
Entire captures every AI coding session you run — the full conversation transcript, the prompt you started from, an AI-written context summary, and metadata like token counts and files touched — as checkpoints on disk. We’ll take that folder of checkpoints and turn it into a vector index you can search in plain English: “how did I fix the auth bug” finds the right session even when it shares no keywords with what you typed.
The whole pipeline is ordinary async Python and your own types. The heavy lifting — incremental processing, change tracking, managed targets — runs in a Rust engine underneath, so each new session you capture only embeds what changed, and every kind of checkpoint file is parsed by the same process_file component.
Flow overview
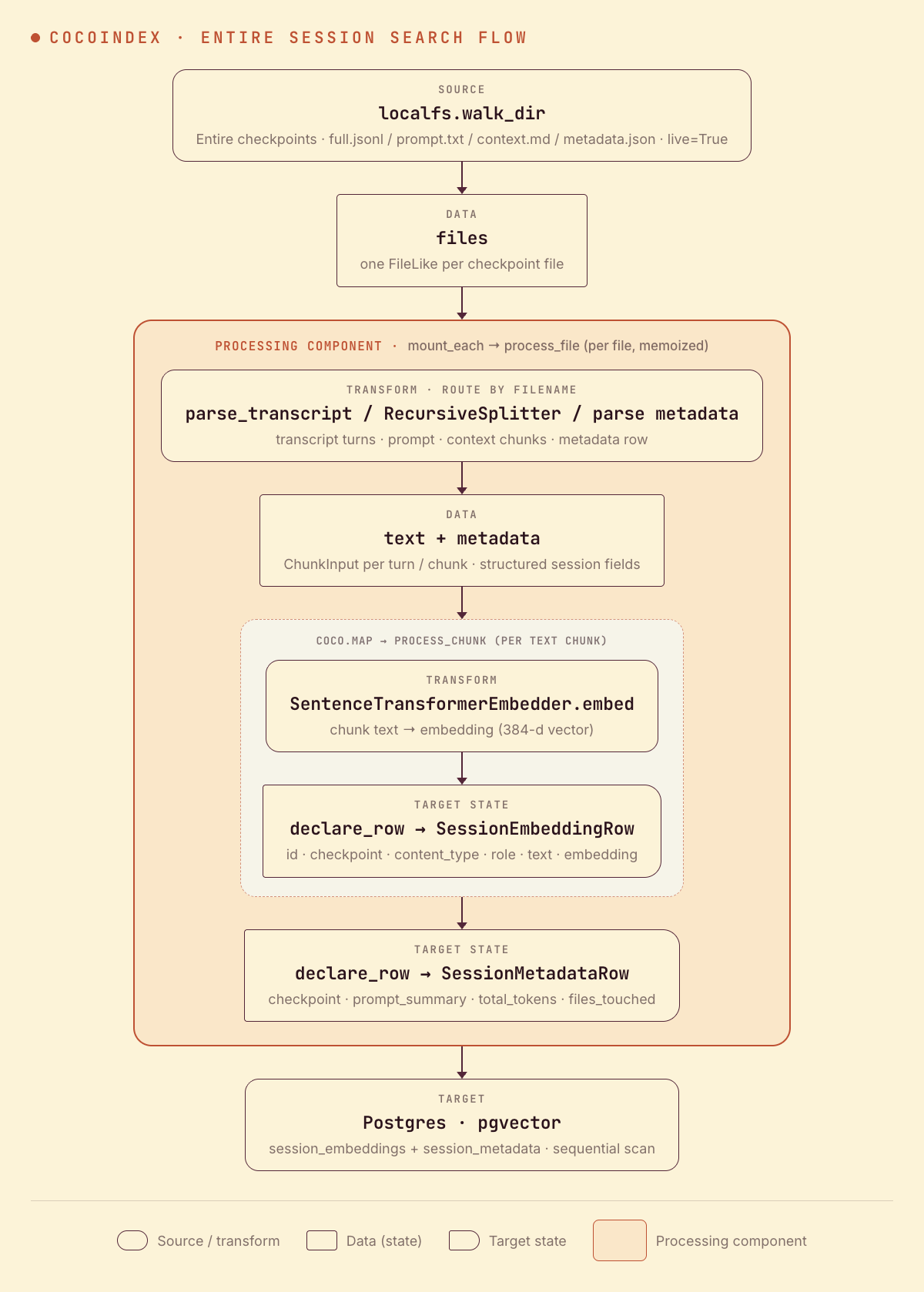
From a high level, these are the steps:
- Read Entire checkpoint files from a local directory (live).
- Route each file by name: parse
full.jsonlinto per-turn transcript chunks, takeprompt.txtwhole, splitcontext.mdinto overlapping chunks, then embed the text — whilemetadata.jsonbecomes a structured row. - Store the embeddings and metadata in two Postgres tables (as target states).
