Index codebase for RAG

Overview
In this blog, we will show you how to index codebase for RAG with CocoIndex. CocoIndex is a tool to help you index and query your data. It is designed to be used as a framework to build your own data pipeline. CocoIndex provides built-in support for code base chunking, with native Tree-sitter support.
Tree-sitter
Tree-sitter is a parser generator tool and an incremental parsing library, it is available in Rust 🦀 - GitHub. CocoIndex has built-in Rust integration with Tree-sitter to efficiently parse code and extract syntax trees for various programming languages.
Codebase chunking is the process of breaking down a codebase into smaller, semantically meaningful chunks. CocoIndex leverages Tree-sitter's capabilities to intelligently chunk code based on the actual syntax structure rather than arbitrary line breaks. These semantically coherent chunks are then used to build a more effective index for RAG systems, enabling more precise code retrieval and better context preservation.
Fast pass 🚀 - you can find the full code here. Only ~ 50 lines of Python code for the RAG pipeline, check it out 🤗!
Please give CocoIndex on Github a star to support us if you like our work. Thank you so much with a warm coconut hug 🥥🤗.

Prerequisites
If you don't have Postgres installed, please refer to the installation guide. CocoIndex uses Postgres to manage the data index, we have it on our roadmap to support other databases, including the in-progress ones. If you are interested in other databases, please let us know by creating a GitHub issue or Discord.
Define cocoIndex Flow
Let's define the cocoIndex flow to read from a codebase and index it for RAG.
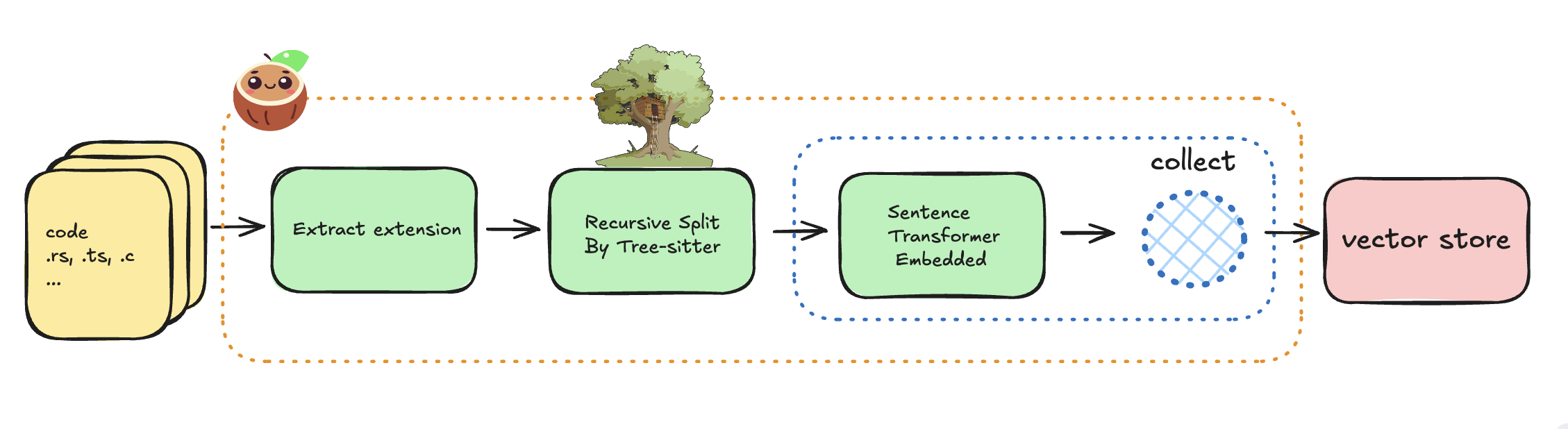
The flow diagram above illustrates how we'll process our codebase:
- Read code files from the local filesystem
- Extract file extensions
- Split code into semantic chunks using Tree-sitter
- Generate embeddings for each chunk
- Store in a vector database for retrieval
Let's implement this flow step by step.
1. Add the codebase as a source.
@cocoindex.flow_def(name="CodeEmbedding")
def code_embedding_flow(flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope):
"""
Define an example flow that embeds files into a vector database.
