Photo Search with Face Detection

Overview
We’ll walk through a comprehensive example of building a scalable face recognition pipeline. We’ll
- Detect all faces in the image and extract their bounding boxes
- Crop and encode each face image into a 128-dimensional face embedding
- Store metadata and vectors in a structured index to support queries like: “Find all similar faces to this one” or “Search images that include this person”
With this, you can build your own photo search app with face detection and search.
Flow Overview
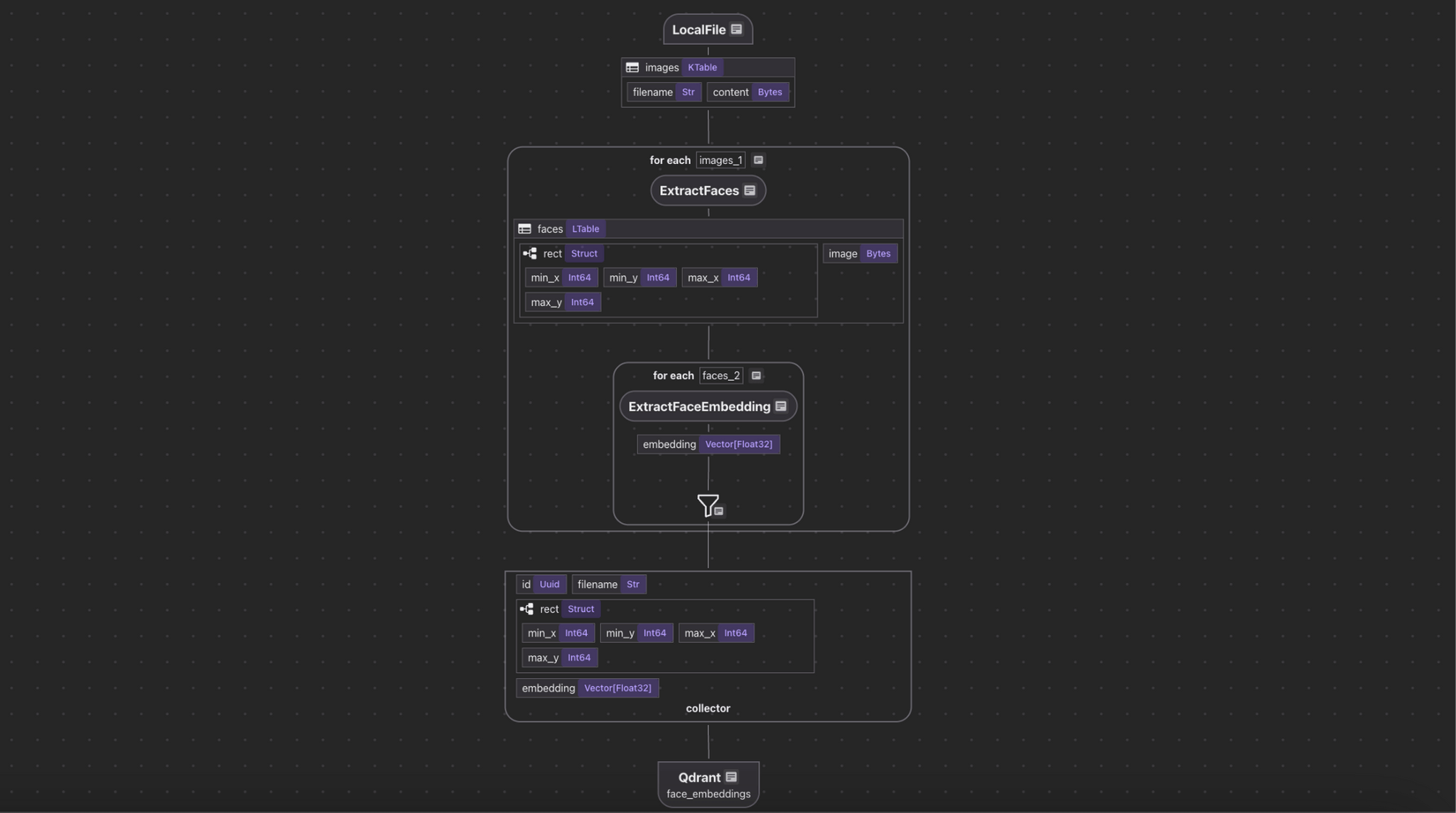
- Ingest the images.
