
A pile of product listings has the recommendations hiding in plain sight — a pen pairs with ink refills and a notebook; a monitor pairs with a stand and an HDMI cable. But that knowledge is locked in prose. In this tutorial we’ll build a CocoIndex pipeline that turns a folder of product JSON into a Neo4j graph: an LLM tags each product with what it is and what complements it, and the shared taxonomy nodes turn into a recommendation engine you can query in Cypher.
The whole pipeline is ordinary async Python and your own types. The heavy lifting — incremental processing, change tracking, managed graph targets — runs in a Rust engine underneath, so editing one product re-extracts only that product and the graph reconciles itself.
What we’re building
Two node types, two relationship types:
Productnodes — one per listing (title, price).Taxonomynodes — one per distinct label (gel pen,notebook,ink refill), keyed by value and shared across products.PRODUCT_TAXONOMYedges —Product → Taxonomy: what the product is.PRODUCT_COMPLEMENTARY_TAXONOMYedges —Product → Taxonomy: what a buyer might also need.
The recommendation falls out of the graph: products whose complementary taxonomy matches another product’s is-a taxonomy are things to recommend together.
Pipeline overview
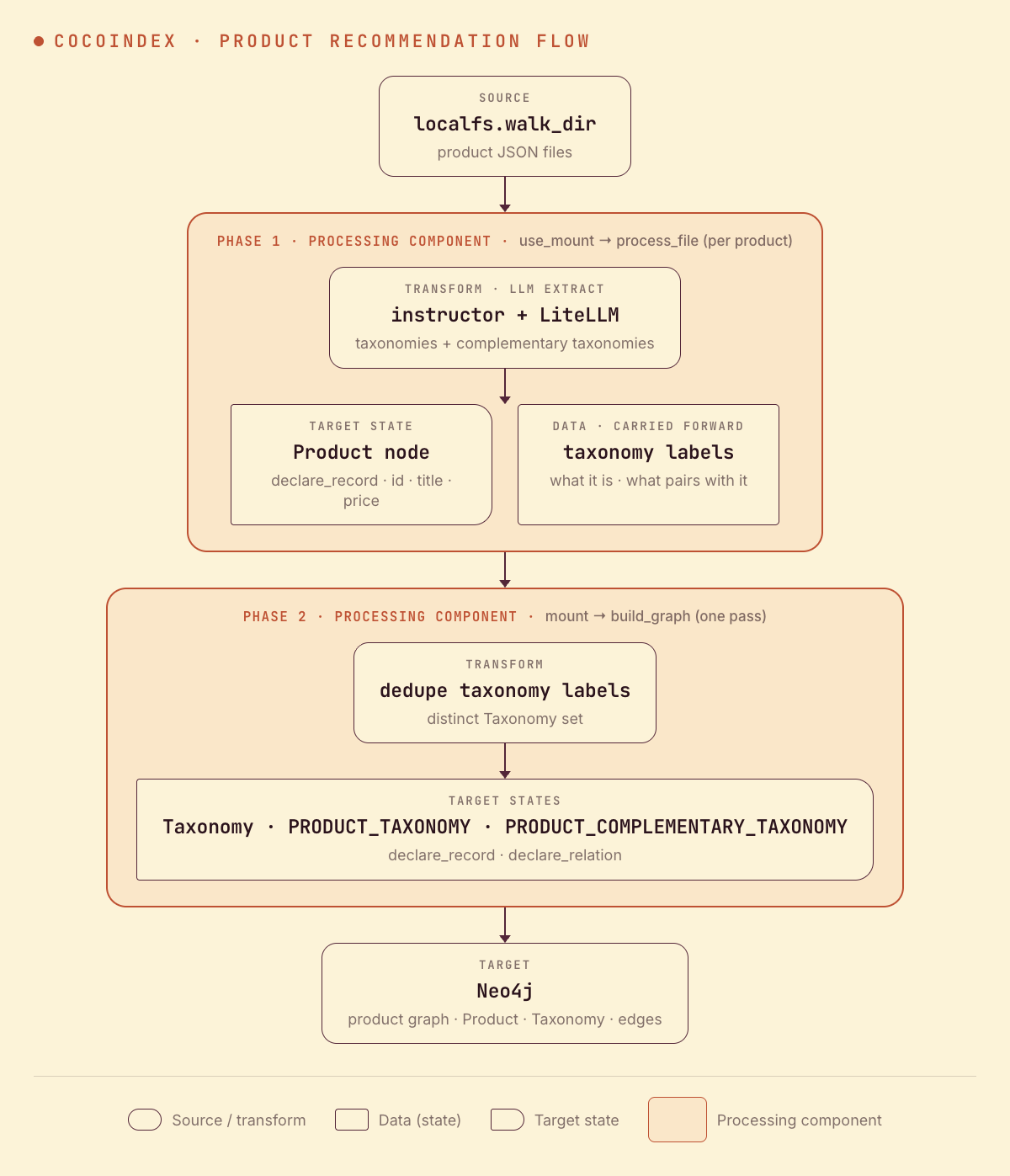
The taxonomy labels are shared across products, so — like the docs knowledge graph — the pipeline runs in two phases:
- Per-product extraction. For each product, render its details to Markdown, LLM-extract the taxonomies and complementary taxonomies, declare the
Productnode, and carry the labels forward. - Graph building. One pass declares the deduplicated
Taxonomynodes and the two relationship types across all products.