"""
data_scope["files"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="../..",
included_patterns=["*.py", "*.rs", "*.toml", "*.md", "*.mdx"],
excluded_patterns=[".*", "target", "**/node_modules"]))
code_embeddings = data_scope.add_collector()
In this example, we are going to index the cocoindex codebase from the root directory. You can change the path to the codebase you want to index. We will index all the files with the extensions of .py, .rs, .toml, .md, .mdx, and skip directories starting with ., target (in the root) and node_modules (under any directory).
flow_builder.add_source will create a table with the following sub fields, see documentation here.
filename(key, type:str): the filename of the file, e.g.dir1/file1.mdcontent(type:strifbinaryisFalse, otherwisebytes): the content of the file
2. Process each file and collect the information.
2.1 Extract the extension of a filename
First let's define a function to extract the extension of a filename while processing each file. You can find the documentation for custom function here.
@cocoindex.op.function()
def extract_extension(filename: str) -> str:
"""Extract the extension of a filename."""
return os.path.splitext(filename)[1]
Then we are going to process each file and collect the information.
# ...
with data_scope["files"].row() as file:
file["extension"] = file["filename"].transform(extract_extension)
Here we extract the extension of the filename and store it in the extension field. for example, if the filename is spec.rs, the extension field will be .rs.
2.2 Split the file into chunks
Next, we are going to split the file into chunks. We use the SplitRecursively function to split the file into chunks. You can find the documentation for the function here.
CocoIndex provides built-in support for Tree-sitter, so you can pass in the language to the language parameter.
To see all supported language names and extensions, see the documentation here. All the major languages are supported, e.g., Python, Rust, JavaScript, TypeScript, Java, C++, etc. If it's unspecified or the specified language is not supported, it will be treated as plain text.
with data_scope["files"].row() as file:
# ...
file["chunks"] = file["content"].transform(
cocoindex.functions.SplitRecursively(),
language=file["extension"], chunk_size=1000, chunk_overlap=300)
2.3 Embed the chunks
We will use the SentenceTransformerEmbed function to embed the chunks. You can find the documentation for the function here. There are 12k models supported by 🤗 Hugging Face. You can just pick your favorite model.
def code_to_embedding(text: cocoindex.DataSlice) -> cocoindex.DataSlice:
"""
Embed the text using a SentenceTransformer model.
"""
return text.transform(
cocoindex.functions.SentenceTransformerEmbed(
model="sentence-transformers/all-MiniLM-L6-v2"))
Then for each chunk, we will embed it using the code_to_embedding function. and collect the embeddings to the code_embeddings collector.
We extract this code_to_embedding function instead of directly calling transform(cocoindex.functions.SentenceTransformerEmbed(...)) in place.
This is because we want to make this one shared between the indexing flow building and the query handler definition. Alternatively, to make it simpler. It's also OK to avoid this extra function and directly do things in place - not a big deal to copy paste a little bit, we did this for the quickstart project.
with data_scope["files"].row() as file:
# ...
with file["chunks"].row() as chunk:
chunk["embedding"] = chunk["text"].call(code_to_embedding)
code_embeddings.collect(filename=file["filename"], location=chunk["location"],
code=chunk["text"], embedding=chunk["embedding"])
2.4 Collect the embeddings
Finally, let's export the embeddings to a table.
code_embeddings.export(
"code_embeddings",
cocoindex.storages.Postgres(),
primary_key_fields=["filename", "location"],
vector_index=[("embedding", cocoindex.VectorSimilarityMetric.COSINE_SIMILARITY)])
3. Setup Query Handler for your index
We will use the SimpleSemanticsQueryHandler to query the index. Note that we need to pass in the code_to_embedding function to the query_transform_flow parameter. This is because the query handler will use the same embedding model as the one used in the flow.
query_handler = cocoindex.query.SimpleSemanticsQueryHandler(
name="SemanticsSearch",
flow=code_embedding_flow,
target_name="code_embeddings",
query_transform_flow=code_to_embedding,
default_similarity_metric=cocoindex.VectorSimilarityMetric.COSINE_SIMILARITY)
Define a main function to run the query handler.
@cocoindex.main_fn()
def _run():
# Run queries in a loop to demonstrate the query capabilities.
while True:
try:
query = input("Enter search query (or Enter to quit): ")
if query == '':
break
results, _ = query_handler.search(query, 10)
print("\nSearch results:")
for result in results:
print(f"[{result.score:.3f}] {result.data['filename']}")
print(f" {result.data['code']}")
print("---")
print()
except KeyboardInterrupt:
break
if __name__ == "__main__":
load_dotenv(override=True)
_run()
The @cocoindex.main_fn() decorator initializes the library with settings loaded from environment variables. See documentation for initialization for more details.
