
SEC filings come in many shapes — narrative 10-K risk factors as text, structured financials as XBRL JSON, exhibits as PDF. In this tutorial we’ll build a CocoIndex pipeline that pulls these formats into a single searchable index in Apache Doris, with both a vector index for semantic search and a full-text index for keyword search — the foundation for hybrid retrieval. Along the way each document is scrubbed of PII, chunked, embedded, and tagged with risk/topic labels.
The whole pipeline is ordinary async Python. Embedding runs on a GPU runner, and the Rust engine handles incremental processing — add a filing and only its chunks are embedded and loaded.
Flow overview
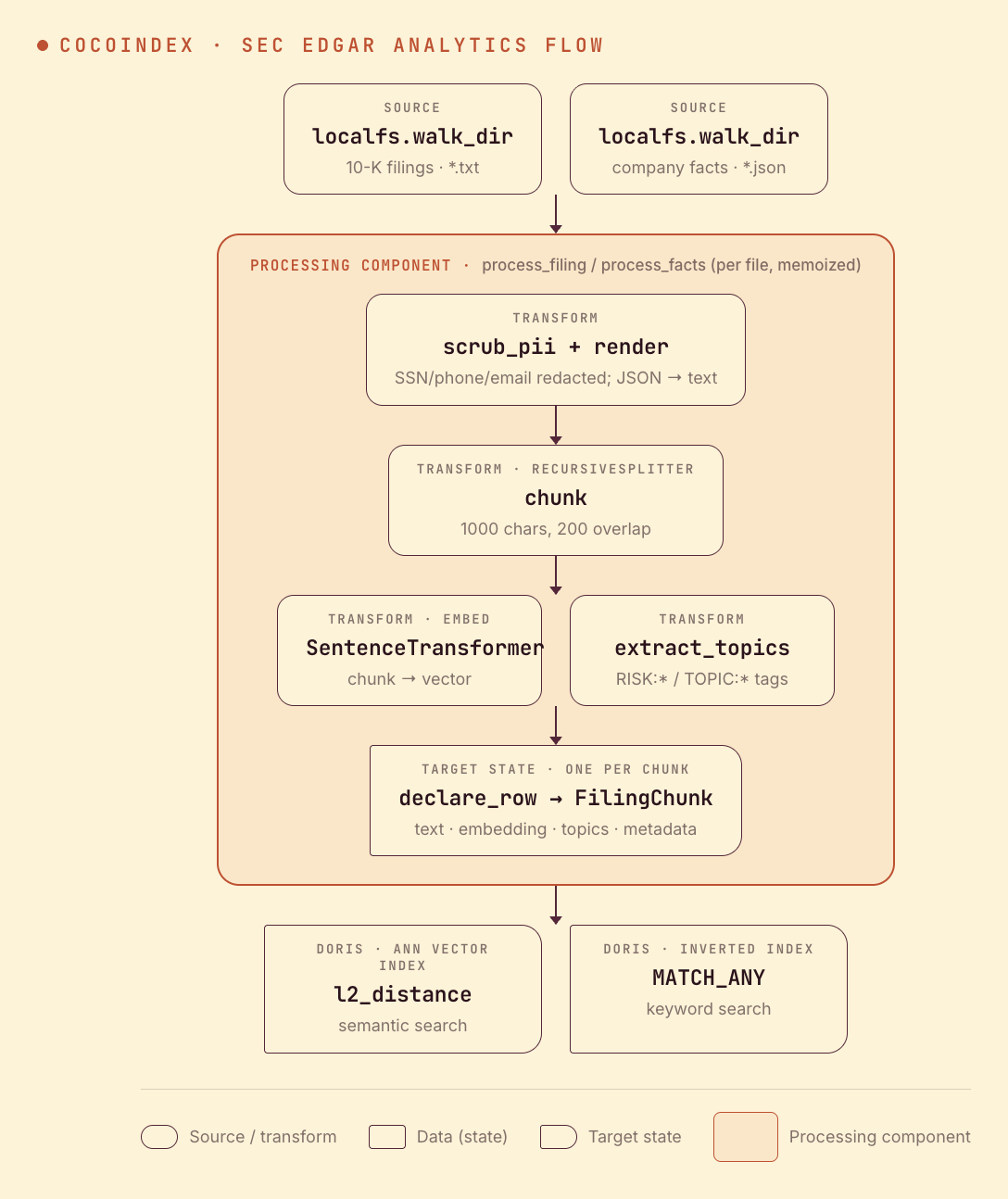
Two source formats fan into one chunk table:
- Sources —
*.txt10-K filings and*.jsonXBRL company facts (the JSON is rendered to searchable text first). - Scrub & chunk — strip SSNs / phones / emails before indexing, then split into overlapping chunks.
