Extract Structured Data from Python Manual markdowns with Ollama
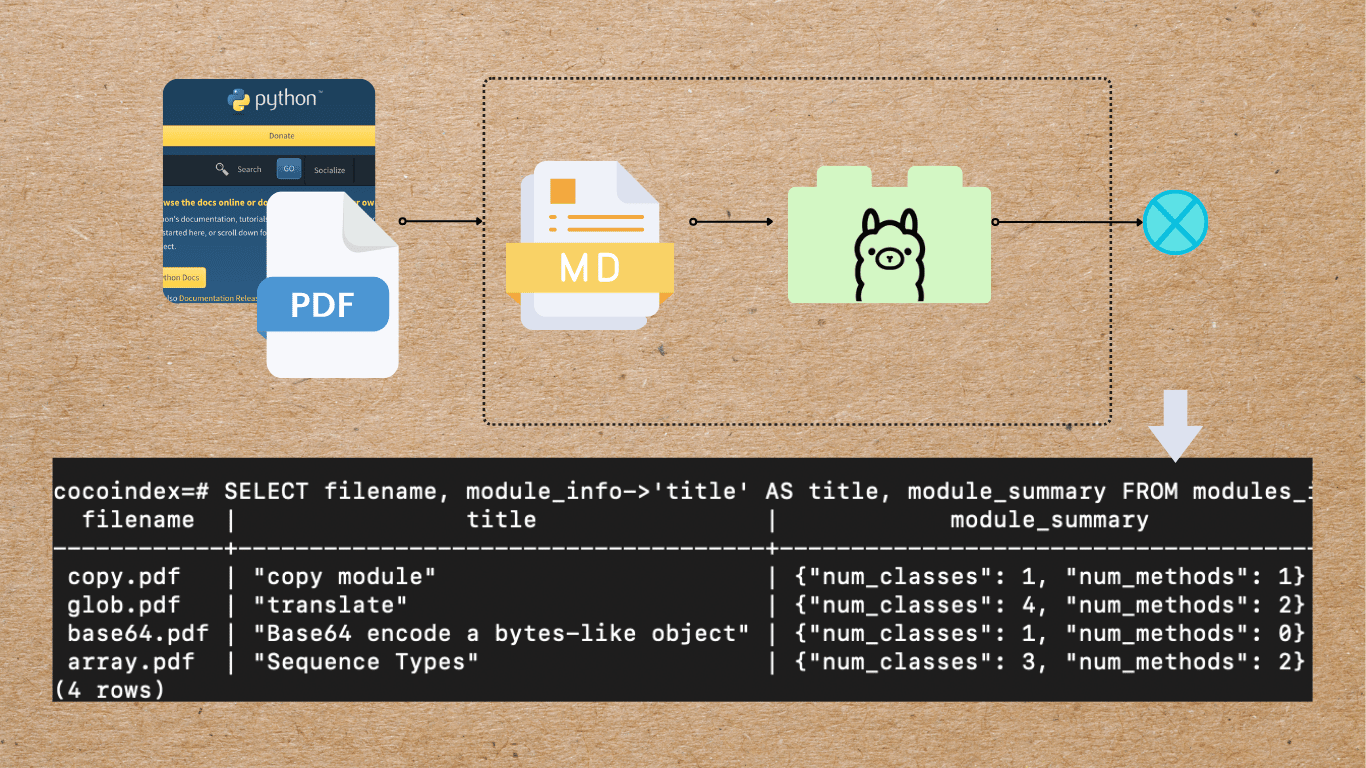
Overview
This example shows how to extract structured data from Python Manuals using Ollama.