You declare the transformation with native Python; CocoIndex works out what to insert, update, and delete. Think: target_state = transformation(source_state).
LLM taxonomy extraction
The extraction schema is two lists, and the field descriptions do the prompting — “what it is” vs. “what pairs with it”:
class ProductTaxonomy(pydantic.BaseModel):
name: str = pydantic.Field(
description="A concise noun for the product's core functionality — lowercase, "
"specific ('pen', 'printer'), not broad ('office supplies')."
)
class ProductTaxonomyInfo(pydantic.BaseModel):
taxonomies: list[ProductTaxonomy] = pydantic.Field(description="What this product is.")
complementary_taxonomies: list[ProductTaxonomy] = pydantic.Field(
description="Taxonomies for complementary products a buyer might also need."
)
@coco.fn(memo=True)
async def extract_taxonomy(detail: str) -> ProductTaxonomyInfo:
client = instructor.from_litellm(litellm.acompletion, mode=instructor.Mode.JSON)
result = await client.chat.completions.create(
model=coco.use_context(LLM_MODEL),
response_model=ProductTaxonomyInfo,
messages=[{"role": "system", "content": TAXONOMY_PROMPT}, {"role": "user", "content": detail}],
)
return ProductTaxonomyInfo.model_validate(result.model_dump())Extraction is instructor over LiteLLM — swap LLM_MODEL for any provider. @coco.fn(memo=True) caches each extraction by content, so re-running re-tags only changed products.
Phase 1: per-product extraction
process_file renders the product JSON to Markdown (a Jinja template), declares the Product node, extracts the taxonomies, and returns the labels for phase 2:
@coco.fn(memo=True)
async def process_file(file: FileLike, product_table: neo4j.TableTarget[Product]) -> ProductTaxonomies:
raw = json.loads(await file.read_text())
product_id = file.file_path.path.name.removesuffix(".json")
price = float(str(raw["price"]).lstrip("$").replace(",", ""))
product_table.declare_record(row=Product(id=product_id, title=raw["title"], price=price))
info = await extract_taxonomy(PRODUCT_TEMPLATE.render(**raw))
return ProductTaxonomies(
product_id=product_id,
taxonomies=[t.name for t in info.taxonomies],
complementary=[t.name for t in info.complementary_taxonomies],
)Phase 2: build the graph
Taxonomy nodes are shared, so they’re owned by one graph pass — it declares the deduplicated node set and the two relationship types:
@coco.fn
async def build_graph(products, taxonomy_table, product_taxonomy_rel, complementary_rel) -> None:
labels = {t for p in products for t in (*p.taxonomies, *p.complementary)}
for value in labels:
taxonomy_table.declare_record(row=Taxonomy(value=value))
for p in products:
for t in set(p.taxonomies):
product_taxonomy_rel.declare_relation(from_id=p.product_id, to_id=t)
for t in set(p.complementary):
complementary_rel.declare_relation(from_id=p.product_id, to_id=t)Both relationship types carry no payload, so the Neo4j connector derives each edge’s identity from its (Product, Taxonomy) endpoints — one edge per pair, no duplicates.
Run the pipeline
docker run -d -p 7474:7474 -p 7687:7687 -e NEO4J_AUTH=neo4j/cocoindex --name cocoindex-neo4j neo4j:5.26-community
cp .env.example .env # set OPENAI_API_KEY (or LLM_MODEL=ollama/llama3.2)
pip install -e .
cocoindex update mainThe example ships a products/ folder of sample listings (pens, notebooks, monitors, …). Running it builds the graph — on the 9 sample products that’s 9 Product nodes, ~40 Taxonomy nodes, and the two edge types wired up.
Explore the recommendations
Open Neo4j Browser (neo4j / cocoindex) and ask the graph for recommendations:
// What a pen is, and what pairs with it
MATCH (p:Product)-[:PRODUCT_TAXONOMY]->(:Taxonomy {value: "gel pen"})
MATCH (p)-[:PRODUCT_COMPLEMENTARY_TAXONOMY]->(c:Taxonomy)
RETURN p.title, collect(c.value) AS also_needs
// Recommend products to pair with anything that is a "pen":
// find products whose *is-a* taxonomy matches a pen's *complementary* taxonomy
MATCH (:Taxonomy {value: "gel pen"})<-[:PRODUCT_TAXONOMY]-(:Product)
-[:PRODUCT_COMPLEMENTARY_TAXONOMY]->(need:Taxonomy)
MATCH (rec:Product)-[:PRODUCT_TAXONOMY]->(need)
RETURN DISTINCT rec.titleOn the sample data, recommending for a pen surfaces the notepad and the multipurpose paper — exactly the cross-sell you’d want.
Incremental updates
- Edit a product — only that product re-extracts; the graph pass re-runs and diffs, adding new taxonomy nodes/edges and removing ones no longer supported anywhere.
- Add a product — one extraction plus the graph diff.
- Delete a product — its
Productnode and edges are cleaned up; taxonomies only it introduced disappear on the next pass. - Swap the LLM —
LLM_MODELhasdetect_change=True, so changing it re-extracts everything against the new model with no cache to clear.
Run it
The full, runnable example is in the CocoIndex repo: examples/product_recommendation. For a concept graph over prose docs instead of products, see Turn Docs into a Knowledge Graph.
Got a product catalog you want to turn into a recommendation graph? Come tell us on Discord — and if this was useful, star CocoIndex on GitHub.