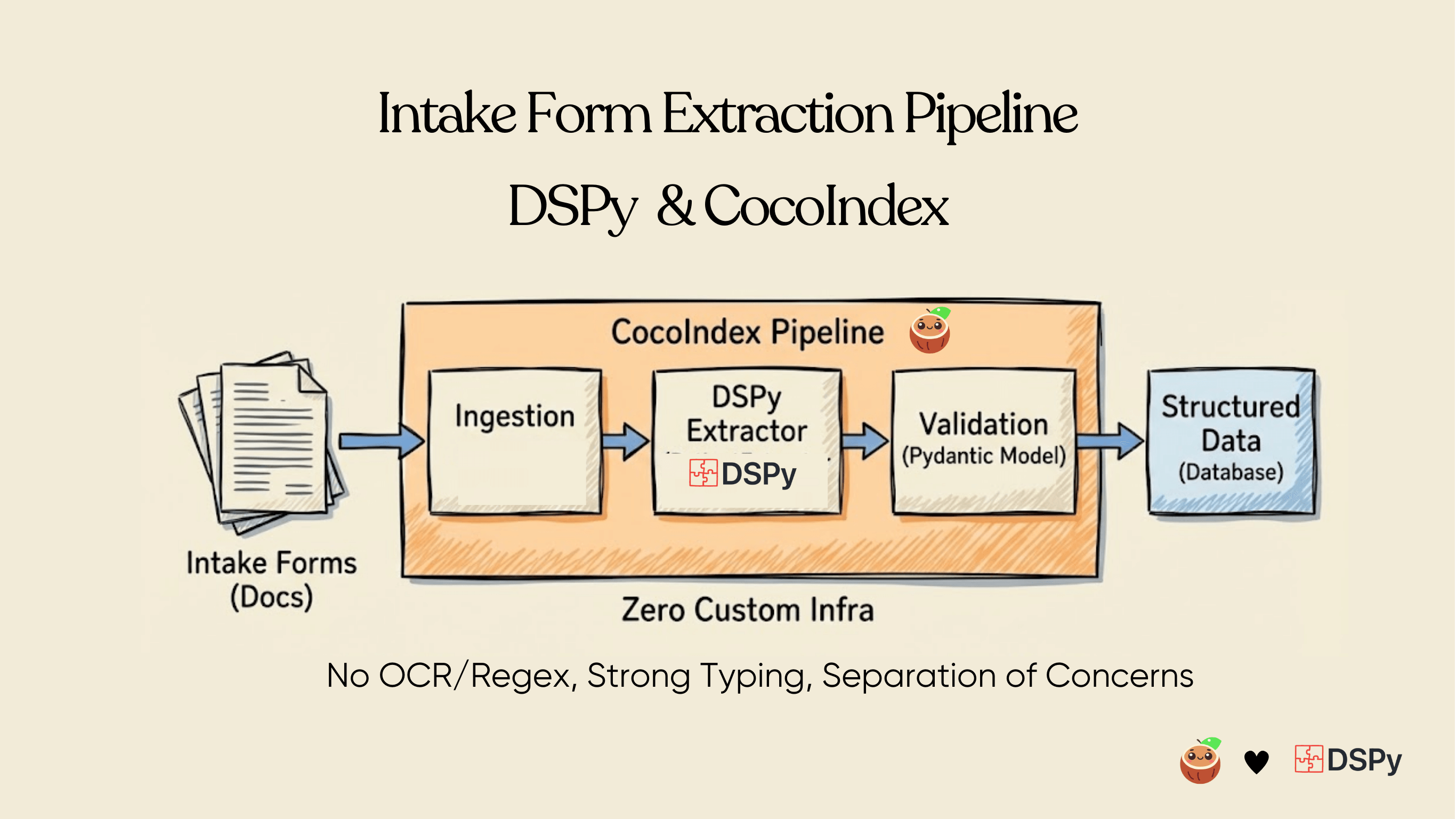
We’ll take a folder of patient intake PDFs — names, addresses, insurance, medications, allergies, consent — and turn each one into a clean, validated JSON record. The hard part isn’t the file plumbing; it’s that intake forms are visual: checkboxes, hand-filled fields, tables of medications. So instead of extracting text, we render each PDF page to an image and let a vision model read the form the way a person would. DSPy handles the prompting — you declare a typed Signature and it produces a Pydantic Patient, no prompt strings to hand-tune.
