
This is the multi-vector cousin of the CLIP image search example. Same idea — type “long neck”, get the giraffe back, no tags or captions — but instead of squeezing each image into a single vector, ColPali emits a bag of vectors, one per image patch, and matches a query the same way it reads a document: token against patch. The cost is more vectors per image; the payoff is finer-grained retrieval that holds up on dense, text-heavy, or busy images where a single embedding blurs everything together.
The store does the heavy lifting on the query side. We give Qdrant a multivector collection configured for MaxSim, so a query’s bag of vectors and an image’s bag of patch vectors are scored late-interaction style — each query vector finds its best-matching patch, summed across the query. The whole pipeline is ordinary async Python and your own types; incremental processing, change tracking, and the managed Qdrant collection run in a Rust engine underneath, in live mode inside the API server, so a new photo in the folder is searchable within a second.
Flow overview
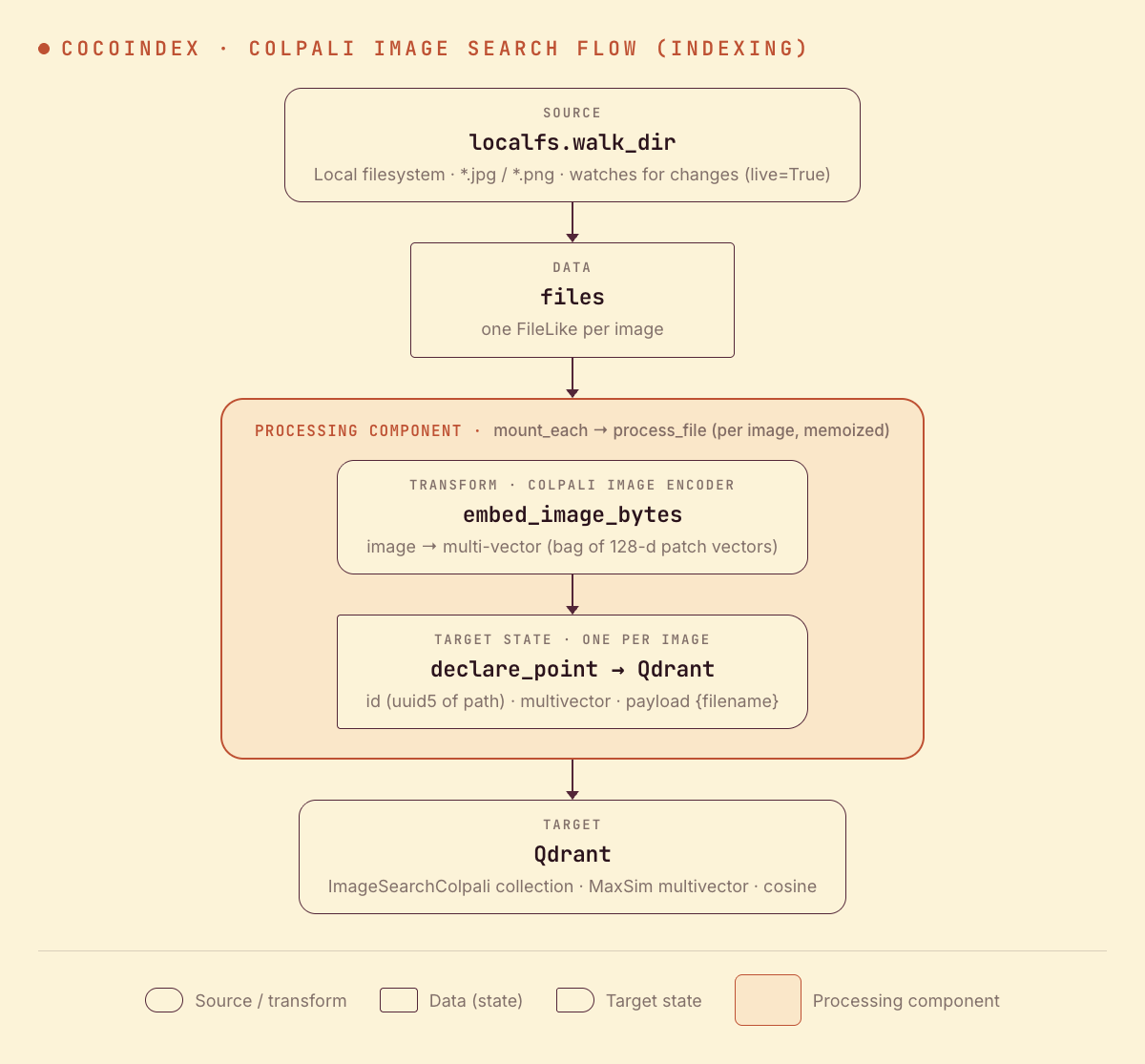
The indexing path is short — there’s no text to chunk, just one multi-vector embedding per image:
- Read image files from a local directory (live).
