In this blog, we will show you how to index a codebase for RAG with CocoIndex. CocoIndex provides built-in support for codebase chunking, with native Tree-sitter support and real-time update.
Because we use incremental processing (only reprocessing what has changed) under the hood, the index is updated in near real-time. It can be real-time if we integrate with any source that directly pushes change notifications, e.g., a code editor. This can be built for code search applications, or for providing relevant context to AI code generation systems where low latency is critical for a seamless developer experience.
It’d mean a lot to us if you could ⭐ star CocoIndex on Github, if this tutorial helps you.

Tree-sitter
CocoIndex leverages Tree-sitter’s capabilities to intelligently chunk code based on the actual syntax structure rather than arbitrary line breaks. These syntactically coherent chunks are then used to build a more effective index for RAG systems, enabling more precise code retrieval and better context preservation.
Tree-sitter is a parser generator tool and an incremental parsing library; it is available in Rust 🦀.
You can find the full code of this project here, and a walkthrough in the index-codebase example. Only ~ 50 lines of Python on the indexing path, check it out :rocket:!
Use case
- Build semantic code context for AI coding agents like Claude, Codex, Gemini CLI.
- Build MCP for code editors such as Cursor, Windsurf, and VSCode.
- Build context-aware code search applications - semantic code search, natural language code retrieval.
- Build context for code generation applications - AI code generation, code autocompletion, code assistant bots.
- Build context for code review applications - AI-powered code review, automated code analysis, code quality checks, pull request summarization, code diff understanding.
- Build context for code refactoring applications - automated code refactoring, code transformation, large-scale code migration.
Why build with CocoIndex?
- Super scalable, ultra-performant, core engine written in Rust. Works with very large codebases.