The whole pipeline is ordinary async Python and your own types. The heavy lifting — incremental processing, change tracking, managed targets — runs in a Rust engine underneath, so only changed forms get re-extracted, and each one becomes exactly one JSON file on disk.
Flow overview
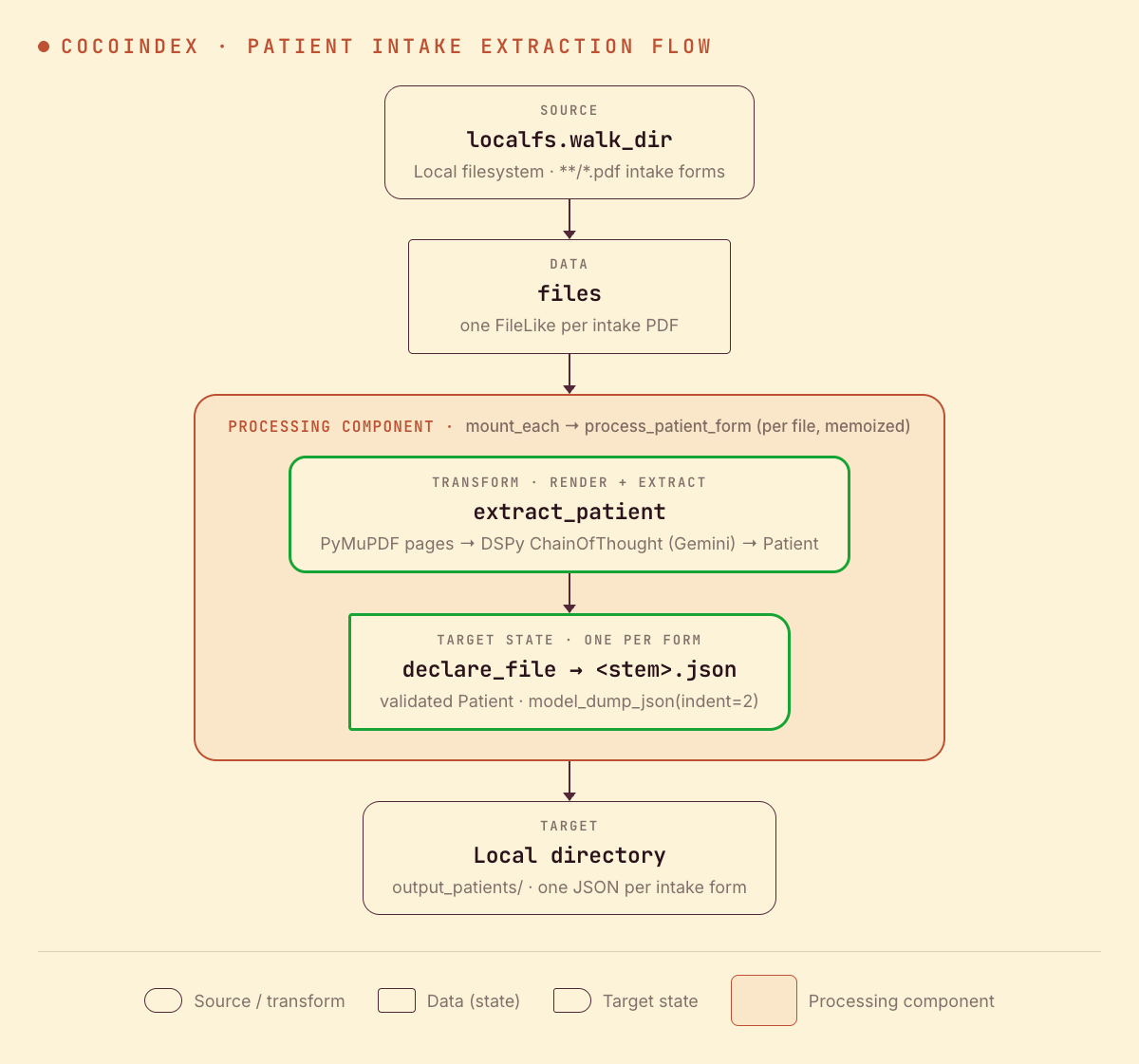
From a high level, these are the steps:
- Read PDF intake forms from a local directory.
