A slide deck is a great outline and a terrible thing to listen to or search. In this tutorial we’ll build a CocoIndex pipeline that fixes both: for each slide, a vision LLM writes natural speaker notes, Piper synthesizes them to audio locally, and the notes are embedded into LanceDB so you can search the deck by meaning and play back the narration for any hit.
The whole pipeline is ordinary async Python. The vision and TTS steps run on a GPU runner, and the Rust engine handles incremental processing — add a deck and only its slides get processed.
Flow overview
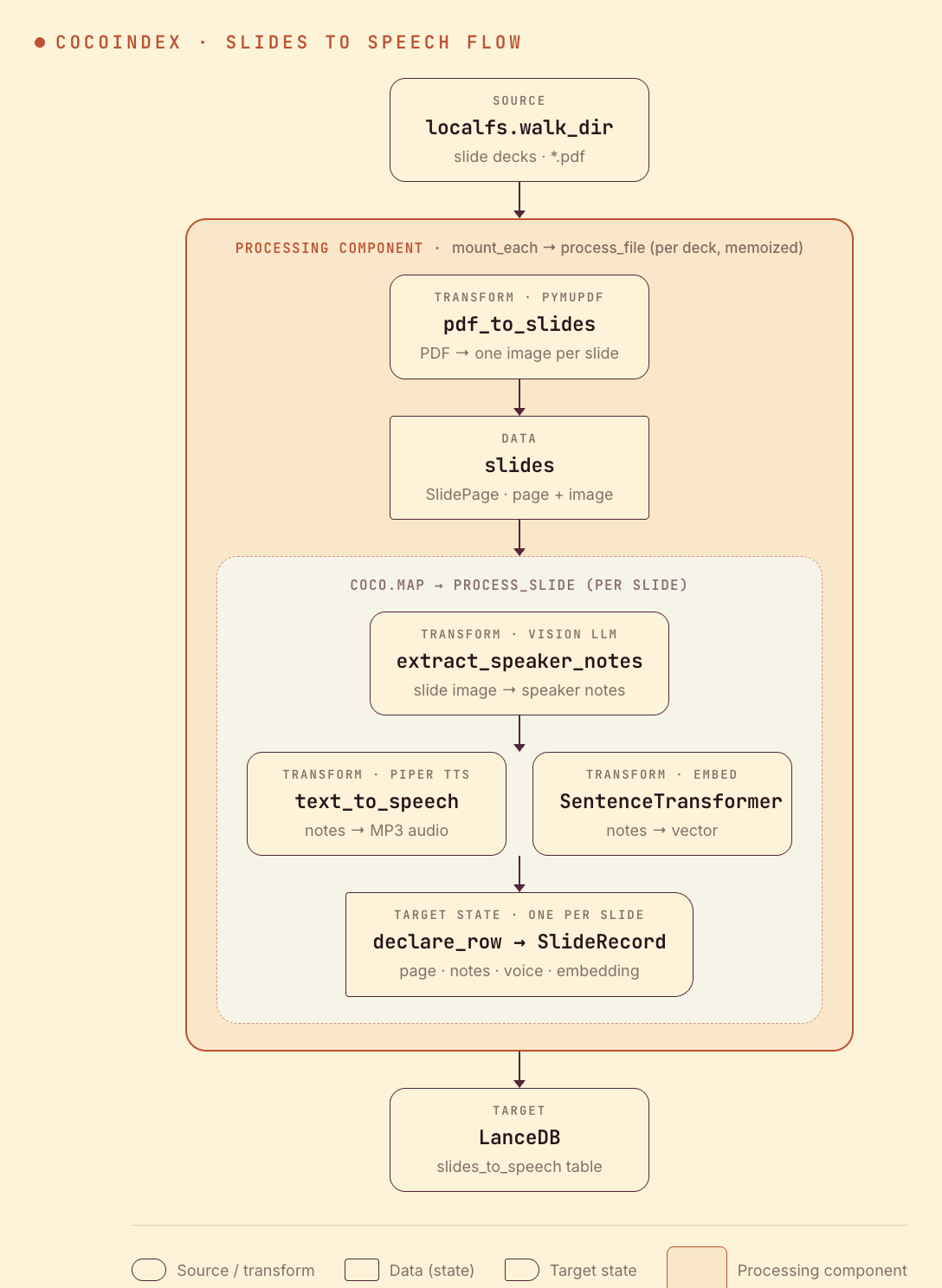
A deck fans out to slides, and each slide produces text, audio, and a vector:
- Render each slide of the PDF to an image (pymupdf).
