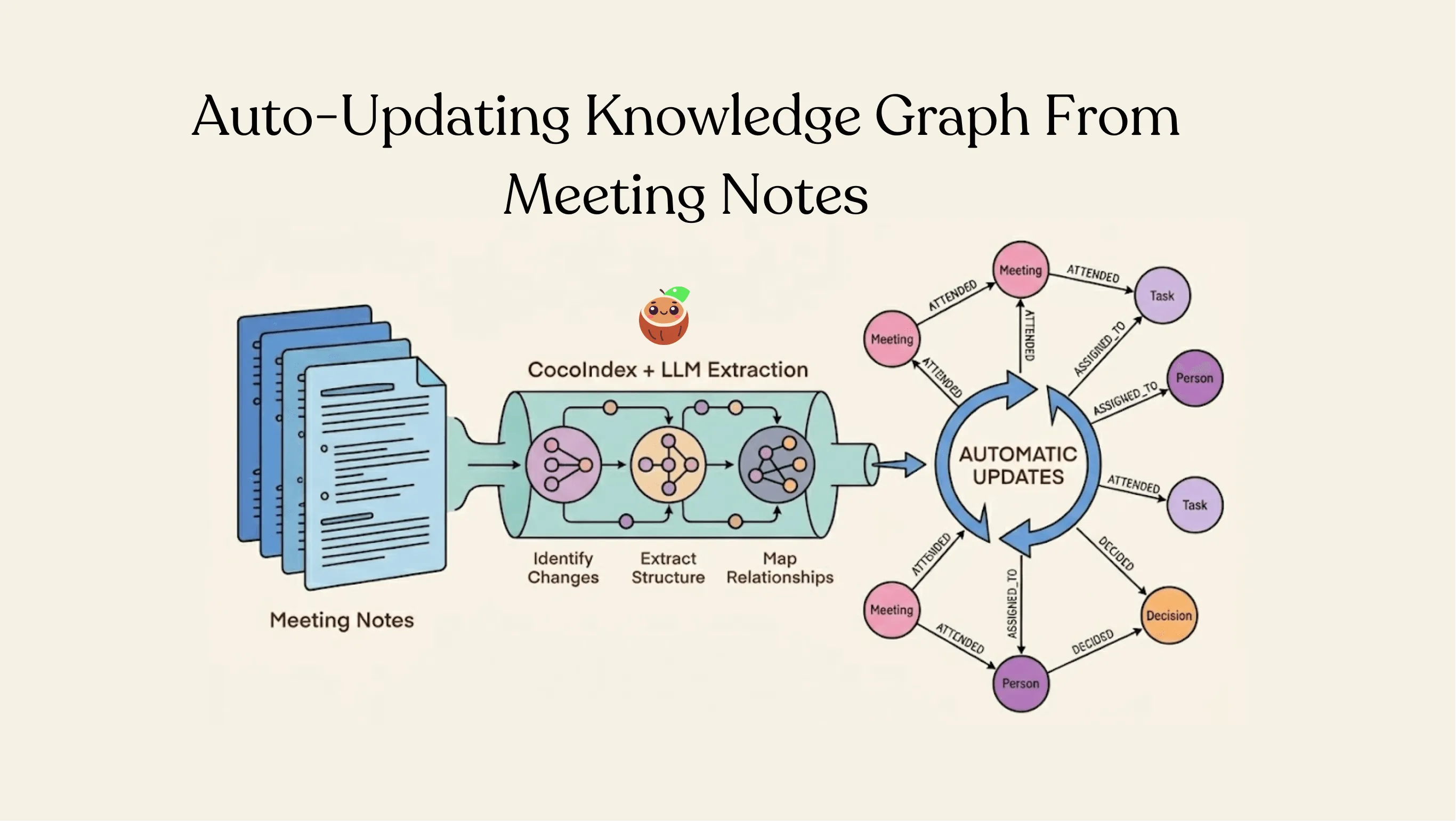
The popular meeting-notes-to-knowledge-graph example now ships in a Neo4j flavor (meeting_notes_graph_neo4j). It watches a folder of meeting notes, uses LLM extraction to pull out structured entities (Meetings, People, Tasks) and the relationships between them, then maps everything into Neo4j as nodes and edges. Change one note and CocoIndex reprocesses only that note, keeping the graph continuously in sync.
Turbopuffer and OCI text-embedding examples
Two more end-to-end examples landed alongside the new connectors: text_embedding_turbopuffer shows a complete embed-and-query pipeline against Turbopuffer, and oci_object_storage_embedding demonstrates ingesting from OCI Object Storage with live bucket watching. Both are ready to clone and run.
Watch: build it end to end on FalkorDB
Follow along with the Build with CocoIndex walkthrough, which builds the meeting-notes-to-knowledge-graph pipeline end to end on FalkorDB, then clone the meeting_notes_graph_falkordb example to run it yourself.
For the complete list of changes, see the GitHub releases. If CocoIndex is useful to you, consider starring the repository.
Thanks to the community
Thanks to the contributors who shipped changes this cycle.
@prrao87
Thanks @prrao87 for fixing LanceDB optimize scheduling.
@zherendong
@countradooku
Thanks @countradooku for adding the Apache Iggy connector.
@Haleshot
Thanks @Haleshot for keeping the docs in shape after the v1 launch: removing the stale v1 mention from the install command, fixing a broken URL, and updating stale v1 branch links to main.
@galshubeli
Thanks @galshubeli for bringing the FalkorDB target connector into the v1 connector set.
@Gohlub
Thanks @Gohlub for adding LiteLLM speech-to-text support, CocoIndex’s first audio operation.