- Incremental processing, only re-process what has changed, no need to re-index the whole codebase on what’s changed, real-time performance with minimal computation.
- Logic customizable, pick your favorite embedding model, strategy, vector database, and more.
Prerequisites
If you don’t have Postgres installed, please follow the installation guide. CocoIndex uses Postgres to keep track of data lineage for incremental processing.
Define indexing flow
Flow design
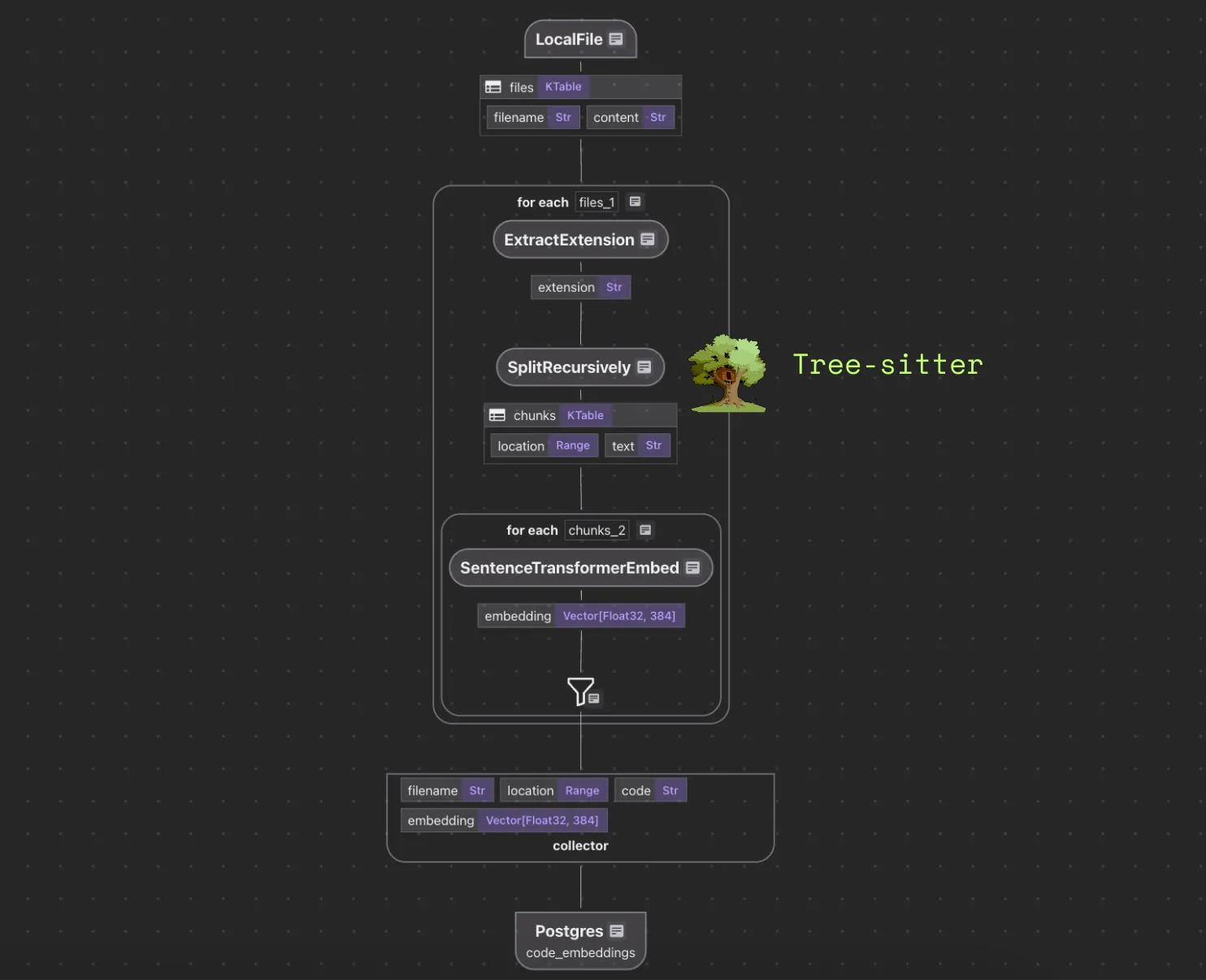
The flow diagram illustrates how we’ll process our codebase:
- Read code files from the local filesystem
- Extract file extensions, to get the language of the code for Tree-sitter to parse
- Split code into semantic chunks using Tree-sitter
- Generate embeddings for each chunk
- Store in a vector database for retrieval
1. Add the codebase as a source.
@cocoindex.flow_def(name="CodeEmbedding")
def code_embedding_flow(flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope):
"""
Define an example flow that embeds files into a vector database.
"""
data_scope["files"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="../..",
included_patterns=["*.py", "*.rs", "*.toml", "*.md", "*.mdx"],
excluded_patterns=[".*", "target", "**/node_modules"]))
code_embeddings = data_scope.add_collector()We ingest the CocoIndex codebase from the root directory.
We can change the path to the codebase you want to index.
We index all the files with the extensions of .py, .rs, .toml, .md, .mdx, and skip directories starting with ., target (in the root) and node_modules (under any directory).
flow_builder.add_source will create a table with sub fields (filename, content). We can refer to the documentation for more details.
2. Process each file and collect the information.
2.1 Extract the extension of a filename
We need to pass the language (or extension) to Tree-sitter to parse the code. Let’s define a function to extract the extension of a filename while processing each file. You can find the documentation for custom functions here.
@cocoindex.op.function()
def extract_extension(filename: str) -> str:
"""Extract the extension of a filename."""
return os.path.splitext(filename)[1]Then we are going to process each file and collect the information.