- A vision LLM writes speaker notes for the slide.
- Piper synthesizes the notes to MP3 audio; a sentence-transformer embeds the notes.
- Store one LanceDB row per slide — page, notes, audio, and embedding.
Speaker notes from a slide image
The vision LLM reads the rendered slide and writes presenter narration. Extraction is instructor over LiteLLM, so the image goes in as a data URL and a typed SlideTranscript comes back:
class SlideTranscript(pydantic.BaseModel):
speaker_notes: str = pydantic.Field(
description="Natural spoken narration for this slide, as a presenter would say it."
)
@coco.fn(memo=True)
async def extract_speaker_notes(image: bytes) -> SlideTranscript:
client = instructor.from_litellm(litellm.acompletion, mode=instructor.Mode.JSON)
data_url = "data:image/png;base64," + base64.b64encode(image).decode()
result = await client.chat.completions.create(
model=coco.use_context(LLM_MODEL), # e.g. gemini/gemini-2.5-flash
response_model=SlideTranscript,
messages=[{"role": "user", "content": [
{"type": "text", "text": "Write speaker notes for this slide."},
{"type": "image_url", "image_url": {"url": data_url}},
]}],
)
return SlideTranscript.model_validate(result.model_dump())A note on the port. The v0 example pulled slides from Google Drive and used BAML for the vision call; this v1 port reads slides from a local folder and uses instructor + LiteLLM (any vision model — Gemini, GPT-4o, …). Point the source at a Google Drive folder to reproduce the original.
Narrate locally with Piper
Piper is a fast, fully local neural TTS — no API, no per-character billing. The voice model loads once and synthesizes the notes to MP3:
@coco.fn.as_async(runner=coco.GPU)
def text_to_speech(text: str) -> bytes:
voice = get_piper_voice() # cached PiperVoice
chunks = list(voice.synthesize(text))
pcm = b"".join(c.audio_int16_bytes for c in chunks)
audio = AudioSegment(data=pcm, sample_width=chunks[0].sample_width,
frame_rate=chunks[0].sample_rate, channels=chunks[0].sample_channels)
out = io.BytesIO(); audio.export(out, format="mp3", bitrate="64k")
return out.getvalue()Fan out per slide and store
process_file renders the deck to slides, then maps each through process_slide, which runs the vision LLM, then synthesizes audio and embeds the notes concurrently before declaring the row:
@coco.fn
async def process_slide(slide, filename, table) -> None:
notes = (await extract_speaker_notes(slide.image)).speaker_notes
voice, embedding = await asyncio.gather(
text_to_speech(notes),
coco.use_context(EMBEDDER).embed(notes),
)
table.declare_row(row=SlideRecord(
id=f"{filename}#{slide.page_number}", filename=filename, page=slide.page_number,
speaker_notes=notes, voice=voice, embedding=embedding,
))The MP3 audio is stored right in the LanceDB row (a binary column), so a search hit comes with playable narration attached.
Run the pipeline
python3 -m piper.download_voices en_US-lessac-medium # ~60 MB local voice
cp .env.example .env # set GEMINI_API_KEY (or OPENAI_API_KEY)
pip install -e . # needs ffmpeg for MP3 export
cocoindex update mainDrop a slide-deck PDF into slides/. On a 3-slide sample deck, this produces three LanceDB rows, each with Gemini-written speaker notes and ~170–280 KB of Piper MP3 audio.
Search the deck
Embed a query the same way and search LanceDB:
python main.py "reducing latency and reliability"On the sample deck, that query ranks the Engineering Priorities slide first — above the roadmap and go-to-market slides — matching the spoken notes by meaning, not keywords. Each hit carries the slide’s MP3 narration, ready to play.
Incremental updates
- Add a deck — only its slides are rendered, narrated, and embedded.
- Edit a deck — slides reconcile against LanceDB; unchanged slides keep their notes and audio.
- Swap the voice or LLM — change
PIPER_MODEL_NAMEorLLM_MODEL; the affected steps re-run, the rest is served from cache.
Run it
The full, runnable example is in the CocoIndex repo: examples/slides_to_speech. For transcribing existing audio instead of generating it, see Audio → Text.
Got a deck library you want to narrate and search? Come tell us on Discord — and if this was useful, star CocoIndex on GitHub.