- Render each page to an image with PyMuPDF, then extract a typed
Patientwith a DSPyChainOfThoughtvision module on Gemini. - Write one JSON file per form to a local directory (as target states).
You declare the transformation logic with native Python, without worrying about how updates propagate. Think: target_state = transformation(source_state).
Setup
-
A Gemini API key — the extraction runs on a Gemini vision model. The example auto-loads a
.envfile:echo "GEMINI_API_KEY=your_api_key_here" > .env -
Install CocoIndex and the dependencies this example uses (DSPy for the extraction, PyMuPDF to rasterize PDFs, Pillow for the image bytes DSPy passes along):
pip install -U cocoindex dspy-ai pymupdf pillow pydantic python-dotenv -
A few intake PDFs to extract. The example ships a
data/patient_forms/folder with a handful of artificial forms — or drop your own in.
Define the output schema
The output is just Python types. Patient is a Pydantic model that describes everything we want off the form, with nested models for the pieces that have structure of their own — address, insurance, medications, allergies, surgeries. This is the contract: DSPy fills it in, Pydantic validates it, and it serializes straight to JSON.
class Address(BaseModel):
street: str
city: str
state: str
zip_code: str
class Medication(BaseModel):
name: str
dosage: str
class Patient(BaseModel):
"""Complete patient information extracted from intake form."""
name: str
dob: datetime.date
gender: str
address: Address
phone: str
email: str
emergency_contact: Contact
insurance: Insurance | None = None
reason_for_visit: str
past_conditions: list[Condition] = Field(default_factory=list)
current_medications: list[Medication] = Field(default_factory=list)
allergies: list[Allergy] = Field(default_factory=list)
surgeries: list[Surgery] = Field(default_factory=list)
consent_given: bool
consent_date: str | None = NoneOptional fields (insurance, consent_date) and default_factory=list collections mean a form that doesn’t mention medications produces an empty list, not a failure — the model bends to whatever the form actually contains.
Declare the extraction with DSPy
Rather than write a prompt, you declare a DSPy Signature: a list of form-page images comes in, a typed Patient comes out. ChainOfThought wraps it so the model reasons before it answers, which helps on dense, checkbox-heavy forms. DSPy compiles the typed in/out into the actual prompt for you.
class PatientExtractionSignature(dspy.Signature):
"""Extract structured patient information from a medical intake form image."""
form_images: list[dspy.Image] = dspy.InputField(
desc="Images of the patient intake form pages"
)
patient: Patient = dspy.OutputField(
desc="Extracted patient information with all available fields filled"
)
class PatientExtractor(dspy.Module):
"""DSPy module for extracting patient information from intake form images."""
def __init__(self) -> None:
super().__init__()
self.extract = dspy.ChainOfThought(PatientExtractionSignature)
def forward(self, form_images: list[dspy.Image]) -> Patient:
result = self.extract(form_images=form_images)
return result.patientThe model is configured once at module load — dspy.configure(lm=dspy.LM("gemini/gemini-2.5-flash")) — so the same vision LM is reused for every form. Because the OutputField is typed as Patient, DSPy asks the model for that exact shape and hands you back a validated Pydantic object, not a string to parse.