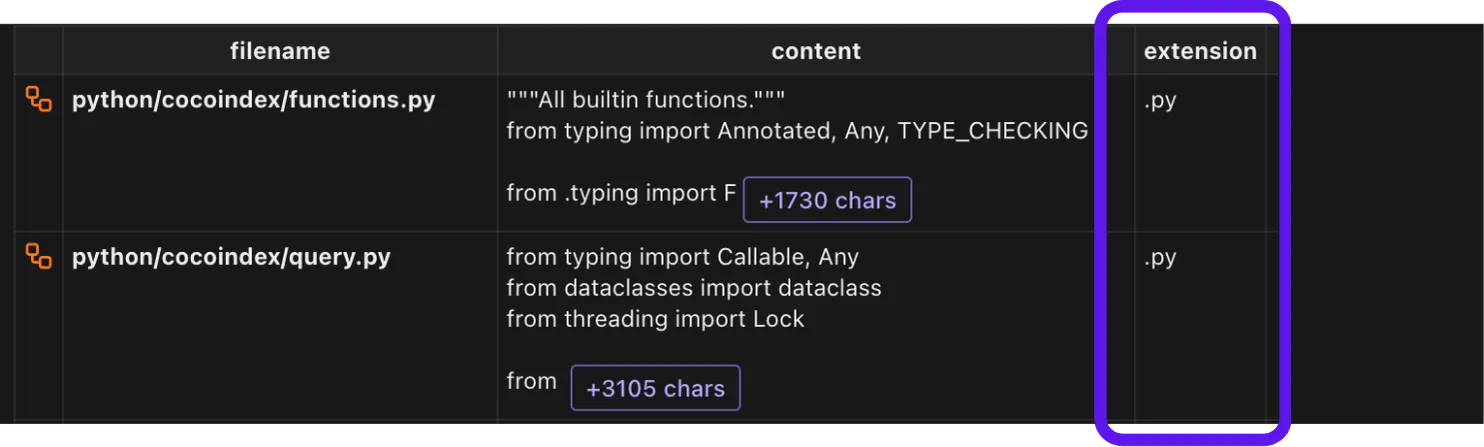
with data_scope["files"].row() as file:
file["extension"] = file["filename"].transform(extract_extension)Here we extract the extension of the filename and store it in the extension field.
2.2 Split the file into chunks
We will chunk the code with Tree-sitter.
We use the SplitRecursively function to split the file into chunks.
It is integrated with Tree-sitter, so you can pass in the language to the language parameter.
To see all supported language names and extensions, see the documentation here. All the major languages are supported, e.g., Python, Rust, JavaScript, TypeScript, Java, C++, etc. If it’s unspecified or the specified language is not supported, it will be treated as plain text.
with data_scope["files"].row() as file:
file["chunks"] = file["content"].transform(
cocoindex.functions.SplitRecursively(),
language=file["extension"], chunk_size=1000, chunk_overlap=300) 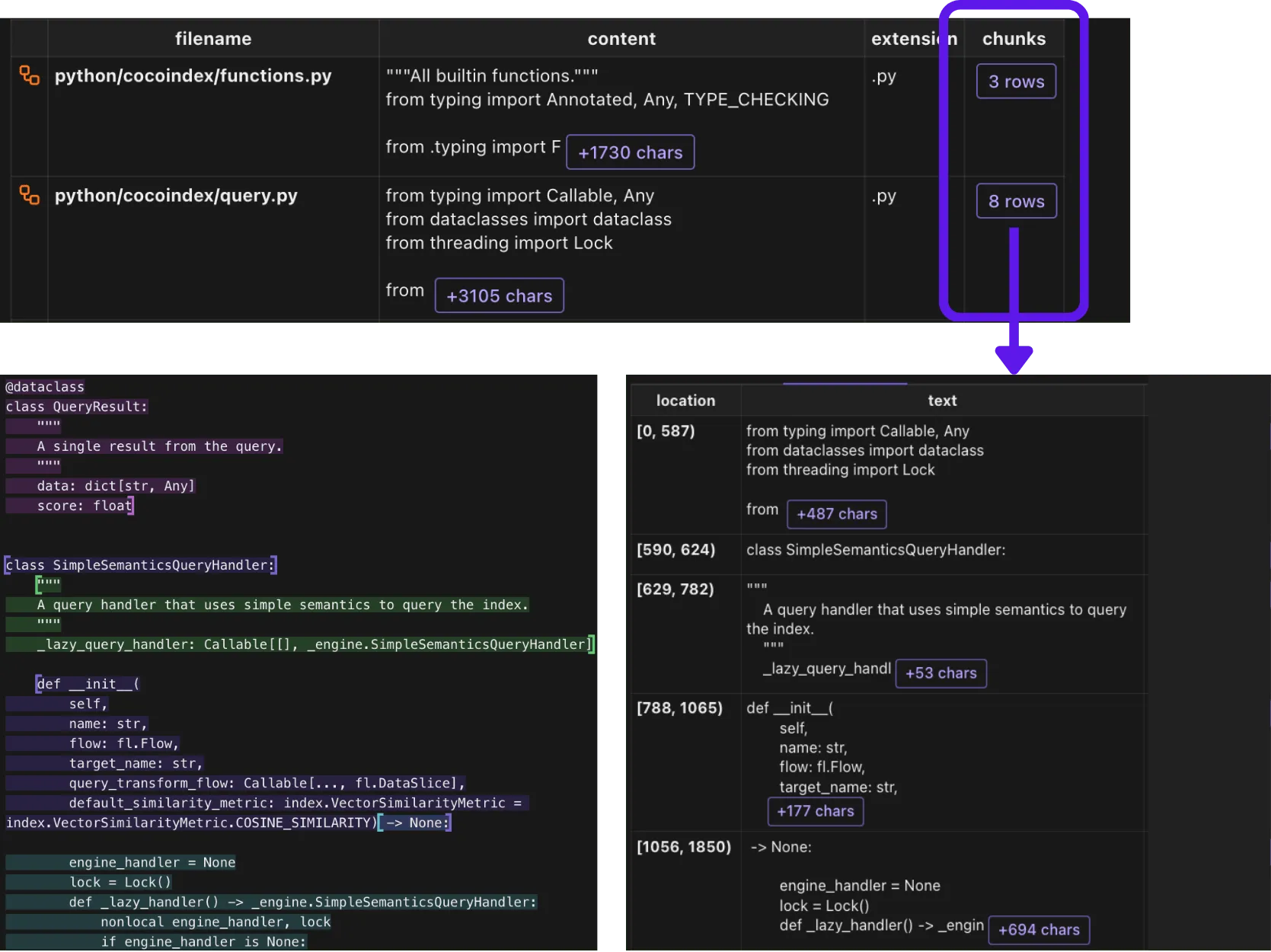
2.3 Embed the chunks
We use SentenceTransformerEmbed to embed the chunks.
You can refer to the documentation here.
There are 12k models supported by 🤗 Hugging Face.
You can just pick your favorite model.
@cocoindex.transform_flow()
def code_to_embedding(text: cocoindex.DataSlice[str]) -> cocoindex.DataSlice[list[float]]:
"""
Embed the text using a SentenceTransformer model.
"""
return text.transform(
cocoindex.functions.SentenceTransformerEmbed(
model="sentence-transformers/all-MiniLM-L6-v2"))Then for each chunk, we will embed it using the code_to_embedding function and collect the embeddings to the code_embeddings collector.
@cocoindex.transform_flow() is needed to share the transformation across indexing and query. We build a vector index and query against it;
the embedding computation needs to be consistent between indexing and querying. See documentation for more details.