You declare the transformation logic with native Python, without worrying about how updates propagate. Think: target_state = transformation(source_state).
New to embeddings? An embedding is a list of numbers (a vector) that captures the meaning of a piece of text, so passages with similar meaning land close together in vector space. A vector index stores those vectors and finds the nearest ones to your query fast. That’s what lets search match by meaning instead of exact words.
Setup
-
A running Postgres with the pgvector extension. The repo ships a compose file:
docker compose -f dev/postgres.yaml up -d export POSTGRES_URL="postgres://cocoindex:cocoindex@localhost/cocoindex" -
Install CocoIndex and the dependencies this example uses:
pip install -U "cocoindex[postgres,sentence_transformers]" asyncpg pgvector numpy python-dotenv -
Some Entire checkpoints to index. From any repo where Entire is capturing sessions, check the checkpoint data out next to the example:
git worktree add entire_checkpoints entire/checkpoints/v1Each session is laid out as
<checkpoint_id[:2]>/<checkpoint_id[2:]>/<session_idx>/withfull.jsonl(transcript),prompt.txt(initial prompt),context.md(AI-written summary), andmetadata.json(token counts, files touched).
Define the data and shared resources
Each row of the embeddings table is one searchable piece of text — a transcript turn, a prompt, or a context chunk — tagged with its content_type, role, and the session it came from. The metadata table keeps one row per session for the structured fields. coco_lifespan provides the shared resources every step needs — the Postgres connection pool and the embedding model — once at startup.
EMBED_MODEL = "sentence-transformers/all-MiniLM-L6-v2"
PG_DB = coco.ContextKey[asyncpg.Pool]("entire_session_db")
EMBEDDER = coco.ContextKey[SentenceTransformerEmbedder]("embedder", detect_change=True)
_splitter = RecursiveSplitter()
@dataclass
class SessionEmbeddingRow:
id: int
checkpoint_id: str
session_index: str
content_type: str # "transcript", "prompt", or "context"
role: str # "user", "assistant", or "" for non-transcript
text: str
embedding: Annotated[NDArray, EMBEDDER]
@dataclass
class SessionMetadataRow:
checkpoint_id: str
session_index: str
prompt_summary: str
total_tokens: int
files_touched: str # JSON array
agent_percentage: float | None
@coco.lifespan
async def coco_lifespan(builder: coco.EnvironmentBuilder) -> AsyncIterator[None]:
async with asyncpg.create_pool(DATABASE_URL) as pool:
builder.provide(PG_DB, pool)
builder.provide(EMBEDDER, SentenceTransformerEmbedder(EMBED_MODEL))
yieldembedding: Annotated[NDArray, EMBEDDER] ties the vector column to the embedder, so its dimensions are inferred automatically — and if you swap the model later, CocoIndex notices (detect_change=True) and re-embeds.
Process a file
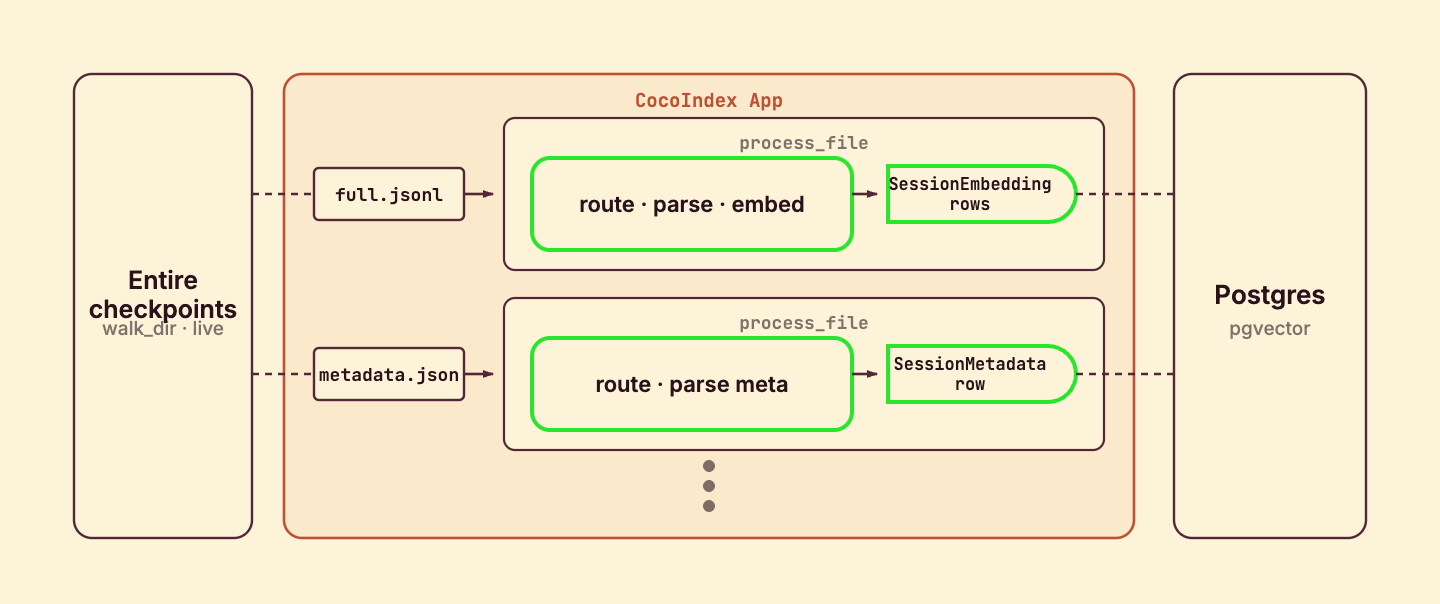
process_file runs once per checkpoint file and routes on its name. The checkpoint id and session index come straight from the file’s path, and a fresh IdGenerator numbers the rows this file produces.