- For each image,
- Extract faces from the image.
- Compute embeddings for each face.
- Export following fields to a table in Postgres with PGVector:
- Filename, rect, embedding for each face.
Setup
-
Install Postgres if you don't have one.
-
Install Qdrant
docker run -d -p 6334:6334 -p 6333:6333 qdrant/qdrant -
Install dependencies:
pip install -e .
Add source
We monitor an images/ directory using the built-in LocalFile source. All newly added files are automatically processed and indexed.
@cocoindex.flow_def(name="FaceRecognition")
def face_recognition_flow(flow_builder, data_scope):
data_scope["images"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="images", binary=True),
refresh_interval=datetime.timedelta(seconds=10),
)
This creates a table with filename and content fields. 📂
You can connect it to your S3 Buckets (with SQS integration, example) or Azure Blob store.
Detect and Extract Faces
We use the face_recognition library under the hood, powered by dlib’s CNN-based face detector. Since the model is slow on large images, we downscale wide images before detection.
@cocoindex.op.function(
cache=True,
behavior_version=1,
gpu=True,
arg_relationship=(cocoindex.op.ArgRelationship.RECTS_BASE_IMAGE, "content"),
)
def extract_faces(content: bytes) -> list[FaceBase]:
orig_img = Image.open(io.BytesIO(content)).convert("RGB")
# The model is too slow on large images, so we resize them if too large.
if orig_img.width > MAX_IMAGE_WIDTH:
ratio = orig_img.width * 1.0 / MAX_IMAGE_WIDTH
img = orig_img.resize(
(MAX_IMAGE_WIDTH, int(orig_img.height / ratio)),
resample=Image.Resampling.BICUBIC,
)
else:
ratio = 1.0
img = orig_img
# Extract face locations.
locs = face_recognition.face_locations(np.array(img), model="cnn")
faces: list[FaceBase] = []
for min_y, max_x, max_y, min_x in locs:
rect = ImageRect(
min_x=int(min_x * ratio),
min_y=int(min_y * ratio),
max_x=int(max_x * ratio),
max_y=int(max_y * ratio),
)
# Crop the face and save it as a PNG.
buf = io.BytesIO()
orig_img.crop((rect.min_x, rect.min_y, rect.max_x, rect.max_y)).save(
buf, format="PNG"
)
face = buf.getvalue()
faces.append(FaceBase(rect, face))
return faces
We transform the image content:
with data_scope["images"].row() as image:
image["faces"] = image["content"].transform(extract_faces)
After this step, each image has a list of detected faces and bounding boxes. Each detected face is cropped from the original image and stored as a PNG.
Compute Face Embeddings
We encode each cropped face using the same library. This generates a 128-dimensional vector representation per face.
@cocoindex.op.function(cache=True, behavior_version=1, gpu=True)
def extract_face_embedding(
face: bytes,
) -> cocoindex.Vector[cocoindex.Float32, typing.Literal[128]]:
"""Extract the embedding of a face."""
img = Image.open(io.BytesIO(face)).convert("RGB")
embedding = face_recognition.face_encodings(
np.array(img),
known_face_locations=[(0, img.width - 1, img.height - 1, 0)],
)[0]
return embedding
We plug the embedding function into the flow:
with image["faces"].row() as face:
face["embedding"] = face["image"].transform(extract_face_embedding)
After this step, we have embeddings ready to be indexed!
Collect and Export Embeddings
We now collect structured data for each face: filename, bounding box, and embedding.
face_embeddings = data_scope.add_collector()
face_embeddings.collect(
id=cocoindex.GeneratedField.UUID,
filename=image["filename"],
rect=face["rect"],
embedding=face["embedding"],
)
We export to a Qdrant collection:
face_embeddings.export(
QDRANT_COLLECTION,
cocoindex.targets.Qdrant(
collection_name=QDRANT_COLLECTION
),
primary_key_fields=["id"],
)
Now you can run cosine similarity queries over facial vectors.
CocoIndex supports 1-line switch with other vector databases.
PostgresQuery the Index
You can now build facial search apps or dashboards. For example:
- Given a new face embedding, find the most similar faces
- Find all face images that appear in a set of photos
- Cluster embeddings to group visually similar people
For querying embeddings, check out Image Search project.
If you’d like to see a full example on the query path with image match, give it a shout at our group.