with data_scope["files"].row() as file:
with file["chunks"].row() as chunk:
chunk["embedding"] = chunk["text"].call(code_to_embedding)
code_embeddings.collect(filename=file["filename"], location=chunk["location"],
code=chunk["text"], embedding=chunk["embedding"])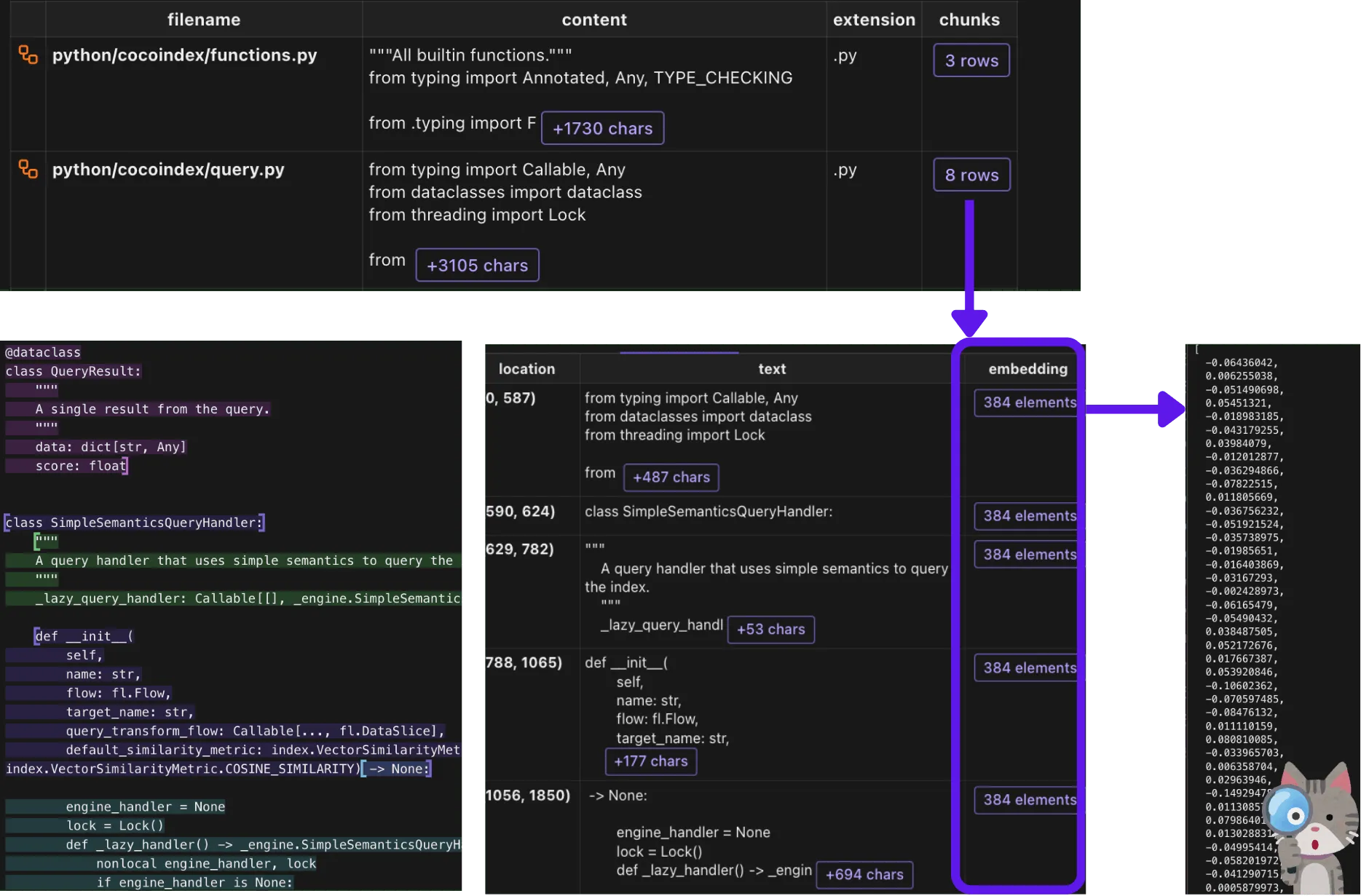
2.4 Collect the embeddings
Export the embeddings to a table.
code_embeddings.export(
"code_embeddings",
cocoindex.storages.Postgres(),
primary_key_fields=["filename", "location"],
vector_indexes=[cocoindex.VectorIndex("embedding", cocoindex.VectorSimilarityMetric.COSINE_SIMILARITY)])We use Cosine Similarity to measure the similarity between the query and the indexed data. To learn more about Cosine Similarity, see Wiki.