Render the PDF and extract
extract_patient is the one custom transform. It rasterizes every page of the PDF to a PNG with PyMuPDF (at 2× scale, so small print stays legible), wraps each page as a dspy.Image, and runs the extractor. No text extraction, no Markdown conversion — the model reads the rendered form directly.
@coco.fn
def extract_patient(pdf_content: bytes) -> Patient:
"""Extract patient information from PDF content."""
pdf_doc = pymupdf.open(stream=pdf_content, filetype="pdf")
form_images = []
for page in pdf_doc:
pix = page.get_pixmap(matrix=pymupdf.Matrix(2, 2))
img_bytes = pix.tobytes("png")
form_images.append(dspy.Image(img_bytes))
pdf_doc.close()
extractor = PatientExtractor()
patient = extractor(form_images=form_images)
return patient@coco.fn makes this a CocoIndex function so the engine can track it. Rendering at Matrix(2, 2) matters: forms are full of small, hand-entered text, and the extra resolution is the difference between the model reading a zip code and guessing one.
Process a file
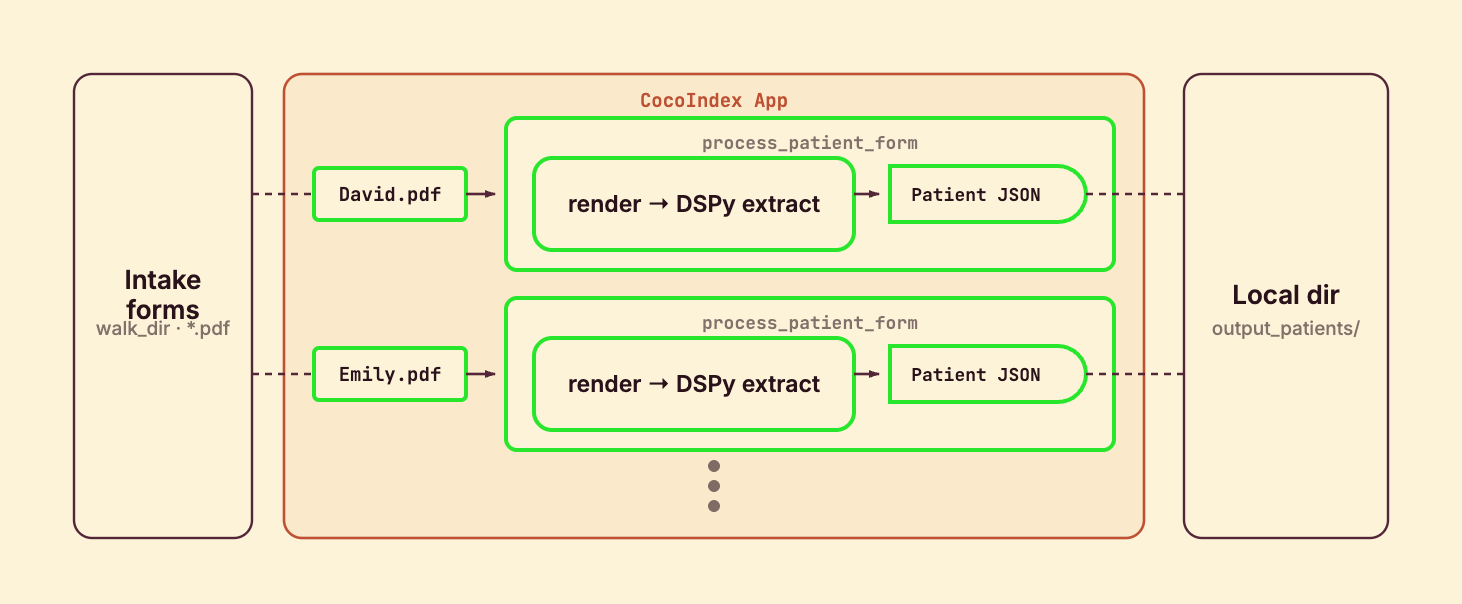
process_patient_form runs once per PDF. It reads the file’s bytes, extracts the Patient, serializes it to pretty-printed JSON, and declares one output file named after the source form.