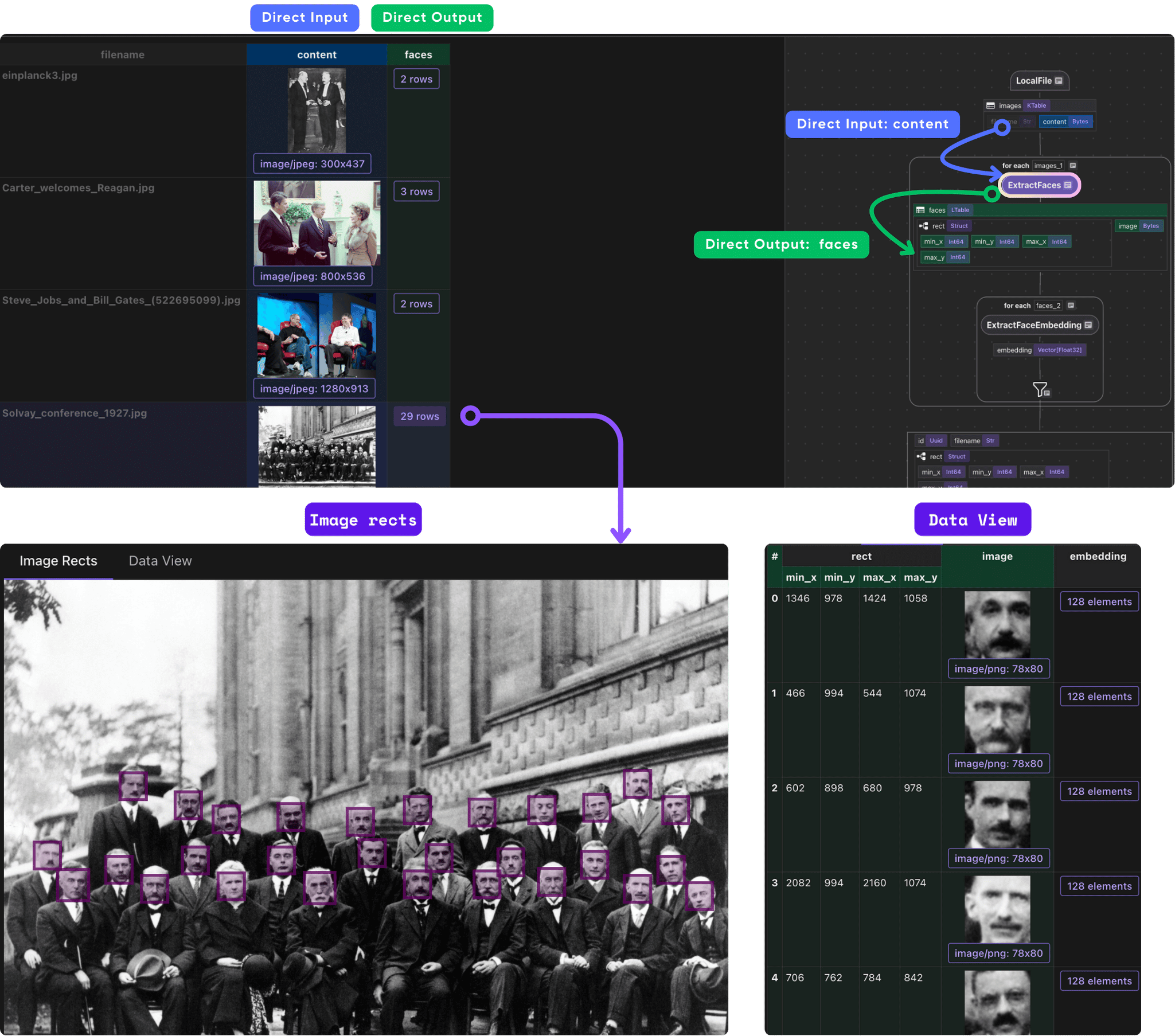
CocoInsight
CocoInsight is a tool to help you understand your data pipeline and data index. It can now visualize identified sections of an image based on the bounding boxes and makes it easier to understand and evaluate AI extractions - seamlessly attaching computed features in the context of unstructured visual data.
You can walk through the project step by step in CocoInsight to see exactly how each field is constructed and what happens behind the scenes.
cocoindex server -ci main
Follow the url https://cocoindex.io/cocoinsight. It connects to your local CocoIndex server, with zero pipeline data retention.