Flow Overview
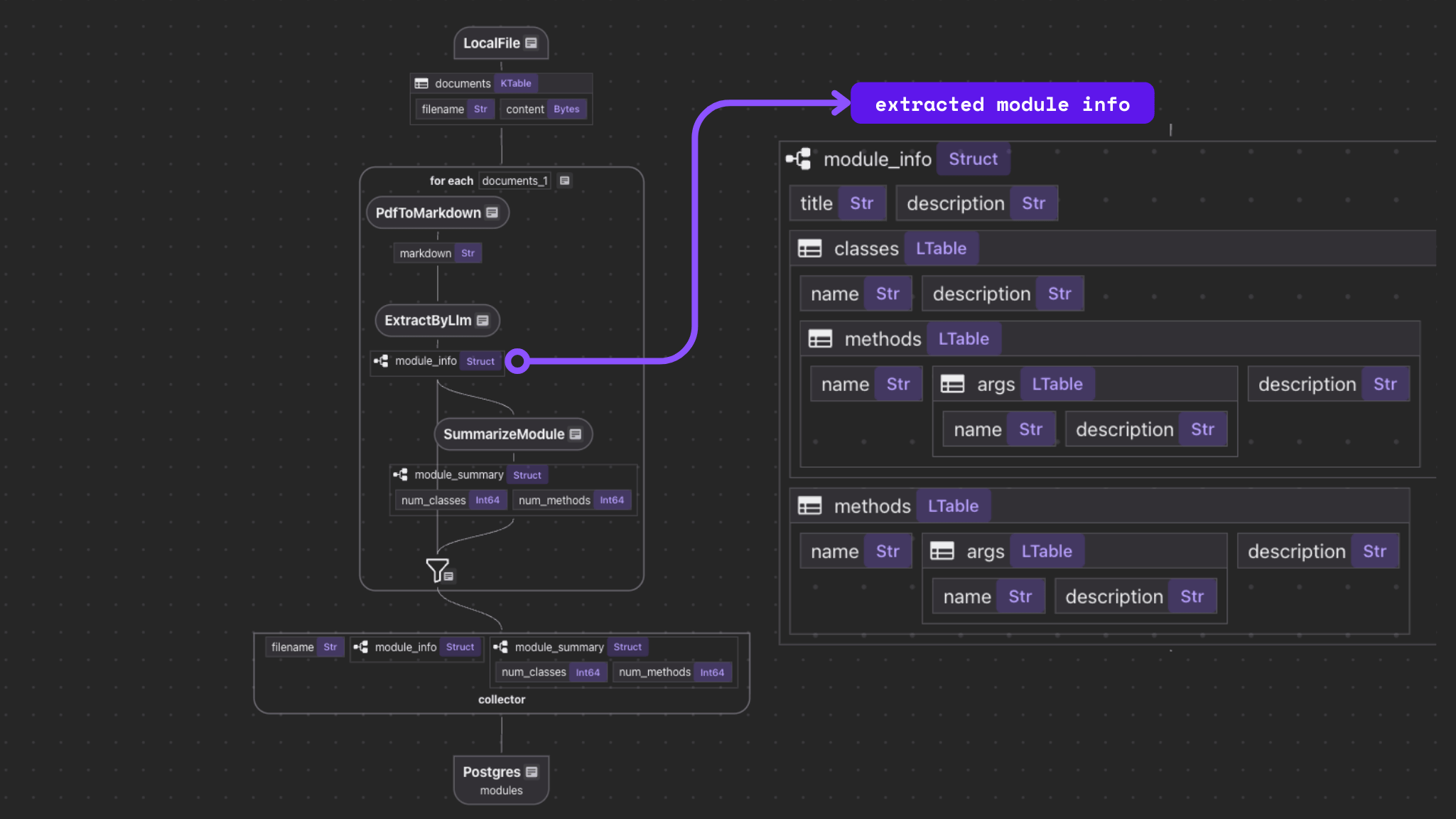
- For each PDF file:
- Parse to markdown.
- Extract structured data from the markdown using LLM.
- Add summary to the module info.
- Collect the data.
- Export the data to a table.
Prerequisites
-
If you don't have Postgres installed, please refer to the installation guide.
-
Download and install Ollama. Pull your favorite LLM models by:
Ollamaollama pull llama3.2Alternatively, CocoIndex have native support for Gemini, Ollama, LiteLLM. You can choose your favorite LLM provider and work completely on-premises.