@coco.fn(memo=True)
async def process_patient_form(file: FileLike, outdir: pathlib.Path) -> None:
"""Process a patient intake form PDF and extract structured information."""
content = await file.read()
patient_info = extract_patient(content)
patient_json = patient_info.model_dump_json(indent=2)
output_filename = file.file_path.path.stem + ".json"
localfs.declare_file(
outdir / output_filename, patient_json, create_parent_dirs=True
)@coco.fn with memo=True is what makes this incremental: if a form’s content and this function’s code are both unchanged, the whole file is skipped on the next run — so you never re-run the (paid, slow) vision extraction on a form you’ve already processed. localfs.declare_file declares the JSON as a target state; CocoIndex writes, rewrites, or deletes it to match.
Define the main function
app_main wires the source to the target. It walks the source directory for PDFs and mounts one processing component per file.
@coco.fn
async def app_main(sourcedir: pathlib.Path, outdir: pathlib.Path) -> None:
"""Main application function that processes patient intake forms."""
files = localfs.walk_dir(
sourcedir,
path_matcher=PatternFilePathMatcher(included_patterns=["**/*.pdf"]),
)
await coco.mount_each(process_patient_form, files.items(), outdir)
app = coco.App(
coco.AppConfig(name="PatientIntakeExtractionDSPy"),
app_main,
sourcedir=pathlib.Path("./data/patient_forms"),
outdir=pathlib.Path("./output_patients"),
)walk_dir scans the filesystem source for *.pdf files, and mount_each runs one component per file so the engine can track and update them independently. Each component owns exactly one output JSON, so the mapping from form to record is one-to-one — and when a form disappears, its JSON is cleaned up automatically.
Run the pipeline
Run the cocoindex CLI to build the index — scan the forms, extract, write the JSON files, and exit:
cocoindex update main.pyEach PDF in data/patient_forms/ becomes a JSON file in output_patients/, named after the source form:
ls output_patients/
# Patient_Intake_Form_David_Artificial.json
# Patient_Intake_Form_Emily_Artificial.json
# ...Open one and you’ll see the full Patient record — name, date of birth, address, insurance, the medication and allergy lists, consent — extracted straight from the rendered form and validated against the schema.
Incremental updates
CocoIndex keeps the output JSON in sync with your forms and does the minimum work to get there. You never compute a diff or write update logic. Two pieces make this work. @coco.fn(memo=True) decides what to recompute — a form is skipped when its bytes and the function’s code are both unchanged, so the vision model never re-reads a form you’ve already extracted. mount_each decides what to write — each component owns one JSON file, so the engine creates, rewrites, or deletes exactly the files that changed.
- A form is added — only that PDF is rendered and extracted; its JSON is written. The rest is untouched.
- A form is replaced — it is re-rendered and re-extracted, and its single JSON is rewritten.
- A form is deleted — its JSON is removed from the output directory automatically.
The same machinery covers logic changes too: add a field to the Patient model or switch the LM, and CocoIndex re-runs the extraction and rewrites the affected JSON. A catch-up run (cocoindex update main.py) does this once and exits.
Run it
The full, runnable example is in the CocoIndex repo: examples/patient_intake_extraction_dspy. Prefer to define your schema and extraction in a typed DSL instead of Python? The twin example Patient Intake Extraction with BAML runs the exact same flow with BAML doing the extraction. For a Postgres-backed structured-extraction flow with embeddings, see Paper Metadata.
Got a stack of forms, invoices, or scanned records you want as clean structured data? Come tell us on Discord — and if this was useful, star CocoIndex on GitHub.