Run the index setup & update
🎉 Now you are all set!
Run following commands to setup and update the index.
python main.py cocoindex setup
python main.py cocoindex update
You'll see the index updates state in the terminal

Test the query
At this point, you can start the cocoindex server and develop your RAG runtime agains the data.
To test your index, there are two options:
Option 1: Run the index server in the terminal
python main.py
When you see the prompt, you can enter your search query. for example: spec.
Enter search query (or Enter to quit): spec
You can find the search results in the terminal
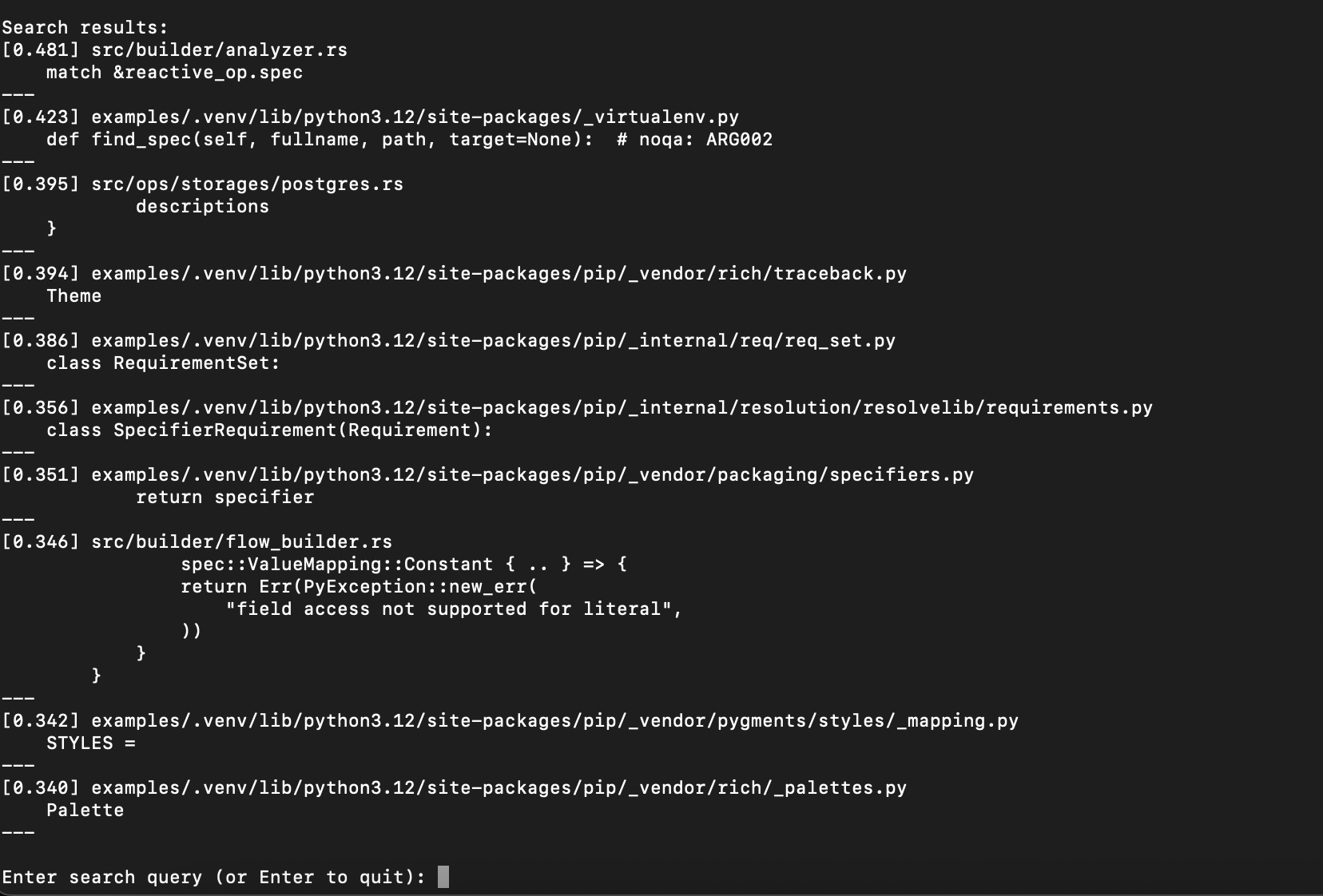
The returned results - each entry contains score (Cosine Similarity), filename, and the code snippet that get matched.