LLM
Add Source
Let's add Python docs as a source.
@cocoindex.flow_def(name="ManualExtraction")
def manual_extraction_flow(
flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope
):
"""
Define an example flow that extracts manual information from a Markdown.
"""
data_scope["documents"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="manuals", binary=True)
)
modules_index = data_scope.add_collector()
flow_builder.add_source will create a table with the following sub fields:
filename(key, type:str): the filename of the file, e.g.dir1/file1.mdcontent(type:strifbinaryisFalse, otherwisebytes): the content of the file
Parse Markdown
To do this, we can plugin a custom function to convert PDF to markdown. There are so many different parsers commercially and open source available, you can bring your own parser here.
class PdfToMarkdown(cocoindex.op.FunctionSpec):
"""Convert a PDF to markdown."""
@cocoindex.op.executor_class(gpu=True, cache=True, behavior_version=1)
class PdfToMarkdownExecutor:
"""Executor for PdfToMarkdown."""
spec: PdfToMarkdown
_converter: PdfConverter
def prepare(self):
config_parser = ConfigParser({})
self._converter = PdfConverter(
create_model_dict(), config=config_parser.generate_config_dict()
)
def __call__(self, content: bytes) -> str:
with tempfile.NamedTemporaryFile(delete=True, suffix=".pdf") as temp_file:
temp_file.write(content)
temp_file.flush()
text, _, _ = text_from_rendered(self._converter(temp_file.name))
return text
You may wonder why we want to define a spec + executor (instead of using a standalone function) here. The main reason is there're some heavy preparation work (initialize the parser) needs to be done before being ready to process real data.