3. Query the index
We match against user-provided text by a SQL query, reusing the embedding operation in the indexing flow.
def search(pool: ConnectionPool, query: str, top_k: int = 5):
# Get the table name, for the export target in the code_embedding_flow above.
table_name = cocoindex.utils.get_target_storage_default_name(code_embedding_flow, "code_embeddings")
# Evaluate the transform flow defined above with the input query, to get the embedding.
query_vector = code_to_embedding.eval(query)
# Run the query and get the results.
with pool.connection() as conn:
with conn.cursor() as cur:
cur.execute(f"""
SELECT filename, code, embedding <=> %s::vector AS distance
FROM {table_name} ORDER BY distance LIMIT %s
""", (query_vector, top_k))
return [
{"filename": row[0], "code": row[1], "score": 1.0 - row[2]}
for row in cur.fetchall()
]Define a main function to run the query in the terminal.
def main():
# Initialize the database connection pool.
pool = ConnectionPool(os.getenv("COCOINDEX_DATABASE_URL"))
# Run queries in a loop to demonstrate the query capabilities.
while True:
try:
query = input("Enter search query (or Enter to quit): ")
if query == '':
break
# Run the query function with the database connection pool and the query.
results = search(pool, query)
print("\nSearch results:")
for result in results:
print(f"[{result['score']:.3f}] {result['filename']}")
print(f" {result['code']}")
print("---")
print()
except KeyboardInterrupt:
break
if __name__ == "__main__":
main()Run the index setup & update
🎉 Now you are all set!
Run the following command to set up and update the index.
cocoindex update --setup mainYou’ll see the index updates state in the terminal.

Test the query
At this point, you can start the CocoIndex server and develop your RAG runtime against the data. To test your index, you could
python main.pyWhen you see the prompt, you can enter your search query. For example: spec.
You can find the search results in the terminal.
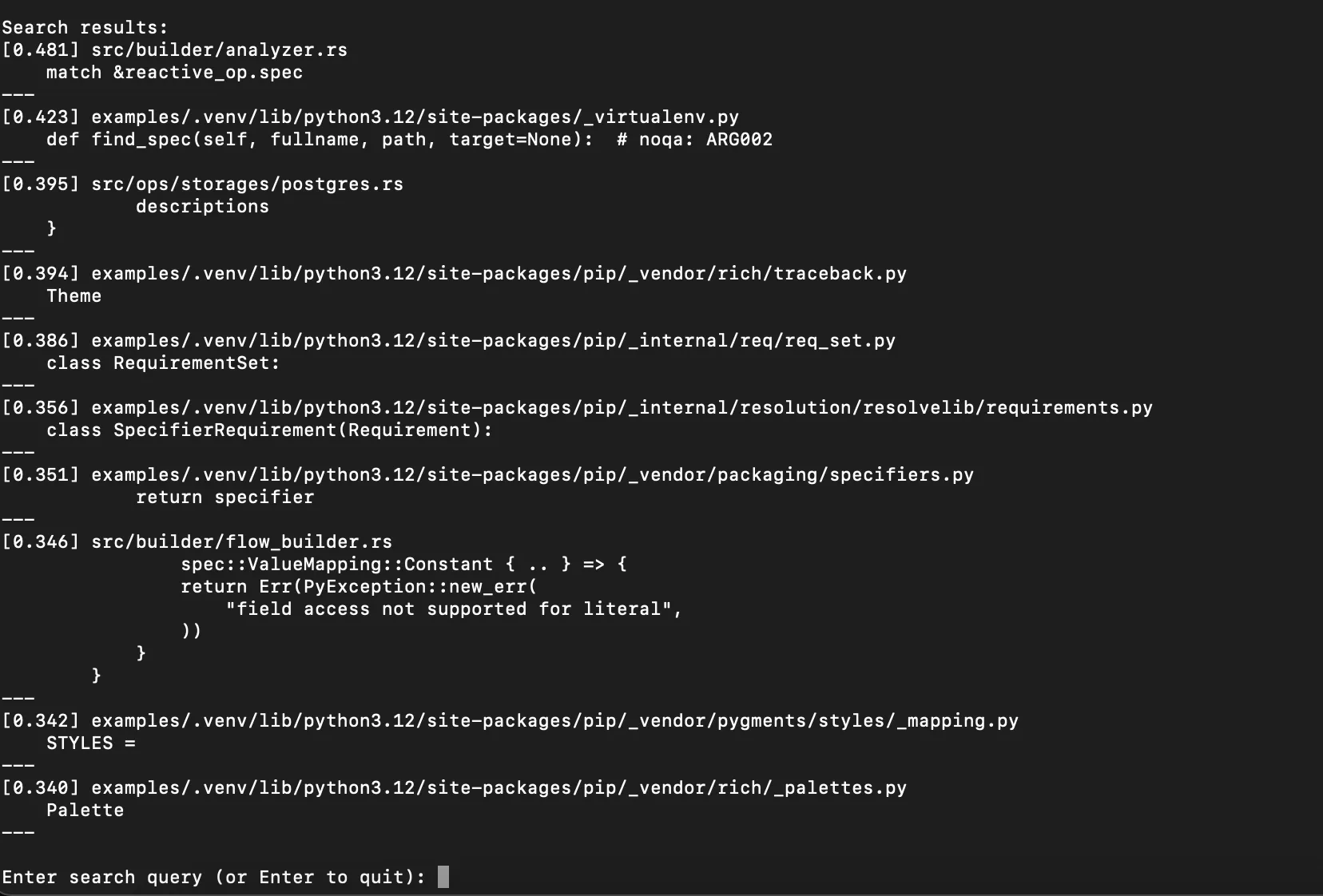
The returned results: each entry contains the score (Cosine Similarity), filename, and the code snippet that gets matched.
