
This is the Semantic Search 101 example with one thing swapped: instead of storing the vectors in Postgres with pgvector, we write them to a Turbopuffer namespace — a managed, serverless vector store, so there’s no database to run yourself. The chunking and embedding are identical; only the target changes.
Everything else stays the same: ordinary async Python and your own types, with incremental processing, change tracking, and managed targets running in the Rust engine underneath — so when a file changes, only the affected chunks get re-embedded and re-upserted.
Flow overview
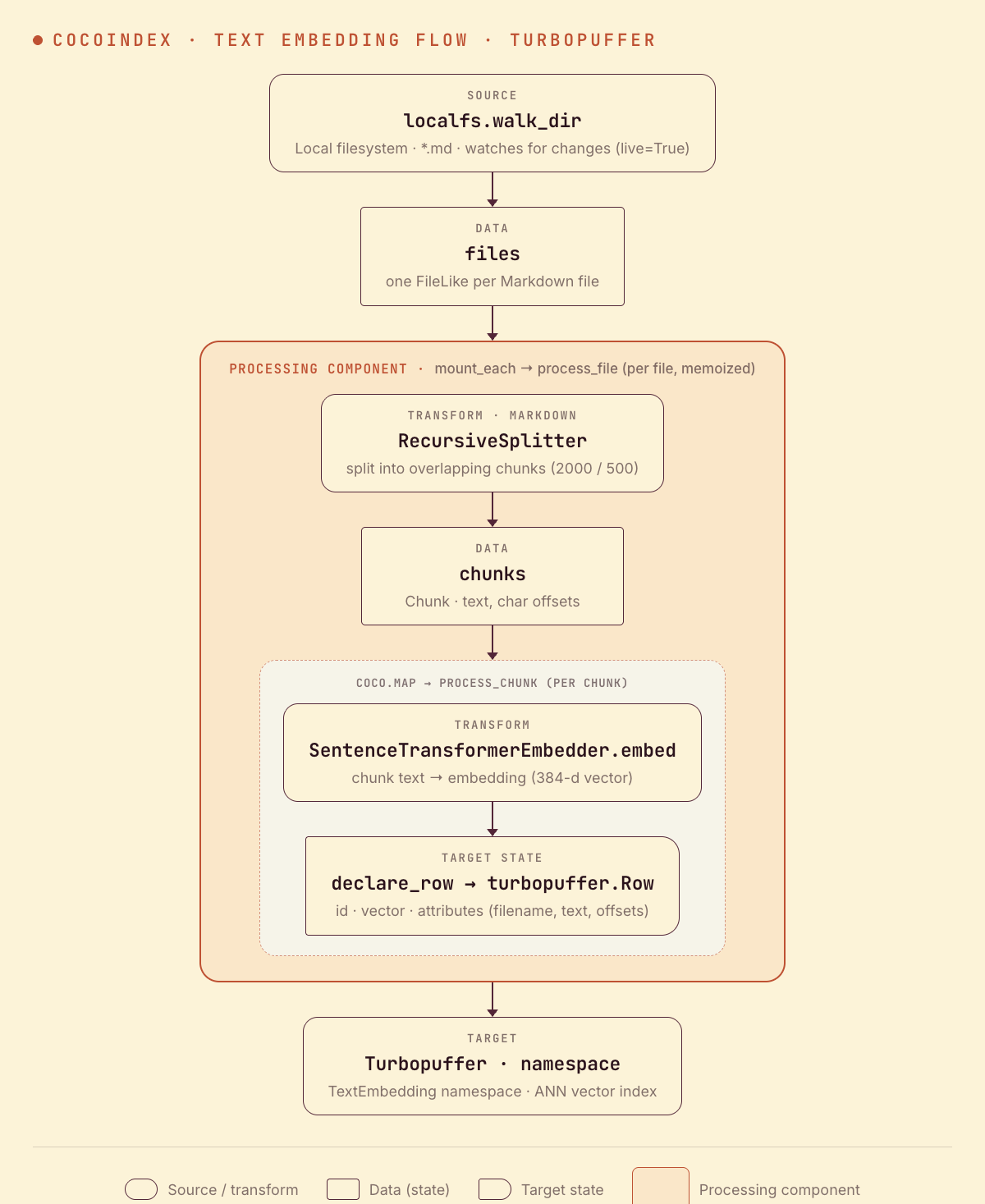
From a high level, these are the steps:
- Read Markdown files from a local directory.
- Split each file into overlapping chunks, then embed every chunk.
- Upsert each chunk and its embedding as a row in a Turbopuffer namespace (as target states).
You declare the transformation logic with native Python, without worrying about how updates propagate. Think: target_state = transformation(source_state).
For the chunk-and-embed half of the pipeline — process_file, RecursiveSplitter, and SentenceTransformerEmbedder — read the base walkthrough. Here we focus on the one part that differs: the Turbopuffer target.
Set up the Turbopuffer client
Turbopuffer is a cloud service, so the shared resource the pipeline needs is an API client rather than a database pool. We provide an AsyncTurbopuffer client in the lifespan, alongside the embedder, keyed off the TURBOPUFFER_API_KEY env var.