- Embed each image with ColPali into a multi-vector — a list of 128-d patch vectors, not one fixed vector.
- Store it in Qdrant (as a point in a MaxSim multivector collection, keyed by a stable id, with the filename in the payload).
You declare the transformation logic with native Python, without worrying about how updates propagate. Think: target_state = transformation(source_state).
Multi-vector embeddings: a bag of vectors per image
This is what sets the example apart from its CLIP sibling. CLIP gives you one vector per image; ColPali gives you many — a vector per visual patch — and embeds a text query into the same per-token space. Both indexing and querying use the same model, two different entry points: process_images for the index side, process_queries for the query side.
@functools.cache
def get_colpali() -> tuple[ColPali, ColPaliProcessor, str]:
model = ColPali.from_pretrained(COLPALI_MODEL_NAME) # vidore/colpali-v1.2
processor = ColPaliProcessor.from_pretrained(COLPALI_MODEL_NAME)
device = get_torch_device("auto")
model = model.to(device)
model.eval()
return model, processor, device
def embed_image_bytes(img_bytes: bytes) -> list[list[float]]: # indexing side
model, processor, device = get_colpali()
image = Image.open(io.BytesIO(img_bytes)).convert("RGB")
batch = processor.process_images([image]).to(device)
with torch.no_grad():
embeddings = model(**batch)
return _postprocess_embeddings(embeddings, processor)
def embed_query(text: str) -> list[list[float]]: # query side
model, processor, device = get_colpali()
batch = processor.process_queries(texts=[text]).to(device)
with torch.no_grad():
embeddings = model(**batch)
return _postprocess_embeddings(embeddings, processor)Note the return type: list[list[float]], not list[float]. Each image becomes a list of 128-d patch vectors, and each query becomes a list of 128-d token vectors. _postprocess_embeddings strips the model’s padding so only real patches/tokens survive, and @functools.cache loads the (large) ColPali model once and reuses it for every image and every query.
Setup
-
A running Qdrant:
docker run -d -p 6333:6333 -p 6334:6334 qdrant/qdrant export QDRANT_URL="http://localhost:6334/" -
Install CocoIndex with the ColPali and Qdrant extras, plus the dependencies this example uses:
pip install -U "cocoindex[colpali,qdrant]" torch transformers pillow fastapi "uvicorn[standard]" python-dotenv -
A few images. The example ships an
img/folder (a cat, a dog, an elephant, a giraffe) — or drop your own.jpg/.pngfiles in.