@coco.fn(memo=True)
async def process_file(
file: FileLike,
emb_table: postgres.TableTarget[SessionEmbeddingRow],
meta_table: postgres.TableTarget[SessionMetadataRow],
) -> None:
info = extract_session_info(file)
filename = file.file_path.path.name
id_gen = IdGenerator()
if filename == "full.jsonl":
content = await file.read_text()
chunks = parse_transcript(content)
await coco.map(
process_chunk,
[
ChunkInput(text=c.text, content_type="transcript", role=c.role)
for c in chunks
],
info, id_gen, emb_table,
)
elif filename == "prompt.txt":
text = (await file.read_text()).strip()
if text:
emb_table.declare_row(
row=SessionEmbeddingRow(
id=await id_gen.next_id(text),
checkpoint_id=info.checkpoint_id,
session_index=info.session_index,
content_type="prompt",
role="user",
text=text,
embedding=await coco.use_context(EMBEDDER).embed(text),
),
)
elif filename == "context.md":
text = (await file.read_text()).strip()
if text:
chunks = _splitter.split(
text, chunk_size=2000, chunk_overlap=500, language="markdown"
)
await coco.map(
process_chunk,
[
ChunkInput(text=c.text, content_type="context", role="")
for c in chunks
],
info, id_gen, emb_table,
)
elif filename == "metadata.json":
meta = json.loads(await file.read_text())
usage = meta.get("token_usage", {})
agent_pct = meta.get("initial_attribution", {}).get("agent_percentage")
meta_table.declare_row(
row=SessionMetadataRow(
checkpoint_id=info.checkpoint_id,
session_index=info.session_index,
prompt_summary=meta.get("summary", {}).get("intent", ""),
total_tokens=(usage.get("input_tokens") or 0) + (usage.get("output_tokens") or 0),
files_touched=json.dumps(meta.get("files_touched", [])),
agent_percentage=float(agent_pct) if agent_pct is not None else None,
),
)The transcript and the context summary each fan out to many rows, so they map to process_chunk; the prompt is a single short string, so it’s embedded inline; and the metadata file declares one row directly into the other table — three content types and a structured record, all from one component.
@coco.fn with memo=True is what makes this incremental: if a file’s content and this function’s code are both unchanged, it’s skipped on the next run, so finished sessions are never re-embedded. coco.map fans out to one process_chunk call per chunk.
Process a chunk
process_chunk embeds one piece of text with the shared embedder and declares the target row. Both the transcript and the context paths funnel through it, carrying their own content_type and role.
@coco.fn
async def process_chunk(
chunk: ChunkInput,
info: SessionInfo,
id_gen: IdGenerator,
emb_table: postgres.TableTarget[SessionEmbeddingRow],
) -> None:
emb_table.declare_row(
row=SessionEmbeddingRow(
id=await id_gen.next_id(chunk.text),
checkpoint_id=info.checkpoint_id,
session_index=info.session_index,
content_type=chunk.content_type,
role=chunk.role,
text=chunk.text,
embedding=await coco.use_context(EMBEDDER).embed(chunk.text),
),
)We use SentenceTransformerEmbedder with all-MiniLM-L6-v2 — a small, fast model that runs locally with no API key. There are 12k+ sentence-transformer models on Hugging Face, so swap in whichever you prefer. emb_table.declare_row declares the row as a target state; CocoIndex handles inserting, updating, or deleting it to match. Each row’s id is derived from the chunk text, so a turn that survives a re-parse keeps its row.
Define the main function
app_main wires the source to the targets. It mounts both Postgres tables, walks the checkpoint directory for the four file types, and mounts one processing component per file.