At cocoindex, we use the cocoindex.VectorSimilarityMetric.COSINE_SIMILARITY to measure the similarity between the query and the indexed data. You can switch to other metrics too and quickly test it out.
To learn more about Consine Similarity, see Wiki.
Option 2: Run CocoInsight to understand your data pipeline and data index
CocoInsight is a tool to help you understand your data pipeline and data index. It connects to your local CocoIndex server with zero data retention.
CocoInsight is in Early Access now (Free) 😊 You found us! A quick 3 minute video tutorial about CocoInsight: Watch on YouTube.
Run the CocoIndex server
python main.py cocoindex server -c https://cocoindex.io
Once the server is running, open CocoInsight in your browser. You'll be able to connect to your local CocoIndex server and explore your data pipeline and index.
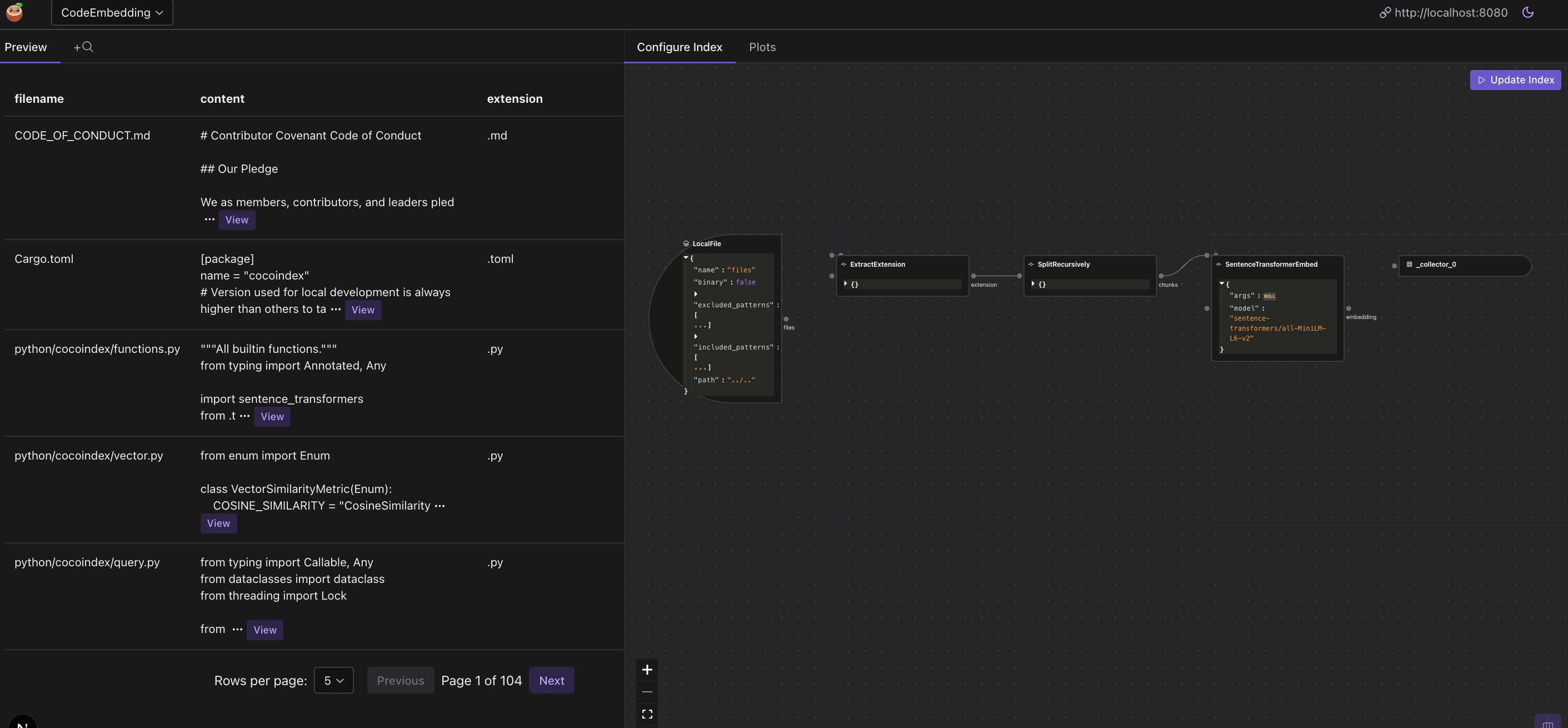
On the right side, you can see the data flow that we defined.