- Embed & tag — a sentence-transformer embeds each chunk; a keyword pass tags
RISK:*/TOPIC:*labels. - Load into Doris — one row per chunk, into a table with a vector (ANN) index and a full-text (inverted) index.
One table, two index types
The row type is a plain dataclass. The magic is in mount_table_target: the same table gets a vector index (for l2_distance semantic search) and an inverted index (for MATCH_ANY keyword search):
@dataclass
class FilingChunk:
chunk_id: str # primary key
source_type: str # "filing" | "facts"
doc_filename: str
cik: str
filing_date: str
form_type: str
text: str
topics: list[str]
embedding: Annotated[NDArray, EMBEDDER]
table = await doris.mount_table_target(
DORIS_DB, TABLE,
await doris.TableSchema.from_class(FilingChunk, primary_key=["chunk_id"]),
vector_indexes=[doris.VectorIndexDef(field_name="embedding", metric_type="l2_distance")],
inverted_indexes=[doris.InvertedIndexDef(field_name="text", parser="unicode")],
)Scrub PII, then chunk, embed, and tag
PII is redacted before chunking, so it never enters the index. Each format gets a thin per-file entry point (process_filing, process_facts) that funnels into one shared path — scrub, chunk, embed, tag, declare a row per chunk:
async def _index_text(text, source_type, filename, cik, filing_date, form_type, table):
embedder = coco.use_context(EMBEDDER)
for chunk in _splitter.split(_scrub_pii(text), chunk_size=1000, chunk_overlap=200,
language="markdown"):
table.declare_row(row=FilingChunk(
chunk_id=_chunk_id(filename, chunk.start.char_offset, chunk.end.char_offset),
source_type=source_type, doc_filename=filename, cik=cik,
filing_date=filing_date, form_type=form_type,
text=chunk.text, topics=_extract_topics(chunk.text),
embedding=await embedder.embed(chunk.text),
))Both sources declare_row into the same Doris table — chunk_id is a stable uuid5 of the file and chunk offsets, so re-running reconciles cleanly instead of duplicating.
A note on the port. The original v0 example also ingested PDF exhibits via docling; this v1 port focuses on the text and XBRL-JSON sources (the PDF path is identical to the Manuals to Structured Data example —
doclingbytes → Markdown, then the same_index_text). It needs Apache Doris 4.0+ for vector index support; a readydocker-compose.ymlis included.
Run the pipeline
docker compose up -d fe be # Apache Doris 4.0 (FE + BE)
python download.py # synthetic 10-K filings + XBRL company facts
cp .env.example .env # Doris host/ports
pip install -e .
cocoindex update mainOn the sample data this loads 4 chunks (2 filings + 2 company-facts) into Doris, creating both idx_vec_embedding (ANN) and idx_inv_text (INVERTED). Topic tags come out as you’d expect — Apple’s filing tagged RISK:CYBER, RISK:CLIMATE, RISK:SUPPLY, RISK:REGULATORY, TOPIC:AI, Microsoft’s RISK:CYBER, RISK:REGULATORY, TOPIC:AI, TOPIC:CLOUD.
Hybrid search with RRF
The payoff is hybrid retrieval — fuse the vector ranking and the keyword ranking with Reciprocal Rank Fusion. search.py does both in one SQL query:
WITH semantic AS (
SELECT chunk_id, ROW_NUMBER() OVER (ORDER BY l2_distance(embedding, {q})) AS rk
FROM filing_chunks
),
lexical AS (
SELECT chunk_id, ROW_NUMBER() OVER (
ORDER BY CASE WHEN text MATCH_ANY '{keywords}' THEN 0 ELSE 1 END) AS rk
FROM filing_chunks
)
SELECT s.doc_filename, 1.0/(60 + s.rk) + 1.0/(60 + l.rk) AS rrf
FROM semantic s JOIN lexical l USING (chunk_id) ORDER BY rrf DESCpython search.py "cloud computing and AI risk"On the sample data that ranks Microsoft’s cloud-and-AI filing first (it carries both TOPIC:CLOUD and TOPIC:AI), Apple’s second, and the company-facts rows below — semantic relevance and keyword presence combined, not either alone.
Incremental updates
- Add a filing — only its chunks are scrubbed, embedded, tagged, and stream-loaded into Doris.
- Edit a filing — chunks reconcile by
chunk_id; unchanged chunks are untouched. - Delete a filing — its chunks are removed from the table.
Run it
The full, runnable example is in the CocoIndex repo: examples/sec_edgar_analytics. For the PDF-extraction side, see Manuals to Structured Data; for a pure-vector setup, see Text Embedding.
Indexing your own filing archive? Come tell us on Discord — and if this was useful, star CocoIndex on GitHub.