Shared resources: the Qdrant client
The lifespan provides the Qdrant client once at startup, via a context key:
QDRANT_DB = coco.ContextKey[QdrantClient]("image_search_colpali")
@coco.lifespan
async def coco_lifespan(builder: coco.EnvironmentBuilder) -> AsyncIterator[None]:
client = qdrant.create_client(qdrant_url(), prefer_grpc=True)
builder.provide(QDRANT_DB, client)
yieldProcess an image
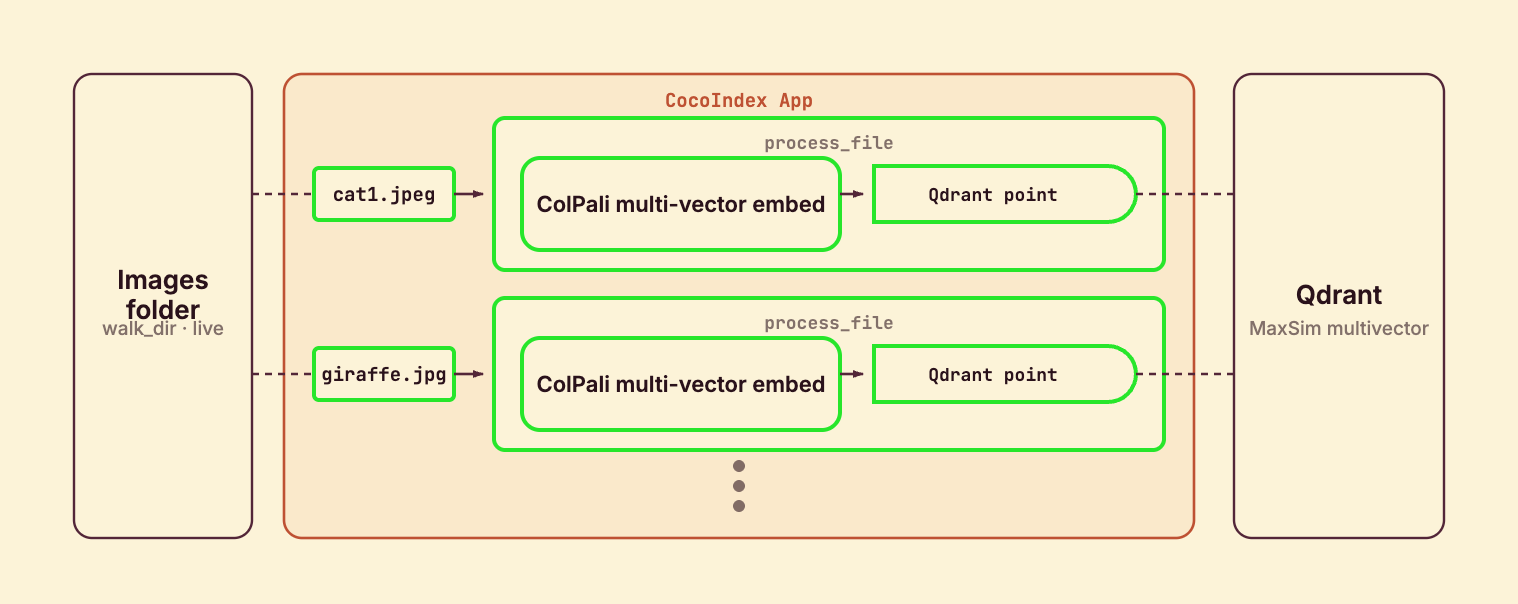
process_file runs once per image: read the bytes, embed with ColPali into a multi-vector, and declare a Qdrant point keyed by a stable id derived from the path, with the filename in the payload. The only difference from the CLIP version is the shape of embedding — a list of patch vectors rather than one vector.
@coco.fn(memo=True)
async def process_file(file: FileLike, target: qdrant.CollectionTarget) -> None:
content = await file.read()
embedding = embed_image_bytes(content) # list[list[float]] — multi-vector
point = qdrant.PointStruct(
id=_image_id(file.file_path.path), # uuid5 of the path — stable
vector=embedding,
payload={"filename": str(file.file_path.path)},
)
target.declare_point(point)@coco.fn(memo=True) makes it incremental: an unchanged image is never re-embedded. Each image runs as its own processing component, so the engine tracks them independently — delete an image and its point is removed from Qdrant automatically. declare_point declares the point as a target state; CocoIndex upserts or deletes to match.