Custom FunctionPlug in the function to the flow.
with data_scope["documents"].row() as doc:
doc["markdown"] = doc["content"].transform(PdfToMarkdown())
It transforms each document to markdown.
Extract Structured Data from Markdown files
Define schema
Let's define the schema ModuleInfo using Python dataclasses, and we can pass it to the LLM to extract the structured data. It's easy to do this with CocoIndex.
@dataclasses.dataclass
class ArgInfo:
"""Information about an argument of a method."""
name: str
description: str
@dataclasses.dataclass
class MethodInfo:
"""Information about a method."""
name: str
args: cocoindex.typing.List[ArgInfo]
description: str
@dataclasses.dataclass
class ClassInfo:
"""Information about a class."""
name: str
description: str
methods: cocoindex.typing.List[MethodInfo]
@dataclasses.dataclass
class ModuleInfo:
"""Information about a Python module."""
title: str
description: str
classes: cocoindex.typing.List[ClassInfo]
methods: cocoindex.typing.List[MethodInfo]
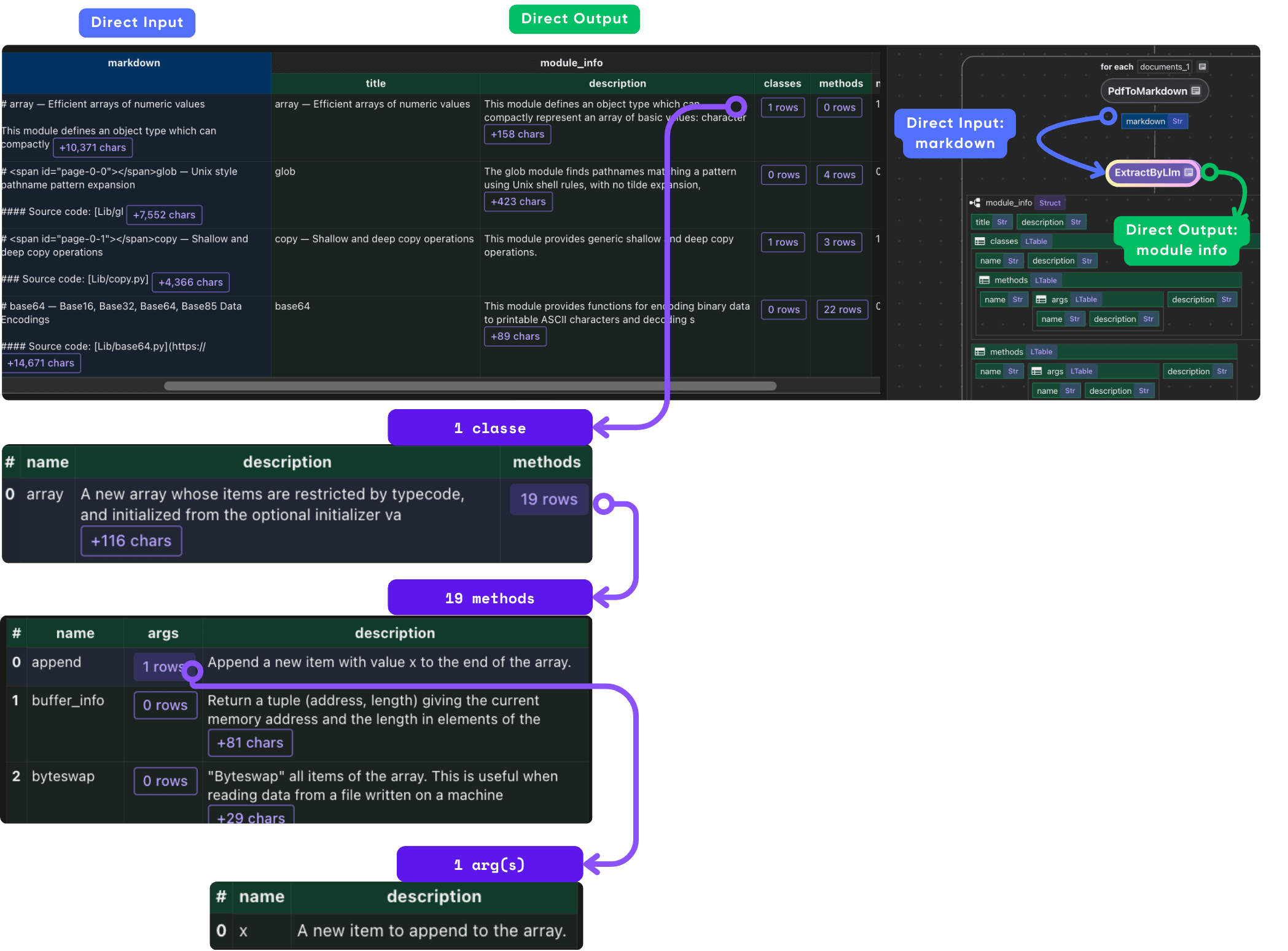
Extract structured data
CocoIndex provides builtin functions (e.g. ExtractByLlm) that process data using LLM. This example uses Ollama.
with data_scope["documents"].row() as doc:
doc["module_info"] = doc["content"].transform(
cocoindex.functions.ExtractByLlm(
llm_spec=cocoindex.LlmSpec(
api_type=cocoindex.LlmApiType.OLLAMA,
# See the full list of models: https://ollama.com/library
model="llama3.2"
),
output_type=ModuleInfo,
instruction="Please extract Python module information from the manual."))
