Bring your own parser as building block with Google Document AI
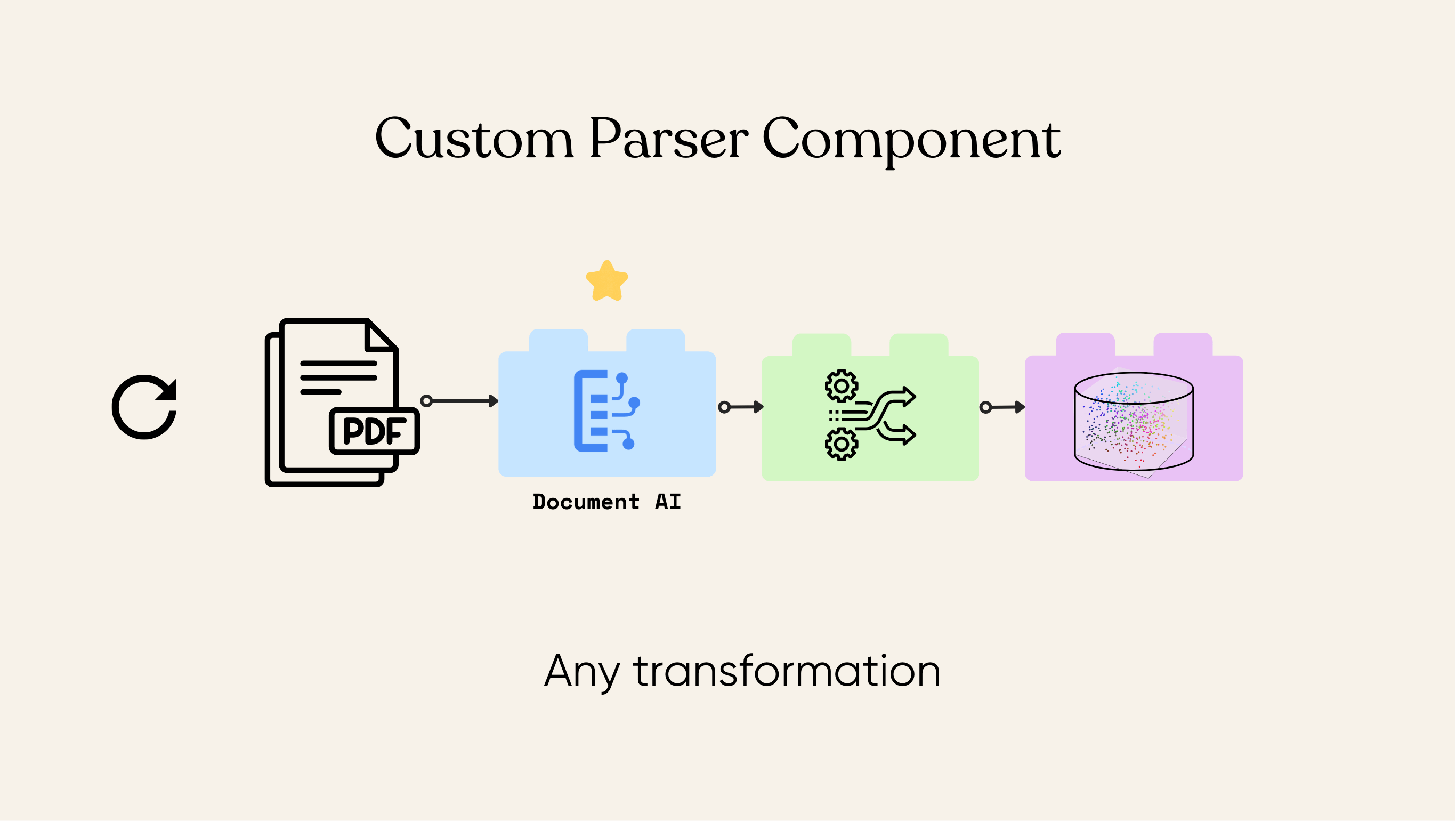
CocoIndex is a flexible ETL framework with incremental processing. We don’t build parser ourselves, and users can bring in any open source or commercial parser that works best for their scenarios. In this example, we show how to use Google Document AI to parse document, embed the resulting text, and store it in a vectorized database for semantic search.