On the left side, you can see the data index in the data preview.
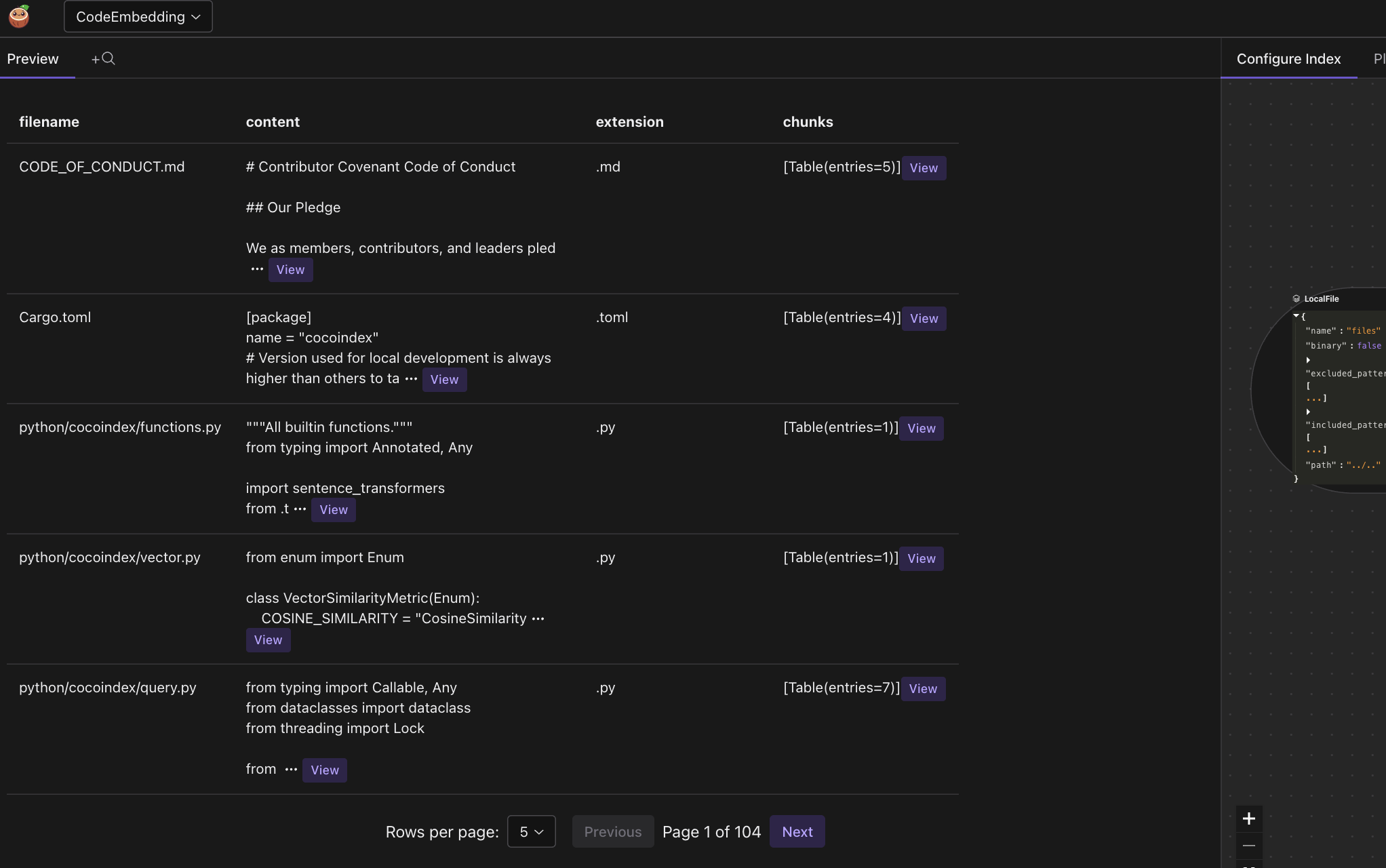
You can click on any row to see the details of that data entry, including the full content of code chunks and their embeddings.
To evaluate the performance of your index, you click the +search button on top and enter your query.
Community
We love to hear from the community! You can find us on Github and Discord.
If you like this post and our work, please support CocoIndex on Github with a star ⭐. Thank you with a warm coconut hug 🥥🤗.