Define the main function
app_main mounts the Qdrant collection — this is where the multi-vector setup lives. The vector schema is wrapped in a MultiVectorSchema, and the collection is configured with multivector_comparator="max_sim" so Qdrant scores points with late interaction. The per-vector dimension comes straight from the model (model.dim, 128 for ColPali), then it walks the image folder and mounts one component per file:
@coco.fn
async def app_main(sourcedir: pathlib.Path) -> None:
model, _, _ = get_colpali()
dim = int(getattr(model, "dim", 128)) # 128 per patch/token vector
target_collection = await qdrant.mount_collection_target(
QDRANT_DB,
collection_name=QDRANT_COLLECTION, # "ImageSearchColpali"
schema=await qdrant.CollectionSchema.create(
vectors=qdrant.QdrantVectorDef(
schema=MultiVectorSchema(
vector_schema=VectorSchema(dtype=np.dtype(np.float32), size=dim)
),
distance="cosine",
multivector_comparator="max_sim", # late-interaction MaxSim
)
),
)
files = localfs.walk_dir(
sourcedir,
recursive=True,
path_matcher=PatternFilePathMatcher(
included_patterns=["**/*.jpg", "**/*.jpeg", "**/*.png"]
),
live=True, # api.py runs the app with live=True
)
await coco.mount_each(process_file, files.items(), target_collection)
app = coco.App(
coco.AppConfig(name="ImageSearchColpaliV1"),
app_main,
sourcedir=pathlib.Path("./img"),
)mount_collection_target creates and manages the Qdrant collection for you — multivector schema, idempotent upserts, and cleanup when an image disappears. Because the per-vector size comes from the model, swapping ColPali variants just works.
Run it as a service
Like the CLIP example, image search runs as a server. api.py is a FastAPI app whose lifespan starts the CocoIndex flow in live mode in the background — it blocks startup until the initial sweep finishes (so the collection is queryable), then keeps watching img/ while it serves requests. There’s no separate “build the index” step.
@asynccontextmanager
async def lifespan(app: FastAPI) -> AsyncIterator[None]:
global _client
async with coco.runtime():
_client = qdrant.create_client(pipeline.qdrant_url(), prefer_grpc=True)
# Start a live update; block until the initial sweep is READY, then run on.
update_handle = pipeline.app.update(live=True)
async for snap in update_handle.watch():
if snap.status is coco.UpdateStatus.READY:
break
update_task = asyncio.create_task(update_handle.result())
try:
yield
finally:
update_task.cancel()
@app.get("/search")
async def search(q: str, limit: int = 5) -> dict:
query_embedding = pipeline.embed_query(q) # text → ColPali multi-vector
results = pipeline._qdrant_search(_client, pipeline.QDRANT_COLLECTION, query_embedding, limit)
return {"results": [{"filename": (r.payload or {}).get("filename"), "score": r.score} for r in results]}_qdrant_search calls Qdrant’s query_points with the query’s bag of vectors — Qdrant handles the MaxSim scoring against each point’s patch vectors. Start the server, then the frontend:
python -m uvicorn api:app --reload --host 0.0.0.0 --port 8000
cd frontend && npm install && npm run dev # http://localhost:5173The React app posts your query to /search, which embeds the text into ColPali’s per-token space and runs a MaxSim search in Qdrant — the match is by meaning, patch by patch, never by metadata.
Incremental updates
Because the flow runs live inside the server, the index tracks the folder with no extra work from you:
- Add an image —
process_fileruns once for it, embeds it into a multi-vector, and upserts one Qdrant point. It’s searchable within a second. - Replace an image — same id (derived from the path), new bag of vectors; the point is updated in place.
- Delete an image — its component disappears and the point is removed from Qdrant.
- Restart the server — the initial sweep reconciles against what’s already in Qdrant and re-embeds nothing that’s unchanged.
Swap the ColPali model and CocoIndex re-embeds everything against the new space; leave it alone and a restart is nearly free.
Run it
The full, runnable example is in the CocoIndex repo: examples/image_search_colpali. For the lighter, single-vector version that fits more images in memory and indexes faster, see the CLIP image search example; for the text equivalent, see Semantic Search 101.
Got a document-image archive, a product catalog, or a screenshot pile you want to search by meaning? Come tell us on Discord — and if this was useful, star CocoIndex on GitHub.