Set up
- Install Postgres if you don't have one.
- Configure Project and Processor ID for Document AI API
- Official Google document AI API with free live demo.
- Sign in to Google Cloud Console, create or open a project, and enable Document AI API.
- update
.envwithGOOGLE_CLOUD_PROJECT_IDandGOOGLE_CLOUD_PROCESSOR_ID.
Create Your building block to convert PDFs to Markdown
We define a ToMarkdown custom function spec, which leverages Google Document AI to parse PDF content:
class ToMarkdown(cocoindex.op.FunctionSpec):
"""Convert a PDF to markdown using Google Document AI."""
The corresponding executor class handles API initialization and parsing logic:
@cocoindex.op.executor_class(cache=True, behavior_version=1)
class DocumentAIExecutor:
"""Executor for Google Document AI to parse PDF files."""
spec: ToMarkdown
_client: documentai.DocumentProcessorServiceClient
_processor_name: str
def prepare(self):
# Initialize the Document AI client
project_id = os.environ.get("GOOGLE_CLOUD_PROJECT_ID")
location = os.environ.get("GOOGLE_CLOUD_LOCATION", "us")
processor_id = os.environ.get("GOOGLE_CLOUD_PROCESSOR_ID")
opts = ClientOptions(api_endpoint=f"{location}-documentai.googleapis.com")
self._client = documentai.DocumentProcessorServiceClient(client_options=opts)
self._processor_name = self._client.processor_path(project_id, location, processor_id)
async def __call__(self, content: bytes) -> str:
"""Parse PDF content and convert to markdown text."""
request = documentai.ProcessRequest(
name=self._processor_name,
raw_document=documentai.RawDocument(content=content, mime_type="application/pdf")
)
response = self._client.process_document(request=request)
return response.document.text
Make sure you configure the cache and behavior_version parameters for heavy operations like this.
-
cache: Whether the executor will enable cache for this function. When True, the executor will cache the result of the function for reuse during reprocessing. We recommend to set this to True for any function that is computationally intensive. -
behavior_version: The version of the behavior of the function. When the version is changed, the function will be re-executed even if cache is enabled. It's required to be set if cache is True.
Define the flow
@cocoindex.flow_def(name="DocumentAiPdfEmbedding")
def pdf_embedding_flow(flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope):
# flow definition
Add source & collector
data_scope["documents"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="pdf_files", binary=True)
)
doc_embeddings = data_scope.add_collector()
Process each document
with data_scope["documents"].row() as doc:
doc["markdown"] = doc["content"].transform(ToMarkdown())
doc["chunks"] = doc["markdown"].transform(
cocoindex.functions.SplitRecursively(),
language="markdown",
chunk_size=2000,
chunk_overlap=500
)
with doc["chunks"].row() as chunk:
chunk["embedding"] = chunk["text"].call(text_to_embedding)
doc_embeddings.collect(
id=cocoindex.GeneratedField.UUID,
filename=doc["filename"],
location=chunk["location"],
text=chunk["text"],
embedding=chunk["embedding"]
)
- Convert them to Markdown using Document AI.
- Split the Markdown into chunks.
- Embed each chunk.
Export to Postgres
doc_embeddings.export(
"doc_embeddings",
cocoindex.storages.Postgres(),
primary_key_fields=["id"],
vector_indexes=[
cocoindex.VectorIndexDef(
field_name="embedding",
metric=cocoindex.VectorSimilarityMetric.COSINE_SIMILARITY
)
]
)
End to End Example
For a step-by-step walkthrough of each indexing stage and the query path, check out this example:
Simple Vector IndexOther sources
CocoIndex natively supports Google Drive, Amazon S3, Azure Blob Storage, and more with native incremental processing out of box - when new or updated files are detected, the pipeline will capture the changes and only process what's changed.
Sources