@coco.fn
async def app_main(checkpoints_dir: pathlib.Path) -> None:
emb_table = await postgres.mount_table_target(
PG_DB,
table_name=TABLE_EMBEDDINGS,
table_schema=await postgres.TableSchema.from_class(
SessionEmbeddingRow, primary_key=["id"],
),
pg_schema_name=PG_SCHEMA_NAME, # "entire"
)
meta_table = await postgres.mount_table_target(
PG_DB,
table_name=TABLE_METADATA,
table_schema=await postgres.TableSchema.from_class(
SessionMetadataRow, primary_key=["checkpoint_id", "session_index"],
),
pg_schema_name=PG_SCHEMA_NAME,
)
files = localfs.walk_dir(
checkpoints_dir,
recursive=True,
path_matcher=PatternFilePathMatcher(
included_patterns=[
"**/full.jsonl", "**/prompt.txt",
"**/context.md", "**/metadata.json",
],
),
live=True, # watch for changes; pass -L to `cocoindex update` to run live
)
await coco.mount_each(process_file, files.items(), emb_table, meta_table)
app = coco.App(
coco.AppConfig(name="EntireSessionSearch"),
app_main,
checkpoints_dir=pathlib.Path("./entire_checkpoints"),
)mount_table_target creates and manages each Postgres table for you — schema, idempotent upserts, and orphan cleanup when a session disappears. The included_patterns are what makes one component handle four different files: every match flows through the same process_file, which routes on the name. live=True makes the filesystem source watch for changes, and mount_each runs one component per file so the engine can track and update them independently.
No vector index here. To keep the example minimal, this flow doesn’t declare a vector index, so queries do a sequential scan — fine for a personal session history. For a larger corpus, add one line —
emb_table.declare_vector_index(column="embedding")— exactly as the Semantic Search 101 example does, and pgvector serves approximate-nearest-neighbor queries instead.
Run the pipeline
Run the cocoindex CLI to build and update the index. Choose catch-up (scan, sync, exit) or live (catch up, then keep watching):
# Catch-up run
cocoindex update main
# Live run: keep watching for new sessions
cocoindex update -L mainQuery the index
Match user text against the index with a plain SQL query, reusing the same embedder from the indexing flow so indexing and querying stay consistent.
async def query_once(pool, embedder, query: str, *, top_k: int = 5) -> None:
query_vec = await embedder.embed(query)
async with pool.acquire() as conn:
rows = await conn.fetch(
f"""
SELECT checkpoint_id, session_index, content_type, role, text,
embedding <=> $1 AS distance
FROM "{PG_SCHEMA_NAME}"."{TABLE_EMBEDDINGS}"
ORDER BY distance ASC
LIMIT $2
""",
query_vec, top_k,
)
for r in rows:
score = 1.0 - float(r["distance"])
tag = r["content_type"] + (f"/{r['role']}" if r["role"] else "")
print(f"[{score:.3f}] {r['checkpoint_id']}/{r['session_index']} ({tag})")
print(f" {r['text'][:200]}")
print("---")The <=> operator is pgvector’s cosine distance. We turn it into a similarity score and print which session and content type matched, so a transcript turn, a prompt, and a context chunk are all distinguishable in the results. Run a search straight from the command line:
python main.py "how did I fix the auth bug"The most semantically similar sessions come back ranked — even when they share none of the words in your query. That’s the whole point of a vector index.
Incremental updates
CocoIndex keeps the index in sync with your sessions and does the minimum work to get there. You never compute a diff or write update logic. Two pieces make this work. @coco.fn(memo=True) decides what to recompute — a file is skipped when its content and the function’s code are both unchanged, so a finished session is never re-embedded. mount_table_target decides what to write — each embedding row’s id is derived from its text, so it upserts only the rows that actually changed and deletes rows whose source is gone.
- A new session is captured — only its files are parsed, chunked, and embedded; their rows are inserted. Everything already indexed is untouched.
- A session is updated — its files are re-routed and re-chunked; turns whose text is unchanged keep their
idand embedding, genuinely new turns are embedded and inserted, and turns that no longer exist are deleted. - A session is removed — its embedding and metadata rows are removed from both tables automatically.
The same machinery covers logic changes too: tune the chunk size or swap the embedding model, and CocoIndex compares the new output against what’s already in Postgres and applies only the difference. A catch-up run (cocoindex update main) does this once and exits; live mode (cocoindex update -L main) keeps watching and applies each new session with low latency.
Run it
The full, runnable example is in the CocoIndex repo: examples/entire_session_search. If your inputs are plain text or Markdown rather than session checkpoints, Semantic Search 101 is the same flow without the per-file routing; to search a folder of PDFs, see Semantic Search over PDFs.
Want to search your own AI coding history by meaning? Come tell us on Discord — and if this was useful, star CocoIndex on GitHub.