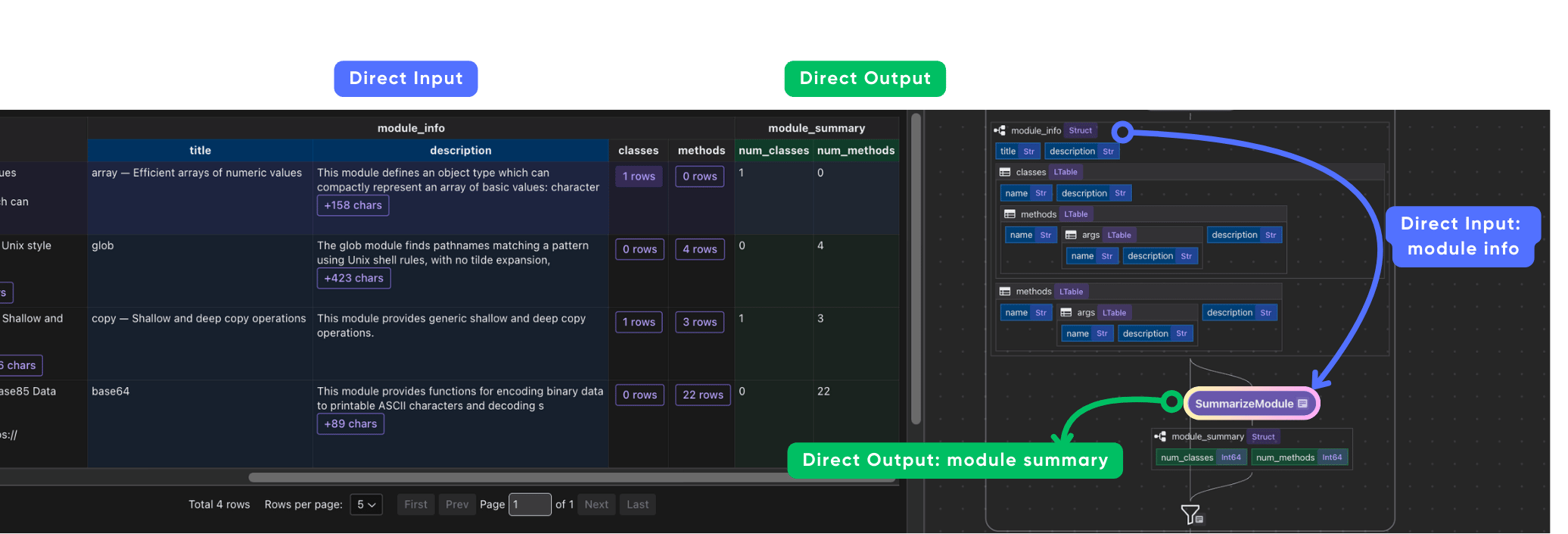
Add summarization to module info
Using CocoIndex as framework, you can easily add any transformation on the data, and collect it as part of the data index. Let's add some simple summary to each module - like number of classes and methods, using simple Python function.
Define Schema
@dataclasses.dataclass
class ModuleSummary:
"""Summary info about a Python module."""
num_classes: int
num_methods: int
A simple custom function to summarize the data
@cocoindex.op.function()
def summarize_module(module_info: ModuleInfo) -> ModuleSummary:
"""Summarize a Python module."""
return ModuleSummary(
num_classes=len(module_info.classes),
num_methods=len(module_info.methods),
)
Plug in the function into the flow
with data_scope["documents"].row() as doc:
# ... after the extraction
doc["module_summary"] = doc["module_info"].transform(summarize_module)
Collect the data
After the extraction, we need to cherrypick anything we like from the output using the collect function from the collector of a data scope defined above.
modules_index.collect(
filename=doc["filename"],
module_info=doc["module_info"],
)
Finally, let's export the extracted data to a table.
modules_index.export(
"modules",
cocoindex.storages.Postgres(table_name="modules_info"),
primary_key_fields=["filename"],
)
Query and test your index
Run the following command to setup and update the index.
cocoindex update -L main.py
You'll see the index updates state in the terminal
After the index is built, you have a table with the name modules_info. You can query it at any time, e.g., start a Postgres shell:
psql postgres://cocoindex:cocoindex@localhost/cocoindex
And run the SQL query:
SELECT filename, module_info->'title' AS title, module_summary FROM modules_info;
CocoInsight
CocoInsight is a really cool tool to help you understand your data pipeline and data index. It is in Early Access now (Free).
cocoindex server -ci main
CocoInsight dashboard is here https://cocoindex.io/cocoinsight. It connects to your local CocoIndex server with zero data retention.