TPUF_REGION = os.environ.get("TURBOPUFFER_REGION", "gcp-us-central1")
TPUF_NAMESPACE = "TextEmbedding"
EMBED_MODEL = "sentence-transformers/all-MiniLM-L6-v2"
TPUF_DB = coco.ContextKey[turbopuffer.AsyncTurbopuffer]("text_embedding_turbopuffer")
EMBEDDER = coco.ContextKey[SentenceTransformerEmbedder]("embedder", detect_change=True)
@coco.lifespan
async def coco_lifespan(builder: coco.EnvironmentBuilder) -> AsyncIterator[None]:
api_key = os.environ.get("TURBOPUFFER_API_KEY")
if not api_key:
raise RuntimeError("TURBOPUFFER_API_KEY is not set")
client = turbopuffer.AsyncTurbopuffer(region=TPUF_REGION, api_key=api_key)
builder.provide(TPUF_DB, client)
builder.provide(EMBEDDER, SentenceTransformerEmbedder(EMBED_MODEL))
yieldDeclare a row in the namespace
A Turbopuffer row is an id, a vector, and an open bag of attributes. Instead of a typed table column per field, the filename, text, and offsets ride along as attributes — the embedding is the indexed vector.
@coco.fn
async def process_chunk(
chunk: Chunk,
filename: pathlib.PurePath,
id_gen: IdGenerator,
target: turbopuffer.NamespaceTarget,
) -> None:
embedding_vec = await coco.use_context(EMBEDDER).embed(chunk.text)
target.declare_row(
turbopuffer.Row(
id=str(await id_gen.next_id(chunk.text)),
vector=embedding_vec,
attributes={
"filename": str(filename),
"chunk_start": chunk.start.char_offset,
"chunk_end": chunk.end.char_offset,
"text": chunk.text,
},
)
)target.declare_row declares the row as a target state; CocoIndex handles upserting and deleting it to match. The id is derived from the chunk’s text, so unchanged chunks keep their id and embedding across runs.
Mount the namespace target
app_main mounts the namespace, then fans out one processing component per file. The vector schema comes straight from the embedder, so the namespace’s dimension matches what we write.
@coco.fn
async def app_main(sourcedir: pathlib.Path) -> None:
target_namespace = await turbopuffer.mount_namespace_target(
TPUF_DB,
namespace_name=TPUF_NAMESPACE,
schema=await turbopuffer.NamespaceSchema.create(
vectors=turbopuffer.VectorDef(schema=EMBEDDER),
),
)
files = localfs.walk_dir(
sourcedir,
recursive=True,
path_matcher=PatternFilePathMatcher(included_patterns=["**/*.md"]),
live=True, # watch for changes; pass -L to `cocoindex update` to run live
)
await coco.mount_each(process_file, files.items(), target_namespace)mount_namespace_target creates and manages the Turbopuffer namespace for you: schema, idempotent upserts, and orphan cleanup when a file disappears. live=True makes the filesystem source watch for changes, and mount_each runs one component per file so the engine can track and update them independently.
Setup and run
-
A free Turbopuffer API key. Copy
.env.exampleto.envand fill it in (TURBOPUFFER_REGIONdefaults togcp-us-central1):export TURBOPUFFER_API_KEY="tpuf_..." -
Install CocoIndex with the Turbopuffer and embedding extras:
pip install -U "cocoindex[turbopuffer,sentence_transformers]" numpy python-dotenv -
A few
.mdfiles in amarkdown_files/directory — grab the sample file from the repo or drop in your own.
Run the cocoindex CLI to build and update the index, then query it from the command line:
# Catch-up run: scan, sync, exit
cocoindex update main
# Live run: keep watching for file changes
cocoindex update -L main
# Search the namespace
python main.py "what is self-attention?"The query embeds your text with the same model and asks Turbopuffer for the nearest vectors with rank_by=("vector", "ANN", ...), so indexing and querying stay consistent. The most semantically similar chunks come back ranked — even when they share none of the words in your query.
Incremental updates
CocoIndex keeps the namespace in sync with your files and does the minimum work to get there — you never compute a diff. @coco.fn(memo=True) on process_file decides what to recompute (a file is skipped when its content and the function’s code are unchanged), and mount_namespace_target decides what to write (each row’s id is derived from its chunk’s text, so only changed rows are upserted and rows whose source is gone are deleted).
- A file is added — only that file is chunked and embedded, and its rows are upserted. The rest is untouched.
- A file is edited — it is re-chunked; unchanged chunks keep their
idand embedding, new chunks are embedded and upserted, and chunks that no longer exist are deleted. - A file is deleted — its rows are removed from the namespace automatically.
The same machinery covers logic changes: tune the chunk size or swap the embedding model, and CocoIndex applies only the difference. A catch-up run (cocoindex update main) does this once and exits; live mode (cocoindex update -L main) keeps watching.
Run it
The full, runnable example is in the CocoIndex repo: examples/text_embedding_turbopuffer. To swap the store for self-hosted Postgres instead, see the base Semantic Search 101 example. Questions? Come say hi in our Discord, and if this helped, a star on GitHub goes a long way.