Support us
We are constantly improving, and more features and examples are coming soon. If you love this article, please give us a star ⭐ at GitHub to help us grow.
Thanks for reading!

CocoIndex
An incremental engine for long-horizon agents — always-fresh, explainable data, one Python file.
About the author.

Posts from the CocoIndex team — product launches, release notes, and announcements.
Frequently asked questions.
How do I index a codebase for RAG with CocoIndex?
You build a short indexing flow: add the codebase as a LocalFile source, extract each file's extension to detect its language, split the code into semantic chunks with Tree-sitter, embed each chunk, and export the embeddings to a vector index in Postgres. The indexing path is only about 50 lines of Python, and you query it by reusing the same embedding function.
See Define indexing flow.
Why use Tree-sitter for chunking code instead of fixed line windows?
CocoIndex uses Tree-sitter to chunk code based on the actual syntax structure rather than arbitrary line breaks. The resulting chunks are syntactically coherent, which builds a more effective RAG index and enables more precise retrieval with better context preservation. Tree-sitter is a parser generator and incremental parsing library available in Rust.
See Tree-sitter.
Which programming languages can CocoIndex chunk with Tree-sitter?
Chunking uses the SplitRecursively function, which is integrated with Tree-sitter; you pass the language via the language parameter (here derived from the file extension). All major languages are supported, including Python, Rust, JavaScript, TypeScript, Java, and C++. If the language is unspecified or unsupported, the content is treated as plain text.
How do I choose an embedding model for code search in CocoIndex?
The example embeds chunks with SentenceTransformerEmbed using the sentence-transformers/all-MiniLM-L6-v2 model, but you can pick any of the 12k models supported by Hugging Face sentence-transformers. The embedding is wrapped in a @cocoindex.transform_flow() so the exact same computation is shared between the indexing path and the query path.
See Embed the chunks.
Why does the embedding need to be the same for indexing and querying?
You build a vector index at indexing time and query against it at search time, so the embedding computation must be consistent between the two; otherwise the query vector and the indexed vectors are not comparable. CocoIndex handles this by sharing the embedding logic through @cocoindex.transform_flow(), which the query path reuses via code_to_embedding.eval(query).
See Embed the chunks and Query the index.
How does CocoIndex keep a code index up to date in near real-time?
CocoIndex uses incremental processing under the hood, reprocessing only what has changed, so the index updates in near real-time. It can be fully real-time if you integrate a source that pushes change notifications, such as a code editor. CocoIndex uses Postgres to track data lineage for this incremental processing.
See Prerequisites.
How do I query the code embeddings index?
You match user text against the index with a SQL query that reuses the indexing flow's embedding operation to turn the query into a vector, then orders results by pgvector's cosine distance (embedding <=> %s::vector) and returns the top-k. Each result carries a Cosine Similarity score, the filename, and the matched code snippet. Run python main.py and type a query at the prompt.
See Query the index and Test the query.