@MrAnayDongre
Thanks @MrAnayDongre for adding per-argument memo_key support to @coco.fn.
@aaronjmars
@tuanaiseo
Thanks @tuanaiseo for reporting and fixing a potential SQL injection in the Postgres connector, responsibly disclosed.
@nuthalapativarun
Thanks @nuthalapativarun for a prolific cycle of splitter work: adding Elm, Astro, and Bash, CMake, and HCL tree-sitter support, plus adding context to Rust→Python error messages and expanding the supported-languages docs.
@qWaitCrypto
Thanks @qWaitCrypto for making the LanceDB v1 target optimize tables periodically and for adding columns in place.
@shaiar
@octo-patch
@phuctoan123
Thanks @phuctoan123 for documenting gws for Google Drive setup.

About the author.

Maintainer of CocoIndex, Ex-Google Infra Lead. Writes about incremental data infrastructure, Rust internals, and the engineering decisions behind the engine.
Frequently asked questions.
How do I avoid re-embedding my whole corpus when one document changes?
Build the pipeline on CocoIndex's incremental engine instead of a re-index script. You declare the target state — "these documents, chunked and embedded, should exist in this vector store" — and CocoIndex fingerprints every input and intermediate value. When one document changes, only that document is re-chunked and re-embedded; everything else is served from cache, and rows for deleted sources are removed automatically. There is no separate "initial load" vs. "incremental update" code path. This is the engine behind the whole 1.0 line — see The short version and the Incremental processing deep dive.
How do I cache expensive LLM extraction calls so they don't re-run every pipeline run?
Mark the function with @coco.fn(memo=True) and CocoIndex fingerprints its inputs, returning the cached result whenever they're unchanged — so an LLM extraction, embedding, or transcription call never re-runs for input it has already seen. This cycle added per-argument memo_key for fine-grained control: map each parameter to a callable (transform the value before fingerprinting) or None (exclude it entirely). See Per-argument memoization control in this changelog and Memoization keys & states in the docs.
How do I exclude a client, logger, or config argument from an LLM cache key?
Use memo_key on @coco.fn to pass None for any parameter that shouldn't participate in the cache key:
@coco.fn(memo=True, memo_key={"client": None, "entry": lambda e: (e.name, e.version)})
A parameter set to None is excluded — changing it never invalidates the cache — while a callable is applied to the argument and its return value is fingerprinted in place of the original. That keeps the cache keyed to the semantic input, so clients, handles, loggers, tracing context, and debug flags stop triggering needless recomputation of expensive LLM calls. See Per-argument memoization control and the docs section Override at the call site with memo_key.
How do I keep a vector database continuously in sync with a folder, S3, or object-storage bucket?
Run the pipeline in live mode. File sources (local, S3, OCI Object Storage) watch for changes and re-derive only the affected rows; for sources without native change events, wrap the processor in coco.auto_refresh(fn, interval=...) to re-run it on a schedule with unified error handling and automatic target reconciliation — if a row stops being declared, its target is deleted. The new OCI Object Storage source opts into live bucket watching over an OCI Streaming topic. See coco.auto_refresh for live components, the live-component docs, and the Continuous updates walkthrough.
How do I run LLM-based entity resolution / dedup without it being painfully slow?
CocoIndex's entity resolution now runs in parallel: it splits the candidate graph into connected components and resolves each one concurrently, so entities that can't possibly match no longer wait on each other. On large entity sets this materially speeds up LLM-backed deduplication. Combined with memoization, an entity pair that was already judged isn't re-sent to the model on the next run. See Parallel entity resolution.
What's the best way to chunk code for RAG (syntax-aware code chunking)?
Use RecursiveSplitter, which chunks along the syntax tree (via tree-sitter) instead of fixed line or character windows — so functions, classes, and blocks stay intact rather than being split mid-structure. This cycle added eight new languages: Svelte, Vue, Julia, Elm, Astro, Bash, CMake, and HCL (Terraform). Pass language= explicitly or let detect_code_language() infer it from the filename. See Code splitter: eight new languages and the end-to-end Index a codebase for RAG guide.
How do I get per-stage observability and stats in a data pipeline?
Wrap each phase in with coco.stats_group("Indexing docs"): and everything mounted inside aggregates into a separate report, split out of the parent with no double counting — so you can see whether docs ingestion, code indexing, extraction, or graph writes account for runtime and churn. The block also yields a handle with the same stats() and watch() methods as UpdateHandle, so a single phase's progress can stream to a dashboard. See Scoped stats reports and Progress monitoring → Scoped reports.
How do I write embeddings to Turbopuffer, LanceDB, or FalkorDB from Python?
Each is a built-in target connector — declare it as your pipeline's target and CocoIndex handles upserts, deletes, and incremental reconciliation. Turbopuffer brings serverless, object-storage-backed vector + full-text search (with a ready embedding example); LanceDB now compacts tables in the background and adds columns in place for schema evolution without a rebuild; FalkorDB is a Redis-based property graph with nodes, relationships, and vector/FTS indexes. See Target: Turbopuffer, Target: LanceDB, and Target: FalkorDB.
How do I build a streaming / Kafka-driven RAG pipeline?
Use a streaming source and let live mode drive the pipeline off the event stream. The new OCI Object Storage source consumes change events over the Kafka protocol (an OCI Streaming topic) on top of a low-level LiveStream abstraction with watermark tracking and ack-on-completion, and the new Apache Iggy source reads from the high-throughput Iggy message-streaming platform. Each streamed change re-derives only the affected rows and embeddings. For the Kafka target side — publishing diff-only change events out to a topic — see Live CSV → Kafka.